







就在昨天,美国当地时间周二,OpenAI 正式发布了 GPT-4o 的原生多模态图像生成功能!这可是经过长达一年与人类训练师协作优化的成果,目标只有一个:生成更加逼真、细节更炸裂的图像!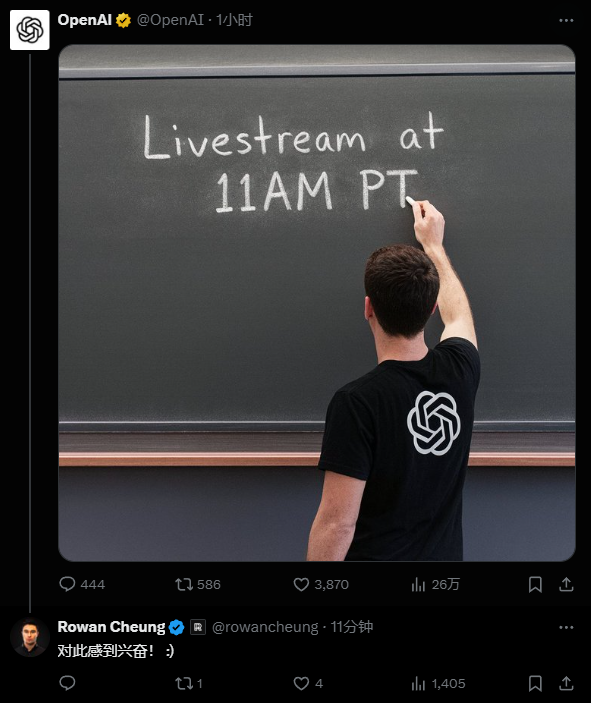 简单来说,你只需要在 ChatGPT 中用文字描述你想要的画面(还能指定宽高比、色号甚至透明度哦!),GPT-4o 就能在一分钟内给你"变"出一张相应的图像。这波更新,简直是突破了以往 AI 生图的诸多边界!先看下如何开启这个功能呢?依次按照下图格式开始即可,在 GPT 上,当你有如下创作图片的选项时,就说明用的是 4o Image Generation 了。
简单来说,你只需要在 ChatGPT 中用文字描述你想要的画面(还能指定宽高比、色号甚至透明度哦!),GPT-4o 就能在一分钟内给你"变"出一张相应的图像。这波更新,简直是突破了以往 AI 生图的诸多边界!先看下如何开启这个功能呢?依次按照下图格式开始即可,在 GPT 上,当你有如下创作图片的选项时,就说明用的是 4o Image Generation 了。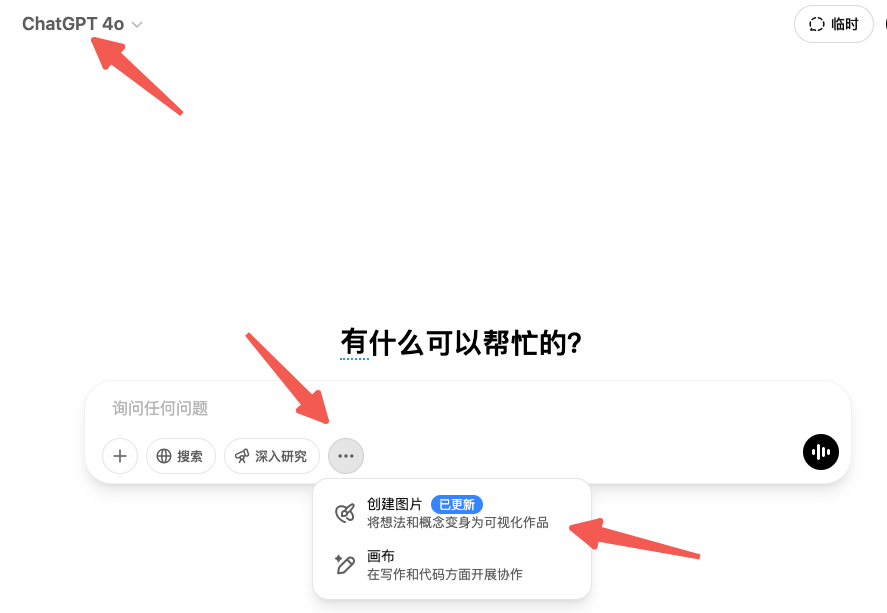
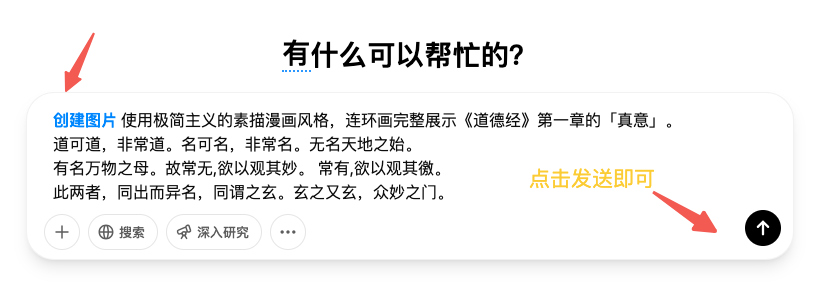 然后就可以开始画图了
然后就可以开始画图了使用极简主义的素描漫画风格,一个版面12副连环画完整展示《龙珠》第一章第二节,对话captions用中文简体汉字展示
使用极简主义的素描漫画风格,连环画完整展示《道德经》第一章的「真意」。道可道,非常道。名可名,非常名。无名天地之始。有名万物之母。故常无,欲以观其妙。 常有,欲以观其徼。此两者,同出而异名,同谓之玄。玄之又玄,众妙之门。 不过有个问题,也就画了不到十张图,就给我限流要等待一分钟才能再用。
不过有个问题,也就画了不到十张图,就给我限流要等待一分钟才能再用。 **一、GPT-4o 图像生成,这次带来了哪些"王炸"特性?**OpenAI 在公告中明确了 GPT-4o 图像生成功能的几大亮点:精准渲染图像内文字: 这意味着制作 logo、菜单、邀请函和信息图等将变得易如反掌!再也不用担心 AI 把文字"糊"成一团了。精确执行复杂指令: 哪怕是细节非常丰富的构图,GPT-4o 也能准确理解并呈现出来,简直是细节控的福音!基于先前图像和文本进行扩展: 能够记住之前的对话内容和生成的图像,确保多次交互之间的视觉一致性,让创作更连贯。支持各种艺术风格: 从写实照片到各种风格的插画,GPT-4o 都能轻松驾驭,满足你天马行空的想象力。
