







知识图谱嵌入总结
2024.12.25首发
2024.12.30更新
2025.1.1更新
2025.1.3更新
2025.1.6更新
本文回答以下问题:
-
知识图谱嵌入是什么,和图嵌入的区别?
-
什么是语义信息和结构信息,模型如何同时保留这两种信息?
-
知识图谱嵌入有哪些难点、方法和工具
1.概念

知识图谱嵌入(Knowledge Graph Embedding, KGE)是指将知识图谱中的实体和关系映射到低维连续向量空间的过程。这一过程旨在保留原始知识图谱中的结构信息和语义信息,以便于后续的机器学习任务如链接预测、实体分类等。
注1:KGE得到的向量不是通用的,只合适一些特定的任务:
(1)链接预测(最适合):
原因:KGE模型通过学习实体和关系的低维表示,能够捕捉到实体之间的潜在关联模式。因此,它们非常适合用于预测知识图谱中缺失的链接或新出现的关系。
(2)实体分类/聚类:
原因:由于KGE保留了实体间的结构信息,相同类别或相似类型的实体在嵌入空间中往往更接近。这使得KGE向量可以直接用于分类或聚类算法,以识别具有相似特征的实体群组。
(3)推荐系统:
原因:在推荐场景中,用户和物品可以被建模为知识图谱中的实体,并且它们之间的交互(如购买、评分等)作为关系。利用KGE可以获得更好的个性化推荐结果,因为它不仅可以基于直接的用户-物品互动,还可以考虑间接的多跳关系。
(4)问答系统(Q&A):
原因:对于需要从结构化数据中检索答案的问题,KGE可以帮助快速定位相关实体和事实,从而提高问答系统的准确性和效率。
(5)路径查询与推理:
原因:KGE模型通常能很好地处理多步推理问题,即通过一系列中间实体来推断两个实体之间的关系。这对于执行复杂的路径查询非常有用。
补充一段话,我觉得总结的很好,更能理解KGE在做什么
来自:https://zhuanlan.zhihu.com/p/354867179

什么是结构信息和语义信息?
结构信息
**结构信息指的是数据内部的组织方式和关系模式。**它通常涉及数据元素之间的连接、排列和布局。结构信息对于理解数据的整体框架和组成至关重要。不同类型的数据有不同的结构信息表现形式,对于图而言,其结构信息主要是节点之间的连接方式(边的存在与否)、节点的度(连接的数量)、图的连通性等。
语义信息
**语义信息指的是数据所传达的意义和内容。**它涉及数据元素的含义及其之间的关系。语义信息对于理解数据的实际意义和用途至关重要。同样,不同类型的数据有不同的语义信息表现形式,对于图而言,其语义信息包括节点代表的实体(如人、地点、事物)及其属性,边代表的关系(如朋友、隶属、连接)等。

简言之:结构信息提供了数据的形式,语义信息提供了数据的内容:如去掉图谱中所有节点和关系的属性,只留下一张空图,这个就是这张图的结构信息;将节点和关系的属性填充回去,每个节点和边都有了具体的类别和含义,这个就是这张图的语义信息。两着是相互依存的。
比如KGE和GE本质都是基于图的结构进行嵌入但是他可以学习到一些语义信息,比如在一些任务中我们可以假设:具有相同结构的节点其语义相近。
演变趋势
早期的KGE研究主要集中在结构信息的保留上,但随着技术的发展,越来越多的方法开始重视并尝试融合语义信息。一个好的KGE系统应当能够平衡结构信息和语义信息,既保留了知识图谱的结构特性,又不失其语义含义。
如何同时保留结构信息和语义信息?
- 混合模型: 将结构信息和语义信息结合在一个模型中,例如,在图嵌入中同时考虑节点的属性信息和图的结构信息。
- 多任务学习: 通过多任务学习框架,同时优化多个目标,例如,既考虑节点分类任务(语义信息)又考虑链路预测任务(结构信息)。
- 注意力机制: 在序列数据处理中,使用注意力机制来动态地调整不同部分的重要性,从而同时捕捉结构信息和语义信息。
以下是一些KGE领域中的方式,同时学习结构和语义信息:
-
复杂模型:一些较新的KGE模型(如ComplEx, RotatE)使用复数域或特殊运算(如旋转),这使得它们不仅能更好地模拟对称性和反对称性等结构属性,而且能表达更复杂的语义关系。
-
文本描述:结合实体的文本描述(如Wikipedia摘要)可以增强嵌入的语义丰富度。这种方法通常会利用预训练的语言模型(如BERT)生成文本的向量表示,并将这些表示融入到最终的知识图谱嵌入中。
-
多模态数据:除了结构和文本外,还可以考虑其他形式的数据,如图像、音频等,以提供更加全面的语义上下文。
-
上下文感知:某些高级模型尝试理解实体和关系的具体应用场景,即根据不同的上下文来调整其嵌入表示。这有助于解决一词多义等问题,并且可以在不同场景下正确地解释相同的实体或关系。
关于嵌入和结构信息、语义信息的更全面了解,可以看我的另外一篇总结:https://blog.csdn.net/xiangxiang613/article/details/143798363
2.KGE VS GE(图嵌入)
共同点和区别?
