







论文名称:Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild
下载链接:https://arxiv.org/abs/1911.11130
代码链接:https://github.com/elliottwu/unsup3d
Demo中用到的预训练模型(pretrained_celeba)下载速度慢,我已经上传到CSDN资源中,附链接。
1. Introduction

本文,作者研究的是从2d图像生成3d图像的过程。在此问题上,作者认为有两个有挑战性的状况,第一是如何从没有任何标注信息的图像中来对三维图像进行重建。第二是如何重建任意视角拍摄的图像,即论文中所说的"use an unconstrained collection of single-view images"。
为解决图像的三维重建问题,作者使用自编码器(autoencoder)将图像分解为反照度(albedo)、深度(depth)、光照(illumination)、视点(viewpoint),这四个维度。并且,在这四个维度上,没有给定任何的监督信息。
但是,作者认为,如果没有更进一步的假设(assumptions),上面的分解方法是ill-posed问题。
因此,作者使用对称性(symmetric),作为上述分解过程的一个假定(assumption)。
However,作者又提出某些特定目标实例并不是完全对称的,无论在形状或者是外观上。
So,为解决上述的非完全对称问题,论文中提出两种方式:1)直接对光照(illumination)进行建模。通过这种方式,模型就可以利用illumination作为一个额外的线索,来恢复形状(shape)。2)对模型进行扩充(augment)。
综合上述步骤,就可以得到一个稠密地图(dense map),并且此地图包含概率可能性(probability),此概率表示的是某个像素在图像上有一个对称像素(symmetric counterpart)的概率。
2. Related Work
在基于图像的3D重建算法中,必须考虑的三个方面是:
1)which information is used;
2)which assumptions are made;
3)what the output is.
作者也将从这三个方面出发,来对本文算法和之前的算法进行比较。
Structure from Motion.
Shape from X.
Category-specific reconstruction.
本节最后一段,作者指出,论文算法需要一个可辨识的渲染器(differentiable renderer),使用的是文献“Hiroharu Kato, Yoshitaka Ushiku, and Tatsuya Harada. Neural 3d mesh renderer. In Proc. CVPR, 2018. 3, 11”中提到的。
3. Method
算法学习的过程:给一个特定类别的非受限的图像,例如人脸,算法学习的目标是学习一个模型Φ,将输入图像分解为四项,即3d shape、albedo、illumination、viewpoint。
算法学习的目标:因为只有输入的原始图像数据,所以算法学习的目标函数的重建性(reconstructive),即如何通过上面分解的四个因子,来对输入图像进行一个重建。
作者又指出,很多目标类别是双边对称的(bilaterally symmetric)。但是,由于一些shape deformation、asymmetric albedo和asymmetric illumination(非对称光照),目标的外观并不是完全对称的。
因此,为了解决非完全对称的问题,同上述的一样,作者提出辨识非对称性的两种方式:第一就是对光照的非对称性进行建模。第二是对图像的每个像素,判断它在图像上有对称像素的概率(即上图的σ和σ')。
下面作者分四个部分来介绍该算法的具体执行过程:3.1介绍图像几何自编码器(photo-geometric autoencoder),大概是讲如何用自编码器从输入图像构造出四种类型的输出。3.2介绍的是如何利用对称性来建模。3.3介绍了具体的算术执行细节。最后一部分3.4姐介绍的是感知损失(perceptural loss)。
3.1 Photo-geometric autoencoding