**一、GPT-4o 图像生成,这次带来了哪些"王炸"特性?**OpenAI 在公告中明确了 GPT-4o 图像生成功能的几大亮点:精准渲染图像内文字: 这意味着制作 logo、菜单、邀请函和信息图等将变得易如反掌!再也不用担心 AI 把文字"糊"成一团了。精确执行复杂指令: 哪怕是细节非常丰富的构图,GPT-4o 也能准确理解并呈现出来,简直是细节控的福音!基于先前图像和文本进行扩展: 能够记住之前的对话内容和生成的图像,确保多次交互之间的视觉一致性,让创作更连贯。支持各种艺术风格: 从写实照片到各种风格的插画,GPT-4o 都能轻松驾驭,满足你天马行空的想象力。 GPT-4o生成图片效果展示更令人兴奋的是,除了在 ChatGPT 中直接生成图像,GPT-4o 还被整合进了 OpenAI 的视频生成平台 Sora,进一步扩展了其多模态能力,未来可期!**谁能第一时间体验?升级后的 ChatGPT 就是你的"专属画师"!**这项新功能即日起将作为 ChatGPT 的默认图像生成引擎,向 ChatGPT Free、Plus、Team 及 Pro 用户全面开放,直接取代了之前使用的 DALL-E 3。作为去年推出的多模态模型,GPT-4o 最初的定位就是成本优化版的旗舰 AI 模型,已经具备了生成和理解文本、视频、音频和图像等多种能力。而这次的精调版本,更是让普通用户和企业能够更轻松地创建逼真图像、可读文本段落,甚至是公司 logo 和演示幻灯片等。**背后功臣:人类训练师和"人类反馈强化学习"项目首席研究员 Gabriel Goh 透露,GPT-4o 能够取得如此突破性的进展,关键在于人类训练师对模型数据的标注工作——他们细致地标注了 AI 生成图像中的错别字、畸形手脚和面部特征等问题。通过"人类反馈强化学习 (RLHF)"技术,模型学会了更精准地遵循人类指令,从而生成更准确且实用的图像。
GPT-4o生成图片效果展示更令人兴奋的是,除了在 ChatGPT 中直接生成图像,GPT-4o 还被整合进了 OpenAI 的视频生成平台 Sora,进一步扩展了其多模态能力,未来可期!