







2024.11.20
I hear and I forget; I see and I know; I do and I understand
1.什么是实体?
通义千问解释:
在知识图谱中,实体是表示现实世界中具体或抽象事物的基本单元。实体可以是具体的对象、概念、事件、地点、人物等。每个实体在知识图谱中通常都有一个唯一的标识符(ID),并且可以具有多个属性和与其他实体的关系。
在我看来:所有你关注的内容都可以定义为实体。
比如我在新闻领域中,关注时间、地点、人物;在医疗领域中,我关注症状、药物、科室、疾病原因、医疗手段;在汽车故障领域中,我关注故障现象、故障原因、维修手段;
2.实体抽取的本质?
实体抽取(NER)的本质就是从输入文本中提取出用户感兴趣的部分,从这个意义上来说和关键词提取有一些相同点,但区别是关键词提取只需要把词给提取出来,而实体抽取还关注提取出来的词或句的类型,其实质包含两个子任务:实体边界检测和实体类别识别,任何一部分出错,则会提取出错误的实体。除此外,还容易发生错误识别、漏识别的问题。
eg:
输入:汽车在踩刹车时发动机[Part]那个位置出现不规则哄哄声音[Trouble]
注:黑体为期望识别的实体,[]为对应的实体类型
- 错误示例:
汽车在踩刹车[PART]时发动机那个位置[PART]出现不规则哄哄声音[Trouble]
3.实体抽取的难点?
在处理以下几个场景时存在难点:
- 嵌套:即一个实体中还包含了其它实体,分为组间嵌套,嵌套的为不同类型,(eg,"发动机哄哄响"这个故障现象还嵌套了发动机这个部件); 组内嵌套,嵌套的为同一类型(eg,左车门车窗玻璃开关);
- 不连续:即一个实体被分割成多段,需要拼接后才能称为一个完成的实体。eg。左车门、右车门的车窗玻璃里面的”左车门的车窗玻璃“
- 歧义:即一词多义。eg。刹车(踩刹车异响和刹车时异响)
- 新词识别(OOV):即未出现在训练数据集中的词
- 非正式:包含口语化、简化、谐音、错别字等,eg:发动鸡、三元(三元催化器)、搭铁
整体上,中文的NER比英文的要更难,因为中文的歧义性和简化表达更加广泛存在,同时英文可以通过空格进行分词(在边界识别上就简单了一些),而中文无法明确边界,句子中不同的分词方式对实体抽取的结果影响非常大。
eg:南京市/长江大桥,南京/市长/江大桥
因此在中文的NER任务中,通常是基于字粒度进行实体抽取。
4.实体抽取的方法?
(1)基于词典+规则的方法
一般来说,就是基于自定义词典+分词+词性标注完成实体抽取。典型工具有:jieba、LAC、pyLTP、Spacy
优点:简单上手快,抽取准确性高,前期开发成本低;
缺点:无法识别词典中未出现的词,即OOV问题
(2)基于统计学习的方法:
典型的模型为HMM、CRF、MEMM,这些都是处理序列标注任务的常见模型。基于CRF的BiLSTM-CRF是2018年前的主流方法。
优点:识别性能更好
缺点:需要标注数据集,人工成本高
(3)基于预训练模型的方法
一个简单的思路就是就是Bert+序列解码器的方式,使用参数冻结或者微调后的Bert生成文本向量,然后输入给softmax或者crf进行解码,获取标签,然后解析标签得到实体。
在Bert时代,针对实体抽取的难点,还诞生了很多其它优秀的思路,闪耀着智慧的光芒! 💡
可参考:
https://zhuanlan.zhihu.com/p/469879435
https://zhuanlan.zhihu.com/p/586888321
具体的有以下思路:
- 序列标注:如BIO、BMES,原生的bert-CRF无法处理嵌套和不连续问题,因为一个token只能预测一个标签。可以采用分层CRF+自定义标签的方法进行改进:一种实体类型就创建一个CRF解码层,通过多层CRF实现多个标签,同时自定义的多功能了的N和I标签来解决嵌套和不连续问题

-
矩阵标注:一种实体类型就创建一个head矩阵,矩阵中的每个值都关联对应的头token和尾token(相当于只用一个实体的首尾token来表示它)。这是一个非常稀疏的矩阵(1、2为正样本、0为负样本),样本非常不均衡,因此要采用负采样。
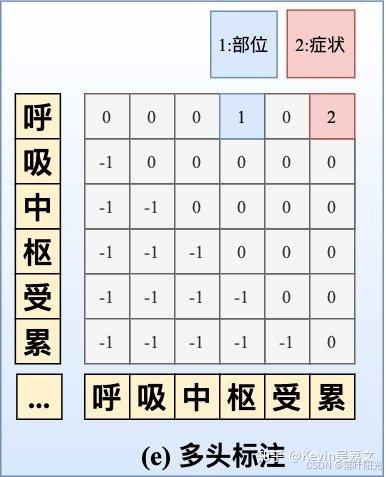
-
指针标注:用两个指针遍历文本获取所有的span可能,然后判断span是否为某种实体。如果有 n 个实体类别,需要做 2 次 n 分类任务;(Bert时代的主流)
-
阅读理解:用提问的方式来抽取实体。一种实体类型就需要提一次问。

优点:在所有NER方法中性能最好
缺点:部署成本更高,同时也需要标注大量数据集训练,耗时
(4)基于生成式模型的方法
在Bert时代就诞生了阅读理解和统一信息抽取进行NER的方式,在大模型时代,有更强的理解不去标注数据集和训练模型了,因为在很多场景下,大模型的零样本或者少样本的方式都能表现出不错的效果。此时实体抽取的任务就变成了编写实体抽取Prompt。
eg:
请从以下文本中抽取所有的实体,并按照实体类型进行分类:
{输入文本}
例如:
文本:张三在北京大学读书,他的专业是计算机科学。
实体:
- 人物:张三
- 组织:北京大学
- 学科:计算机科学
- 地点:北京
请按照以下格式输出实体:
- [实体类型]:[实体名称]
- [实体类型]:[实体名称]
优点:不用标注数据和训练了,非常省事。
缺点:在细分领域上无法准确识别出一些领域专业词汇,此时可考虑微调LLM或者考虑使用bert类方法

















 1254
1254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