知识图谱嵌入(Knowledge Graph Embedding, KGE)和图嵌入(Graph Embedding, GE)是两个相关但有所区别的概念,它们都涉及到将图结构中的信息映射到低维向量空间中。
(1) 共同点
- 目标:两者的目标都是为了将复杂的图结构数据转换为数值型向量表示,以便于后续的机器学习任务,如分类、聚类、链接预测等。
- 方法论:两种嵌入方法都可能使用相似的技术手段,例如矩阵分解、随机游走、深度学习模型(如图卷积网络GCNs)、以及基于距离或相似度的方法。
(2) 区别
A.知识图谱嵌入(KGE)
- 特定结构:KGE专注于处理知识图谱,这是一种特殊的图结构,其中节点代表实体(如人、地点、事件),边代表这些实体之间的关系(如“出生于”、“位于”)。因此,KGE需要特别考虑如何编码这些语义丰富的三元组(头实体-关系-尾实体)。
- 语义信息:由于知识图谱中的边具有明确的语义含义,**KGE往往更加强调保留这种语义信息。**例如,某些关系可能是对称的、反身的或传递的,而KGE模型需要能够捕捉这些特性。
- 复杂模式:KGE必须处理更加复杂的模式,如多跳推理(即通过多个中间实体进行推断)和关系的组合效应(如“朋友的朋友可能是朋友”)。
- 应用领域:KGE广泛应用于推荐系统、问答系统、自然语言处理等领域,特别是在涉及大量结构化事实库的情况下。
B.图嵌入(GE)

- 通用性:**GE适用于各种类型的图结构,不限于知识图谱。**它可以用于社交网络、生物网络、化学分子结构等多种场景。在这些情况下,边不一定有明确的语义标签,更多地关注节点之间的连接模式。
- 结构优先:相较于KGE,GE通常更侧重于保持图的整体拓扑结构特征,如节点间的邻接关系、社区结构等。它可能不强调具体的关系类型或语义信息。
- 算法多样性:GE涵盖了从浅层方法(如DeepWalk, node2vec)到深层方法(如图神经网络GNNs)的一系列技术。这些方法可以适应不同类型的任务需求,如节点分类、链接预测、图分类等。
- 应用场景:GE的应用范围非常广泛,包括但不限于社交分析、推荐系统、生物信息学、网络安全等领域。它可以帮助揭示隐藏在网络结构背后的信息,并支持基于网络的决策过程。
深入理解:
- GE默认是针对同质图(节点和边都只有一种类型,如社区网络)提出的,其核心关注点在于对节点进行嵌入,只考虑保留图的结构信息和局部连接信息(节点之间的连接信息),强调的是同质性和结构性的平衡。若两个节点的向量相似,则表示其结构更相似或者距离更近。
同质性:结构相同的节点其embedding更相似
结构性:距离更近的节点其embedding更相似
- KGE是针对异质图的(知识图谱就是),强调针对语义信息进行嵌入(结构信息只使用了一跳信息,比较局限,对比GNN,其可以使用多跳关系建模高阶结构信息),将节点和关系同时映射到语义空间,使语义相似的节点更接近,换句话说,若两个节点的向量相似,则表示它们的语义更相似或者在语义空间中的距离更近。
- KGE和GE都能处理一些相同的任务(如链接预测和节点分类),但背后的逻辑是完全不同的,虽然表面上看都是基于节点相似度,但GE和KGE的节点相似度的含义是不一样的(上面讲了),所以两者的适合的任务场景是不同的。
- KGE的局限性:KGE没有想象中那么强大,无论是基于翻译距离还是语义匹配的KGE算法,其都是针对三元组打分提出的(给定一个三元组,判断其成立的置信度,换个角度,可以理解为图谱补全),这种训练目标,导致其只能学习到局部信息(一阶结构信息,本质上没有用到节点和关系的属性信息,如节点名称),也学习不到图的全局信息。只有扩展链路,才能学习到高阶的结构和语义信息,这方面,GE通过随机游走可以增加连通信息,GNN通过消息传递可以学习多跳领域信息。
- 从理论设计上来说,GNN优于GE,GE优于KGE。
GE的方法可否用于KGE?
图嵌入(Graph Embedding, GE)的方法确实可以用来处理知识图谱(Knowledge Graph, KG),但需要根据知识图谱的特点进行适当的调整或增强。这是因为知识图谱不仅仅是普通的图结构,它还包含了丰富的语义信息和复杂的关系模式。以下是GE方法应用于KG时的考虑因素及可能的调整:
(1)直接应用
-
节点嵌入:**对于只关注实体之间连接模式的任务,可以直接使用标准的GE方法,**如DeepWalk、node2vec等,来获取节点(即实体)的嵌入表示。这些方法通过随机游走生成节点序列,并利用Skip-gram模型学习节点向量。