**谁能第一时间体验?升级后的 ChatGPT 就是你的"专属画师"!**这项新功能即日起将作为 ChatGPT 的默认图像生成引擎,向 ChatGPT Free、Plus、Team 及 Pro 用户全面开放,直接取代了之前使用的 DALL-E 3。作为去年推出的多模态模型,GPT-4o 最初的定位就是成本优化版的旗舰 AI 模型,已经具备了生成和理解文本、视频、音频和图像等多种能力。而这次的精调版本,更是让普通用户和企业能够更轻松地创建逼真图像、可读文本段落,甚至是公司 logo 和演示幻灯片等。**背后功臣:人类训练师和"人类反馈强化学习"项目首席研究员 Gabriel Goh 透露,GPT-4o 能够取得如此突破性的进展,关键在于人类训练师对模型数据的标注工作——他们细致地标注了 AI 生成图像中的错别字、畸形手脚和面部特征等问题。通过"人类反馈强化学习 (RLHF)"技术,模型学会了更精准地遵循人类指令,从而生成更准确且实用的图像。 GPT-4o生成图片效果展示OpenAI 的 AI 系统拥有庞大的用户基础,每周用户超过 4 亿,这使得参与优化的训练师团队(规模略超百人)能够产生巨大的影响力。二、当然,GPT-4o 也并非完美,依然存在一些"小瑕疵":正如《华尔街日报》报道的案例,当用户上传一张带有两扇窗户的客厅照片,并要求重新布置家具时,AI 在重构图像时遗漏了一扇窗户。
GPT-4o生成图片效果展示OpenAI 的 AI 系统拥有庞大的用户基础,每周用户超过 4 亿,这使得参与优化的训练师团队(规模略超百人)能够产生巨大的影响力。二、当然,GPT-4o 也并非完美,依然存在一些"小瑕疵":正如《华尔街日报》报道的案例,当用户上传一张带有两扇窗户的客厅照片,并要求重新布置家具时,AI 在重构图像时遗漏了一扇窗户。 华尔街日报关于用户图片生成案例的报道此外,AI 图像生成的使用仍然面临一些争议,例如艺术家对版权和生计的担忧。OpenAI 首席运营官布拉德·莱特卡普回应称,GPT-4o 的训练数据来自"公开可用的资料"以及与 Shutterstock 等公司的合作内容。OpenAI 总裁格雷格·布罗克曼早在 2024 年 5 月就预告过 GPT-4o 的原生图像能力,但出于未知原因,直到现在才正式发布。此前,谷歌 AI Studio 的 Gemini 2 Flash 实验模型已经推出了类似功能。