通过函数Φ,将输入图像I学习出四种表达,分别代表depth、albedo(反照度)、viewpoint(视点)、light direction(光照方向)。
根据上面的四个因子来重建图像分两步,第一步是利用光照函数Λ,在viewpoint w = 0的情况下,利用a、l、d这几个变量,先生成一个重建图像。w(the viewpoint)代表了标准view和输入图像的view之间的变换(transformation)。然后,反投影函数Π来模拟viewpoint变化,生成最终的重建图像![]() 。并且,学习的重建损失函数是鼓励
。并且,学习的重建损失函数是鼓励![]() 的。
的。
![]()
其中,Λ是lighting function,是在viewpoint w = 0的情况下,利用a、l、d这几个变量,先生成一个重建图像。w(the viewpoint)代表了标准view和输入图像的view之间的变换(transformation)。
Π,模拟视点变化,在d(depth)和Λ(a,d, l)的基础上,重建输入图像,得到![]() 。
。
3.2 Probably symmetric objects(对称目标的可能性?)
作者指出,如果要利用对称性来对目标进行3D重建,那么必须要弄清楚输入图像上到底有哪些对称的像素点。
这里作者隐式地给出了一个假定:深度(depth)和反照度(albedo)相对于一个固定的垂直面(a fixed vertical plane)是对称的。这种假定,带来的一个明显的好处是,可以帮助模型寻找一个规范视角(‘canonical view’),这个规范视角对于重建任务又是非常重要的。
具体做法:
输入图![]() ,对其在水平轴(horizontal axis,选择的任意的但是要固定)进行flips操作,
,对其在水平轴(horizontal axis,选择的任意的但是要固定)进行flips操作,
得到![]()
![]() 。并且令
。并且令![]() 。
。
下一步的通常做法是将这些限制加到损失函数里面去,但是作者认为这种做法很难去平衡(difficult to balance)。
所以,作者选择从翻转的depth和albedo图像中,获取第二个重建![]() :
:
![]()
然后,新定义的重建损失对两个目标进行激励![]() ,因为这两个损失是对称的(commensurate),所以它很容易去平衡和共同训练。最重要的是,这种方式对于获取像素的对称概率(symmetry probabilistically)非常有帮助。
,因为这两个损失是对称的(commensurate),所以它很容易去平衡和共同训练。最重要的是,这种方式对于获取像素的对称概率(symmetry probabilistically)非常有帮助。
下面,作者给出从原图像![]() 到重建图像
到重建图像![]() 的损失函数:
的损失函数:
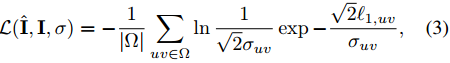
其中,![]() 是uv坐标像素上的L1距离,
是uv坐标像素上的L1距离,![]() 是置信度图(confidence map),此置信度也是通过网络模型
是置信度图(confidence map),此置信度也是通过网络模型![]() 推理得到的,表示的是模型的任意不确定性(aleatoric uncertainty???)。
推理得到的,表示的是模型的任意不确定性(aleatoric uncertainty???)。
损失函数(3)可理解为negative log-likelihood,表示的是重建冗余上的因子化拉普拉斯分布???优化似然函数的过程,就是调整模型的过程,最终可以使模型学得一个有意义的confidence map[32]。
作者指出,对不确定性建模是非常有用的,在论文提出的算法中,对称性重建(symmetric reconstruction)是非常重要的,损失函数的定义方式跟(3)一样,即![]() 。这个也是用模型
。这个也是用模型![]() 来估计的,同时,这会生成第二个置信度图(confidence map)
来估计的,同时,这会生成第二个置信度图(confidence map)![]() ,这个置信度图决定的是图像的哪部分是非对称的。例如,某些人的头发是非对称的,
,这个置信度图决定的是图像的哪部分是非对称的。例如,某些人的头发是非对称的,![]() 可以给头发区域一个更高的重建不确定性,即在这个头发区域上,对称性假设不再满足。
可以给头发区域一个更高的重建不确定性,即在这个头发区域上,对称性假设不再满足。
总之,学习目标是两个重建损失的结合:
![]()
3.3 Image formation model
本小节介绍的是公式(1)中使用的函数Π和Λ细节。
令P = (Px, Py, Pz)是相机坐标系下的一个3D表达,那么往像素坐标系p = (u, v, 1)上的映射,变换公式为:
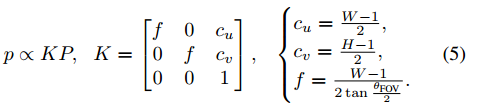
作者在图像上的目标周围进行了目标切割,所以就假定相机视场角(FOV)≈10°,并且假定相机到目标的标称距离(nominal distance)大约是1m。
深度图(depth)![]() ,表示在每个像素点上的深度信息,它可以从公式(5)求逆得到,即
,表示在每个像素点上的深度信息,它可以从公式(5)求逆得到,即![]() 。
。
视点(viewpoint)![]() 代表的是欧式变换
代表的是欧式变换![]() ,其中SE(3)代表旋转(R)加上平移(T)变换。
,其中SE(3)代表旋转(R)加上平移(T)变换。
(R, T)变换就是将3D点从一个标准的视角(canonical view)的像素点(u, v)变换到一个真正的视角(actual view,此视角应该是图像本来的角度)的像素点(u', v'),变换公式为:
![]()
最终,反投影函数Π是以深度d和视点w作为输入,并且结合变换到标准图像(canonical image)![]() 上,去获得actual image,即
上,去获得actual image,即![]()
![]() ,当
,当![]() ,其中
,其中![]() 。
。
3.4 Perceptual loss
作者指出等式(3)的L1损失是对集合缺陷非常敏感,并且会导致模糊的(blurry)重建。因此,作者这里加入了一个感知损失项(perceptual loss)来减轻这个问题。
所得的感知损失的形式为:
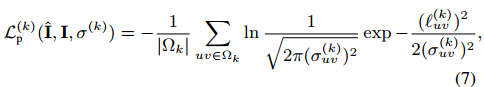















 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