只关注实体之间连接模式的任务: 1. 社区检测(Community Detection) 描述:识别网络中的紧密联系群体或社区。 特点:不关心具体的节点或边类型,只需要知道哪些节点相互连接。通过分析节点之间的连接模式,可以发现具有相似特性的节点群组。 2. 节点分类(Node Classification) 描述:预测未知标签节点的类别。 特点:假设同一类别的节点倾向于与相同类别的其他节点相连。因此,即使不了解具体的节点属性或边类型,也可以基于连接模式来进行分类。 3. 链接预测(Link Prediction) 描述:预测两个节点之间是否存在未观察到的链接。 特点:重点在于根据现有连接模式推断潜在的关系。例如,在社交网络中预测好友关系,或者在蛋白质交互网络中预测新的交互对。 4. 异常检测(Anomaly Detection) 描述:识别网络中不符合正常连接模式的节点或边。 特点:不需要了解具体的节点或边类型,只需识别出那些偏离常规连接模式的元素。例如,在网络安全领域,检测异常的流量模式或恶意活动。 5. 推荐系统(Recommendation Systems) 描述:为用户推荐他们可能感兴趣的物品。 特点:利用用户和物品之间的交互历史(如购买、评分),而不需要深入了解用户或物品的具体属性。通过分析用户-物品网络中的连接模式,可以找到相似用户的偏好,并据此进行个性化推荐。 6. 影响力传播(Influence Propagation) 描述:研究信息或行为在网络中的传播路径。 特点:关注节点之间的连接如何影响信息的流动。例如,在社交媒体平台上追踪某个话题或趋势是如何从一个用户传播到另一个用户的。 7. 网络可视化(Network Visualization) 描述:将复杂网络以直观的方式呈现出来。 特点:虽然最终的可视化可能包含一些语义信息,但其核心是根据节点间的连接模式来布局和展示网络结构。 -
图神经网络(GNNs):GNN及其变体(如GCNs、GATs)可以通过消息传递机制捕捉局部邻域的信息,适用于知识图谱中的实体分类、链接预测等任务。然而,标准的GNN通常不考虑边的类型(只适合处理同质图),这在KG中是至关重要的。
Q:标准的GNN通常不考虑边的类型,可用于进行KGE吗,若可用,和KGE方法相比有什么优缺点? (1)标准GNN用于KGE的可能性 节点特征学习:即使不考虑边的类型,标准GNN仍然能够有效地从节点的邻域结构中学习到有用的特征表示。对于某些简单或同质的知识图谱,这种能力可能已经足够。 消息传递机制:GNN中的消息传递机制可以捕捉局部邻域的信息,这对于实体分类、链接预测等任务是有益的。通过多层传播,它还可以处理多跳关系。 (2)优点 灵活性:GNN架构相对灵活,易于扩展以适应不同类型的任务需求。例如,可以通过添加额外的层或改变激活函数来改进模型性能。 泛化能力:由于GNN是基于图结构的学习框架,因此它具有良好的泛化能力,能够在不同类型的图数据上表现良好。 统一框架:使用GNN可以提供一个统一的学习框架,适用于多种图相关的任务,包括但不限于KGE。这意味着可以更容易地共享代码和模型组件,提高开发效率。 (3)缺点 忽视关系多样性:标准GNN未能区分不同的边类型,这对需要精细建模复杂语义关系的知识图谱来说是一个重大限制。KG中不同类型的边往往携带了丰富的语义信息,忽略这些信息可能导致嵌入质量下降。 难以处理复杂模式:如前所述,KG中的关系可能是复杂的,包括组合关系或多跳关系。标准GNN可能无法充分捕捉这些高级模式,特别是在没有特别针对KG优化的情况下。 计算资源消耗:虽然GNN可以在理论上处理任意大小的图,但在实际应用中,特别是面对大型KG时,可能会面临计算资源的挑战,比如内存占用大、训练时间长等问题。 (4)和KGE方法相比 优势: 通用性:GNN作为更通用的工具,不仅可以处理KG,还可以轻松迁移至其他类型的图数据任务。 可扩展性:随着新研究的发展,GNN不断引入新的改进(如R-GCN, GAT等),使其逐渐具备了处理KG的能力,同时保持了原有的灵活性和泛化能力。 劣势: 针对性不足:相比于专门为KG设计的方法(如TransE, DistMult, ComplEx等),未经优化的标准GNN在处理KG时可能不如后者精准,尤其是在保留语义信息方面。 复杂关系处理能力弱:KGE方法通常会特别考虑KG中常见的对称性、反身性、传递性等复杂关系模式,而标准GNN在这方面可能表现较弱。
注:GNN的本质其实是表示学习,而不是常规的embedding,这个后面单开一篇文章进行总结
(2)针对KG的调整与增强
- 关系感知:
- 在KG中,不同的边代表不同类型的关系,因此需要采用能够区分边类型的嵌入方法。例如,R-GCN(Relational Graph Convolutional Networks)允许为每种关系类型定义特定的权重矩阵,从而更好地建模多关系数据。
- 复合关系:
- KG中的关系可能是复杂的,包括组合关系或多跳关系。为了捕捉这些特性,可以引入路径推理或者基于注意力机制的方法,如TransE、DistMult等KGE模型,它们专门为KG设计,能够有效处理这种复杂性。
- 语义丰富度:
- 知识图谱中的实体和关系往往附带文本描述或其他形式的元数据。结合这些额外信息可以增强嵌入的质量。例如,可以将预训练的语言模型(如BERT)生成的文本表示融合到节点或边的特征中。
- 异构信息网络(HIN):