华尔街日报关于用户图片生成案例的报道此外,AI 图像生成的使用仍然面临一些争议,例如艺术家对版权和生计的担忧。OpenAI 首席运营官布拉德·莱特卡普回应称,GPT-4o 的训练数据来自"公开可用的资料"以及与 Shutterstock 等公司的合作内容。OpenAI 总裁格雷格·布罗克曼早在 2024 年 5 月就预告过 GPT-4o 的原生图像能力,但出于未知原因,直到现在才正式发布。此前,谷歌 AI Studio 的 Gemini 2 Flash 实验模型已经推出了类似功能。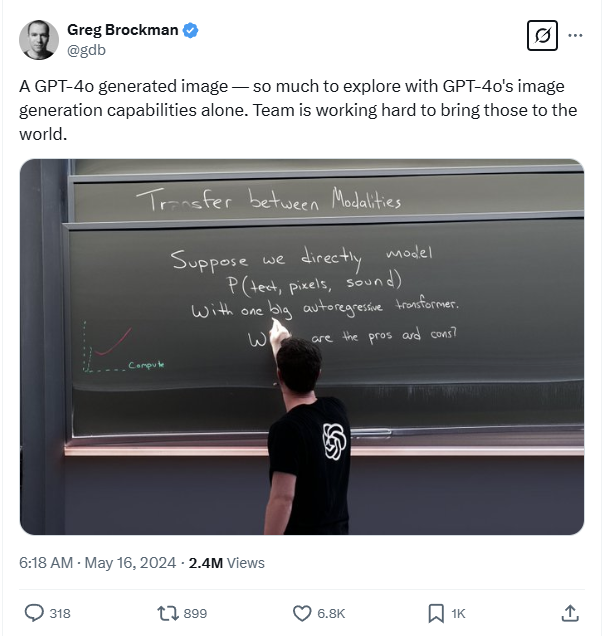 格雷格·布罗克曼此前预告GPT-4o原生图像能力现阶段,GPT-4o 还存在一些需要改进的地方,包括:裁剪问题: 像海报这样较大的图像可能会被过度裁剪。非拉丁字符的文本准确性: 某些非英语字符可能无法正确呈现。小字体中的细节保留: 小字号文本的细节可能会丢失或不够清晰。编辑精确度: 修改图像的特定部分时,可能会意外影响其他元素。OpenAI 表示,他们正在积极解决这些问题,并通过持续的模型改进来提升用户体验。三、保障安全与透明:AI 生成图像将带有"身份证"作为 OpenAI 对负责任 AI 开发承诺的一部分,所有由 GPT-4o 生成的图像都将包含 C2PA 元数据,用户可以验证其 AI 来源。此外,OpenAI 还建立了一个内部搜索工具,用于帮助检测 AI 生成的图像。同时,OpenAI 强调,涉及真人图像的内容会受到更严格的限制,以保护用户隐私和安全。
格雷格·布罗克曼此前预告GPT-4o原生图像能力现阶段,GPT-4o 还存在一些需要改进的地方,包括:裁剪问题: 像海报这样较大的图像可能会被过度裁剪。非拉丁字符的文本准确性: 某些非英语字符可能无法正确呈现。小字体中的细节保留: 小字号文本的细节可能会丢失或不够清晰。编辑精确度: 修改图像的特定部分时,可能会意外影响其他元素。OpenAI 表示,他们正在积极解决这些问题,并通过持续的模型改进来提升用户体验。三、保障安全与透明:AI 生成图像将带有"身份证"作为 OpenAI 对负责任 AI 开发承诺的一部分,所有由 GPT-4o 生成的图像都将包含 C2PA 元数据,用户可以验证其 AI 来源。