- 如果KG包含多种类型的节点和边,则可以视为一个异构信息网络。针对这种情况,可以使用专门设计的HIN嵌入方法,如MetaPath2Vec、HERec等,来同时考虑不同类型的节点和边。
- 负采样策略:
- 在KG中,正样本(已知的事实)通常是稀疏的,而负样本(未知或错误的事实)几乎是无限的。因此,有效的负采样策略对于训练过程至关重要。一些KGE方法提出了特别适合KG的负采样技术,以提高模型性能。
KGE和GE的局限性(2024.12.29新增)
知识图谱嵌入(Knowledge Graph Embedding, KGE)和图嵌入(Graph Embedding, GE)虽然在处理结构化数据方面非常有效,但它们也各自存在一些局限性:
知识图谱嵌入(KGE)的局限性
-
关系类型有限:大多数KGE方法假设所有关系都是二元的(即一个主体和一个客体之间的关系),这限制了它们处理更复杂的关系类型的能力,如n元关系或多对多关系。
-
静态假设:许多KGE模型是基于静态图构建的,这意味着它们不擅长处理随时间变化的知识图谱。对于动态更新的图谱,这些模型需要重新训练或采用增量学习策略。
-
稀疏性问题:知识图谱通常是非常稀疏的,即大部分可能的实体-关系对并不存在于图中。这种稀疏性可能导致模型难以泛化到未见过的实体或关系上。
-
复杂度与计算成本:随着图谱规模的增长,训练和推理的计算复杂度也会显著增加,这对硬件资源提出了更高要求。
-
难以捕捉高阶模式:一些简单的KGE模型可能无法很好地捕捉到复杂的高阶模式或者路径依赖性,尽管有些改进模型如RotatE尝试解决这个问题。
图嵌入(GE)的局限性
-
结构信息损失:某些GE方法,特别是那些基于随机游走的方法,在将节点映射到低维空间时可能会丢失部分原始图中的结构信息。
-
超参数敏感:GE模型往往包含多个超参数,例如步长、窗口大小等,这些参数的选择对最终结果有很大影响,选择不当可能导致性能不佳。
-
难以处理异质信息网络:当涉及到具有不同类型节点和边的异质信息网络时,标准GE方法可能表现不佳,因为它们通常假定图是同质的。
-
缺乏语义理解:与KGE不同,GE主要关注保持图的拓扑结构而非节点间的关系语义,因此在涉及具体领域知识的任务中可能不如KGE有效。
-
冷启动问题:对于新加入的节点或很少连接的节点,现有的GE技术可能很难生成有效的嵌入表示,因为这些节点缺少足够的上下文信息来训练模型。
尽管KGE和GE都有各自的优点,但它们同样面临挑战。针对上述局限性,研究人员正在探索新的算法和技术,以提高模型的表现力、效率以及适应性。例如,结合深度学习的进展,出现了各种增强版的图神经网络(GNNs),它们能够在一定程度上缓解这些问题。
3.难点
-
稀疏性和不完全性:现实世界中的知识图谱往往是不完整的,许多事实并未被记录,这使得模型难以准确地学习实体之间的关系。
-
复杂的关系模式:知识图谱中存在各种复杂的关系模式,例如对称性、反身性、传递性等,这些都增加了学习的难度。
1. 对称性(Symmetry) 定义:如果关系R是A到B的关系,那么它也是B到A的关系。 例子: 友谊关系:“张三是李四的朋友”意味着“李四是张三的朋友”。 地理位置相邻:“北京与天津相邻”意味着“天津与北京相邻”。 2. 反身性(Reflexivity) 定义:每个实体都与自己有某种特定关系。 例子: 等价关系:“任何物体都等于自身”,即对于所有x,x = x。 某些属性关系:“每个人都是自己的父母的孩子”。 3. 传递性(Transitivity) 定义:如果A与B之间存在关系R,并且B与C之间也存在相同的关系R,则A与C之间也应该存在关系R。 例子: 继承关系:“如果A是B的父亲,而B是C的父亲,那么A是C的祖父”。 数学中的大小比较:“如果a > b且b > c,那么a > c”。 4. 反对称性(Anti-symmetry) 定义:如果A与B之间存在关系R,那么除非A和B是同一个实体,否则B与A之间不应该存在相同的关系R。 例子: 父子关系:“如果A是B的父亲,那么B不可能是A的父亲”。 5. 非对称性(Asymmetry) 定义:如果A与B之间存在关系R,则B与A之间一定不存在相同的关系R。 例子: 杀害关系:“如果A杀害了B,那么B不能同时杀害A”。 6. 函数性(Functional) 定义:一个实体只能有一个目标实体与之相关联。 例子: 生日关系:“一个人只有一个生日”。 7. 逆函数性(Inverse Functional) 定义:一个目标实体只能有一个源实体与之关联。 例子: 社会安全号码(SSN):“一个有效的社会安全号码只属于一个人”。 8. 多对多关系(Many-to-Many) 定义:多个实体可以同时与多个其他实体有关联。 例子: 演员与电影:“一名演员可以出演多部电影,一部电影也可以有多名演员参与”。 -
计算资源需求:对于大型的知识图谱,训练嵌入模型需要大量的计算资源,包括内存和处理时间。
-
冷启动问题:当有新的实体或关系加入时,可能需要重新训练整个模型以获得良好的嵌入效果。
4.方法
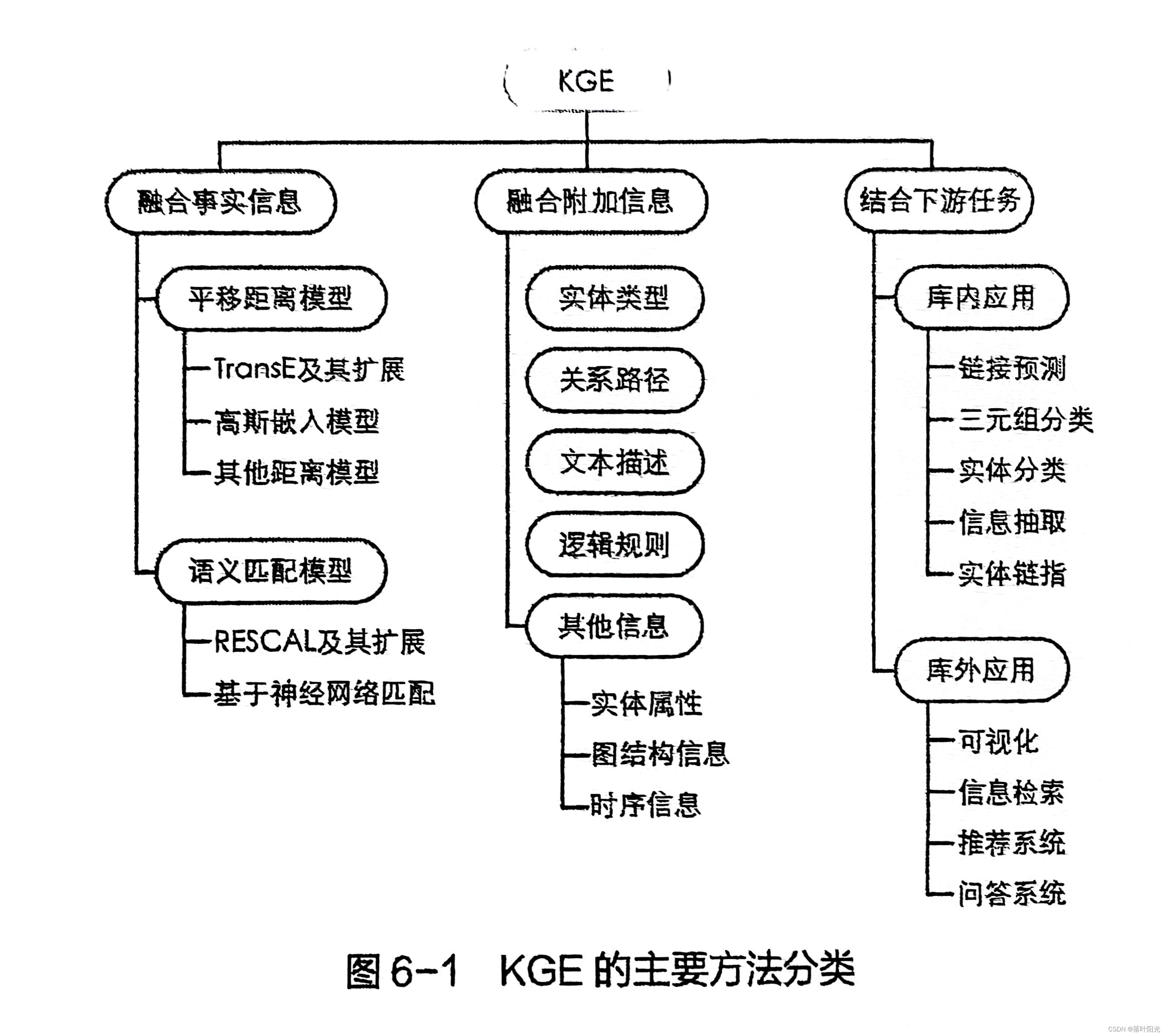
1. 翻译距离模型:
-
优点:
简单直观:通过将关系视为从头实体到尾实体的一种“翻译”,这种模型非常容易理解和实现。
高效训练:由于其简单的数学形式,这些模型通常训练速度较快,并且对大规模数据集有较好的扩展性。
良好的链接预测性能:特别是在处理对称性和反身性等基本关系模式时表现出色。 -
缺点:
难以处理复杂关系:对于更复杂的语义模式,如传递性或多跳推理、多对多和一对多,表现可能不佳。
限制性的假设:例如,TransE假定所有三元组都位于同一低维空间中,这可能会导致某些情况下无法准确表示现实世界的关系。 -
典型模型:
-
TransE: 将头实体与尾实体之间的关系视为一种翻译操作,并最小化正确三元组的得分。
-
TransH, TransR, TransD: 分别引入了超平面、关系特定矩阵以及动态转换来改进TransE的表现。
-
2. 语义匹配模型:
-
优点:
捕捉语义信息:能够更好地建模实体之间的语义相似度,适用于需要理解实体间深层次关联的任务。
支持多种关系模式:如RESCAL可以捕捉二阶关系,DistMult和ComplEx则擅长处理对称/反对称关系以及复数域内的旋转操作。 -
缺点:
计算复杂度较高:相比于翻译距离模型,语义匹配模型往往涉及更多的参数和更复杂的运算,可能导致训练时间增加。
过拟合风险:由于模型结构较为复杂,如果数据量不足或正则化不当,容易出现过拟合现象。 -
典型模型:
-
RESCAL: 使用张量分解的方法来捕捉二阶关系。
-
DistMult, ComplEx: 基于双线性形式的模型,能够处理对称/反对称关系;ComplEx进一步扩展到复数域以增强表达能力。
-
3. 神经网络模型:
-
优点:
强大的表达能力:利用深度学习的强大功能,这类模型可以自动提取特征并适应不同类型的任务需求。
灵活性:可以通过引入卷积层(如ConvE)、注意力机制(如R-GCN中的Attention机制)等组件来增强模型的表现力。
端到端学习:允许直接从原始输入到输出进行优化,减少了手工设计特征的需求。 -
缺点:
更高的资源需求:训练过程通常需要更多的计算资源,包括GPU加速器和较大的内存容量。
解释性较差:相比于基于规则的方法,神经网络模型内部的工作机制相对不透明,难以解释模型决策背后的原因。 -
典型模型:
-
R-GCN (Relational Graph Convolutional Networks): 通过考虑节点间不同类型的边来进行消息传递,适合处理多关系数据。
-
ConvE: 利用卷积神经网络(CNNs)从实体和关系的嵌入中提取特征。
-
4. 混合模型:
-
优点:
结合优势:通过融合不同类型的KGE方法,可以在一定程度上克服单一模型的局限性,获得更好的综合性能。
定制性强:可以根据具体任务需求调整各个组成部分的比例或配置,以达到最优效果。 -
缺点:
复杂度增加:随着模型复杂度的提高,不仅增加了开发难度,也可能带来额外的调试和维护成本。
调参挑战:需要仔细平衡各个部分之间的权重和参数设置,以确保整体性能最优。 -
结合上述两种或多种思想设计的模型,如RotatE,它在复数空间内模拟旋转操作,从而可以表示更复杂的语义关系。
小结
每种类型的KGE模型都有其独特的应用场景和技术特点。选择合适的模型取决于具体的任务需求、可用的数据规模以及计算资源等因素。例如,对于大型KG上的快速链接预测任务,翻译距离模型可能是首选;而对于需要深入理解语义关系的任务,则应考虑语义匹配模型或神经网络模型。混合模型则为那些希望在多个方面取得平衡的应用提供了灵活的选择。
5.工具(2025.1.3更新)
SOTA
基于链接预测任务训练KGE,未开源的不记录
时间:2025.1.3
| 项目 | FB15K-237-MRR | WN18RR-MRR | FB15K-237排名 | WN18RR排名 | 简介 | git地址 | star |
|---|---|---|---|---|---|---|---|
| TransE(基准) | |||||||
| RotateE(基准) | 0.338 | 44 | |||||
| NBFNet | 0.415 | 0.551 | 1 | 7,开源第5 | NeurlPS2021,基于GCN | ||
| C-LMKE | 0.619 | >60 | 6,开源第4 | 2022,基于bert-base | |||
| KERMIT | 0.359 | 0.7 | 24 | 2,开源第1 | 2024,基于LLM | ||
| SimKGC | 0.671 | 47 | 4,开源第2 | ACL2022 | |||
| LERP | 0.62 | >60 | 5,开源第3 | 2023 | |||
| MetaSD | 0.391 | 0.491 | 2 | 21 | EMNLP2022 | ||
综合来看,NBFNet最强!
更多开源项目最新收集
时间:2024.12.30
| 项目 | 支持的模型 | git地址 | star |
|---|---|---|---|
| RotateE | RotatE pRotatE TransE ComplEx DistMult | https://github.com/DeepGraphLearning/KnowledgeGraphEmbedding | 1.3K |
| Knowledge Graph Embeddings | RESCAL [Nickel+. 2011] TransE [Bordes+. 2013] DistMult [Yang+. 2015] HolE [Nicklel+. 2016] This model is equivalent to ComplEx[Hayashi and Shimbo. 2018], and the computation cost of ComplEx is lower than of HolE. ComplEx [Trouillon+. 2016] ANALOGY [Liu+. 2017] This model can be regarded as a hybrid between DistMult and ComplEx. | https://github.com/mana-ysh/knowledge-graph-embeddings?tab=readme-ov-file | 257 |
| KB2E | TransE/H/R、CTransR、PTransE、cluster | https://github.com/thunlp/KB2E | 1.4K |
| libkge | KGE models All models can be used with or without reciprocal relations RESCAL (code, config) TransE (code, config) TransH (code, config) DistMult (code, config) ComplEx (code, config) ConvE (code, config) RelationalTucker3/TuckER (code, config) CP (code, config) SimplE (code, config) RotatE (code, config) Transformer (“No context” model) (code, config) | https://github.com/uma-pi1/kge | 790 |
| scikit-kge | HoIE,其它不明 | https://github.com/mnick/scikit-kge | 473 |
| ConvE | conve distmult complex | https://github.com/TimDettmers/ConvE | 674 |
| Pykg2vec | 见图1 | https://github.com/Sujit-O/pykg2vec | 611 |
| KGEmb | Complex [1] Complex-N3 [2] RotatE (without self-adversarial sampling) [3] CTDecomp [2] TransE [4] MurE [5] RotE [6] RefE [6] AttE [6] RotH [6] RefH [6] AttH [6] | https://github.com/HazyResearch/KGEmb | 250 |
| PyKeen(有更新) | 支持40种模型,见表1 | https://github.com/pykeen/pykeen | 1.7K |
| holographic-embeddings | Holographic Embeddings (HolE) RESCAL TransE TransR ER-MLP | https://github.com/mnick/holographic-embeddings | 172 |
| Knowledge-Grapth-Embedding | TransE [1], TransH [2], TransR [3], TransD [4] | https://github.com/Lapis-Hong/TransE-Knowledge-Graph-Embedding | 79 |
| dge-ke(亚马逊,2020) | 见图2 | https://github.com/awslabs/dgl-ke | 1.3K |
| PairRE(蚂蚁,2020) | https://github.com/ant-research/KnowledgeGraphEmbeddingsViaPairedRelationVectors_PairRE | 77 | |
| MultiKE(2019) | https://github.com/nju-websoft/MultiKE | 115 | |
| entity2rec(2020) | https://github.com/D2KLab/entity2rec | 184 | |
| HittER(微软,2021) | HittER(基于异构Transformers) | https://github.com/microsoft/HittER | 79 |
| DisenKGAT(2021) | https://github.com/junkangwu/DisenKGAT | 55 | |
| InteractE(2020) | https://github.com/malllabiisc/InteractE | 89 | |
| AmpliGraph | TransE, DistMult, ComplEx, HolE (More to come!) | https://github.com/Accenture/AmpliGraph | 2.2K |
| HAKE(2020) | https://github.com/MIRALab-USTC/KGE-HAKE | 251 | |
| KBGAN(2018) | https://github.com/cai-lw/KBGAN | 212 | |
| R-MeN(2020) | |||
| CogKGE(2022) | 见表2 | https://github.com/jinzhuoran/CogKGE | 54 |
| QuatRE(2022) | https://github.com/jinzhuoran/CogKGE | 37 | |
| CAGE(2020) | https://github.com/Heng-xiu/CAGE | 8 | |
| DKRL(2016) | https://github.com/xrb92/DKRL | 232 |
我推荐:pykeen(模型多)、cogKGE(支持Transformer的模型)、PyKG2vec(模型也多)
图1: PyKG2Vec支持的模型
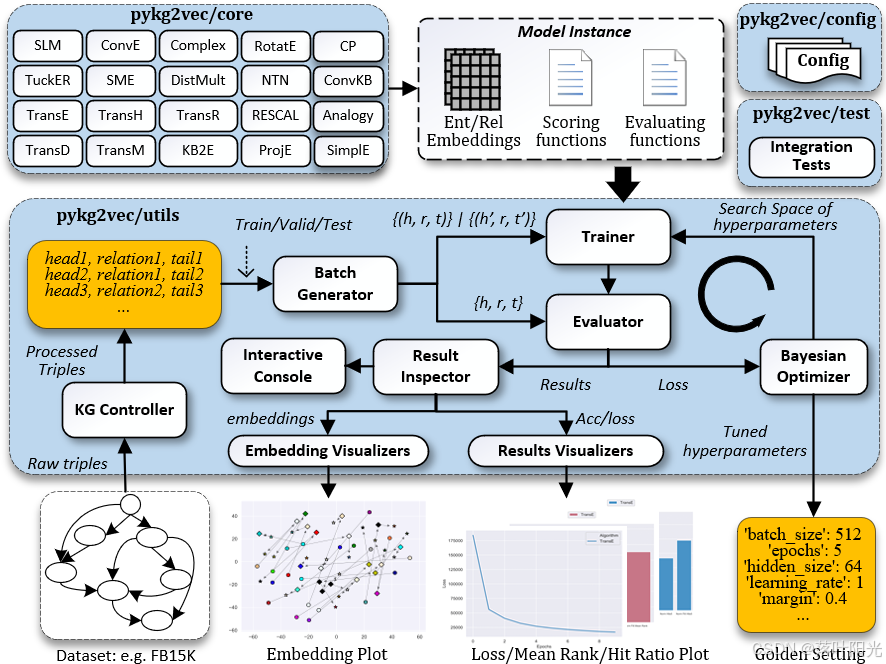
图2:dge-ke支持的模型
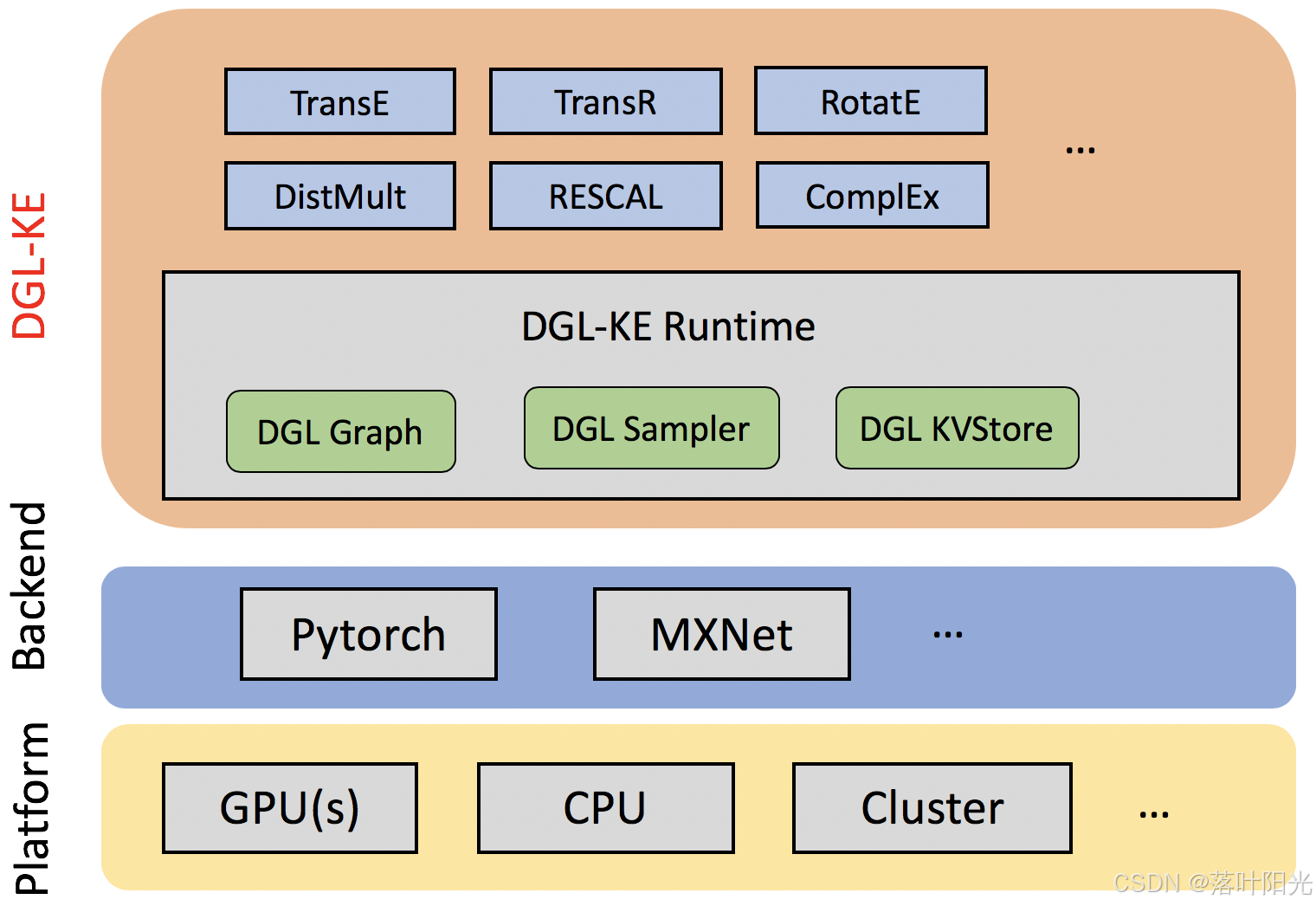
表1:Pykeen支持的模型
表2:cogKGE支持的模型
Translation Distance Models
| Category | Model | Conference | Paper |
|---|---|---|---|
| TransE | NIPS 2013 | Translating embeddings for modeling multi-relational data | 翻译模型 |
| TransH | AAAI 2014 | Knowledge Graph Embedding by Translating on Hyperplanes | |
| TransR | AAAI 2015 | Learning Entity and Relation Embeddings for Knowledge Graph Completion | |
| TransD | ACL 2015 | Knowledge Graph Embedding via Dynamic Mapping Matrix | |
| TransA | AAAI 2015 | TransA: An Adaptive Approach for Knowledge Graph Embedding | |
| BoxE | NIPS 2020 | BoxE: A Box Embedding Model for Knowledge Base Completion | |
| PairRE | ACL 2021 | PairRE: Knowledge Graph Embeddings via Paired Relation Vectorss | |
| RESCAL | ICML 2011 | A Three-Way Model for Collective Learning on Multi-Relational Data | 语义匹配模型 |
| DistMult | ICLR 2015 | Embedding Entities and Relations for Learning and Inference in Knowledge Bases | |
| SimplE | NIPS 2018 | SimplE Embedding for Link Prediction in Knowledge Graphs | |
| TuckER | ACL 2019 | TuckER: Tensor Factorization for Knowledge Graph Completion | |
| RotatE | ICLR 2019 | RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space | |
| R-GCN | ESWC 2018 | Modeling Relational Data with Graph Convolutional Networks | 基于GNN的模型 |
| CompGCN | ICLR 2020 | Composition-based Multi-Relational Graph Convolutional Networks | |
| HittER | EMNLP 2021 | HittER: Hierarchical Transformers for Knowledge Graph Embeddings | 基于transformer的模型 |
| KEPLER | TACL 2021 | KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation |
附录1:KGE算法怎么选?(待补充)
参考1
参考2
参考3
推荐:
附录2:嵌入维度的选取
NLP和network embedding中一般选取50、100或200.
更多可参考:https://www.zhihu.com/answer/179181973
https://www.zhihu.com/answer/2707612555
附录3:应用分析
实体相似度任务选KGE、GE,还是GNN,为什么?
先让大模型发言:




我的建议:
**基于你需要什么类型的实体相似度出发,**展开来说:
1)若是你希望通过语义相似度来做某个任务(如语义上相似的实体检索、推荐),那么毫无疑问,你要考虑使用KGE(其为语义而生,任意两个实体都可以计算语义距离,GE对于这种没有直接连接的节点相似度不适合);
2)如果你希望基于节点之间的一些局部连通相似性来做任务(比如像社区检测这种),那么GE是很适合的。
3)什么时候考虑GNN呢?同时需要考虑连通关系和节点信息时,听起来似乎有点复杂也有点抽象,后面在GNN总结再补充。
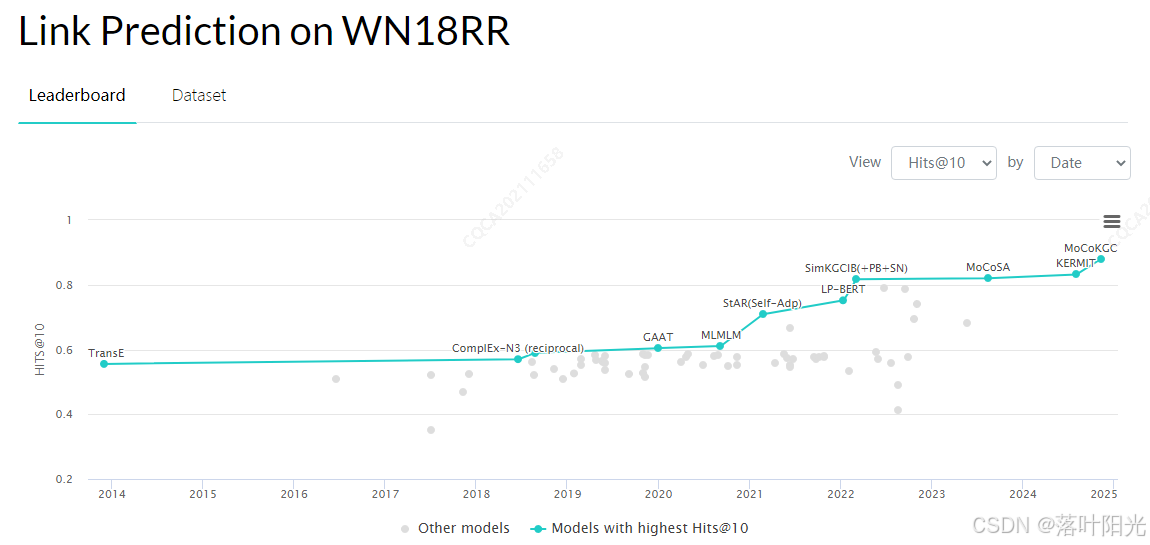
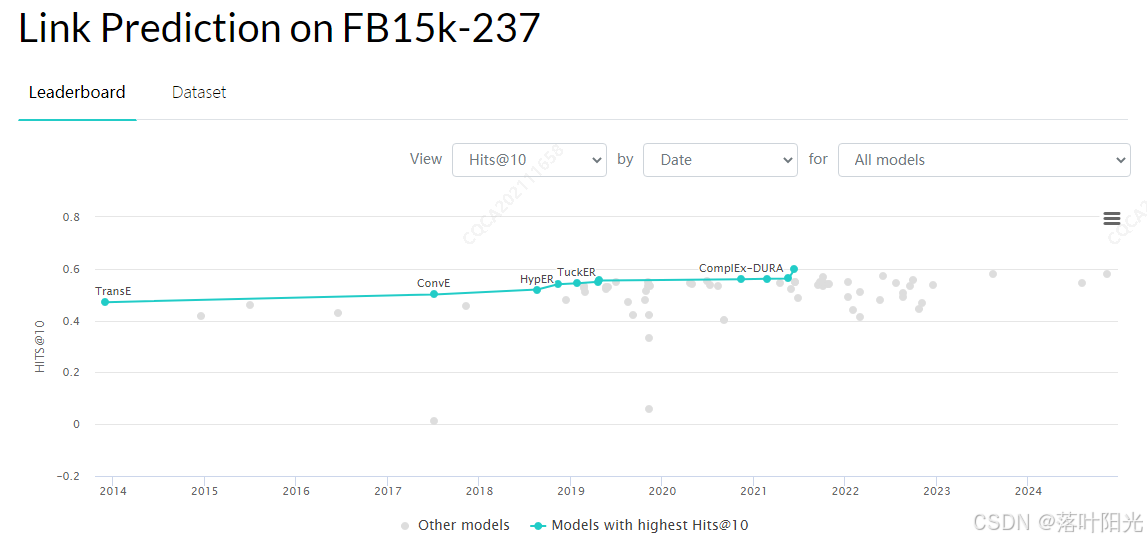
附录4:Paperwithcod最新榜单
时间:2025.1.6
Link Prediction on WN18RR
Link Prediction on FB15k-237

















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