此外,OpenAI 还建立了一个内部搜索工具,用于帮助检测 AI 生成的图像。同时,OpenAI 强调,涉及真人图像的内容会受到更严格的限制,以保护用户隐私和安全。 OpenAI负责任AI开发承诺OpenAI 首席执行官山姆·奥特曼在新能力上线后发布"小作文",称此次发布标志着"创作自由的新高峰",并强调用户将能够创建各种视觉内容,OpenAI 将在真实世界的使用基础上观察并完善其方法。四、眼见为实!GPT-4o 生图效果实测:以下是一些来自 OpenAI 官方和网友的生图实测案例,让我们一起感受一下 GPT-4o 的强大能力:图片质量相当高,可直接用于科普插画: 比如,
OpenAI负责任AI开发承诺OpenAI 首席执行官山姆·奥特曼在新能力上线后发布"小作文",称此次发布标志着"创作自由的新高峰",并强调用户将能够创建各种视觉内容,OpenAI 将在真实世界的使用基础上观察并完善其方法。四、眼见为实!GPT-4o 生图效果实测:以下是一些来自 OpenAI 官方和网友的生图实测案例,让我们一起感受一下 GPT-4o 的强大能力:图片质量相当高,可直接用于科普插画: 比如,生成一个分光三棱镜。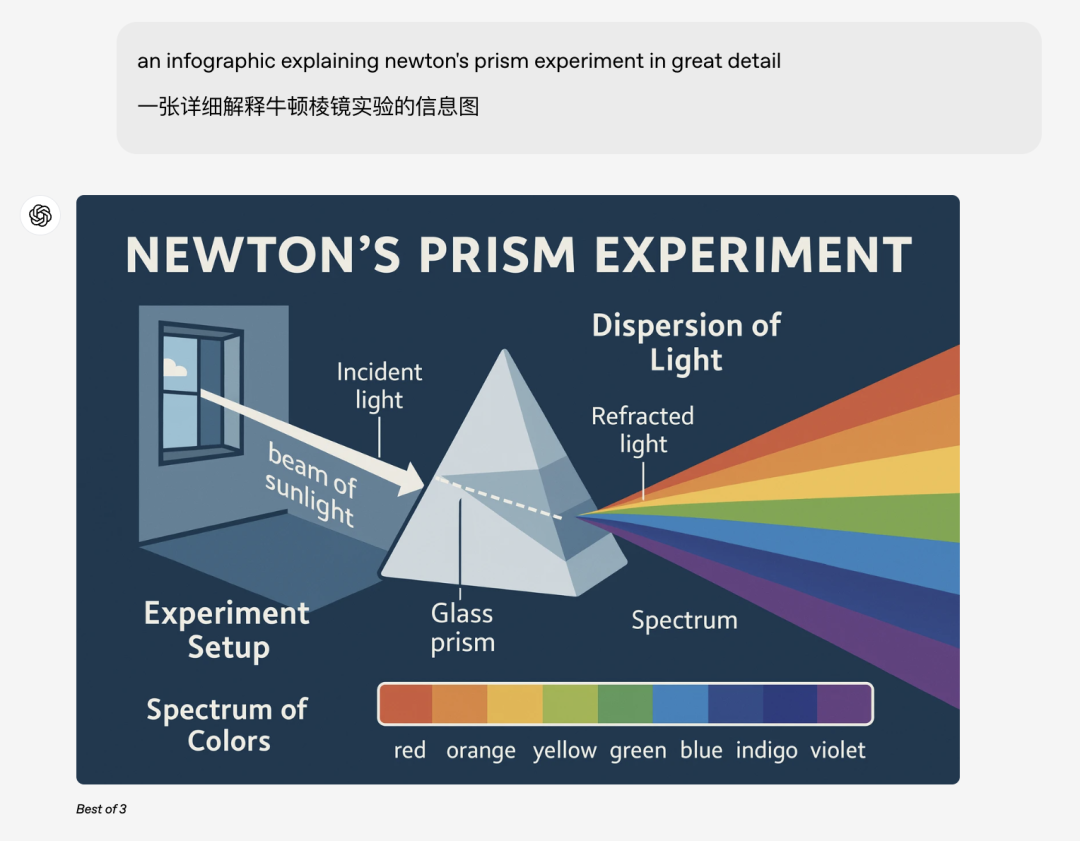 分光三棱镜继续对话,一致性相当好:
分光三棱镜继续对话,一致性相当好:让他把上面的三棱镜画成书册。 三棱镜书册文本渲染绝佳:
三棱镜书册文本渲染绝佳:根据对话内容,画一个菜单(文字是单独给的)。 菜单上下文关联:
菜单上下文关联:上传图片参考风格,精准输出。比如,根据风格插画生成三角形轮子的自行车。 三角形轮子的自行车
三角形轮子的自行车参考图一的配色,重新设计图二相机的配色和质感,
这是我家的两只猫。公猫黄色,母猫灰色。根据他们的长相和特点,帮我预测一下他们幼崽的长相。
保持空间骨架100%保留不变,把这张毛坯房生成意式风格的客厅,拥有皮质沙发与其它搭配的家具、艺术感的装置,高级感的地毯与墙面挂画、具备氛围感的灯光与墙面光泽,整体以2025潘通流行色摩卡慕斯色系,搭配个别墨绿色。要求生成真实的摄影照片的效果。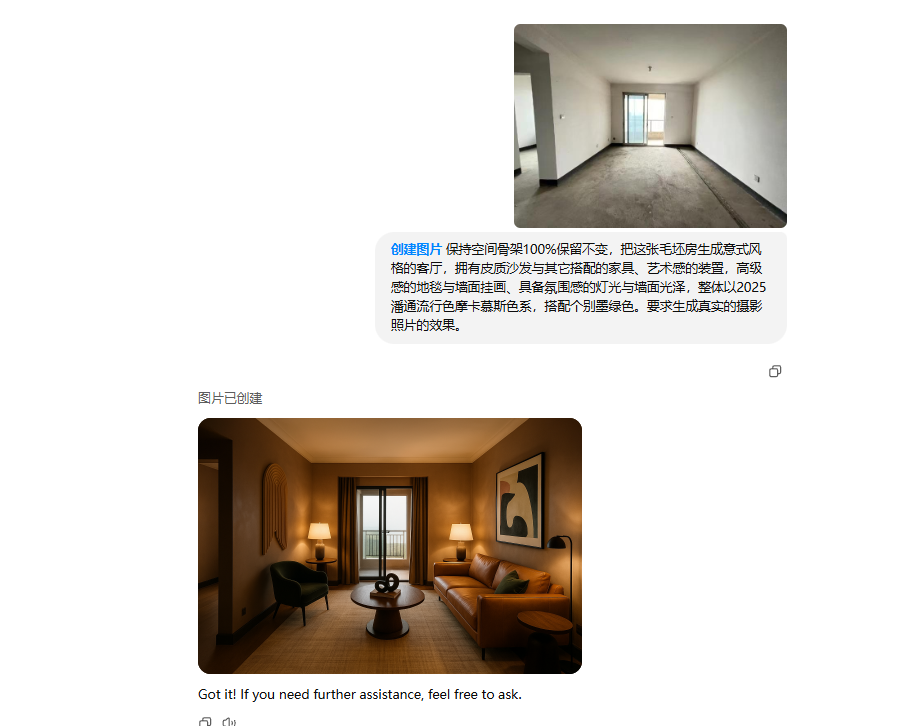
生成吉卜力漫画风格,要求高度还原
用第-个 icon 的风格,重新设计第二个 icon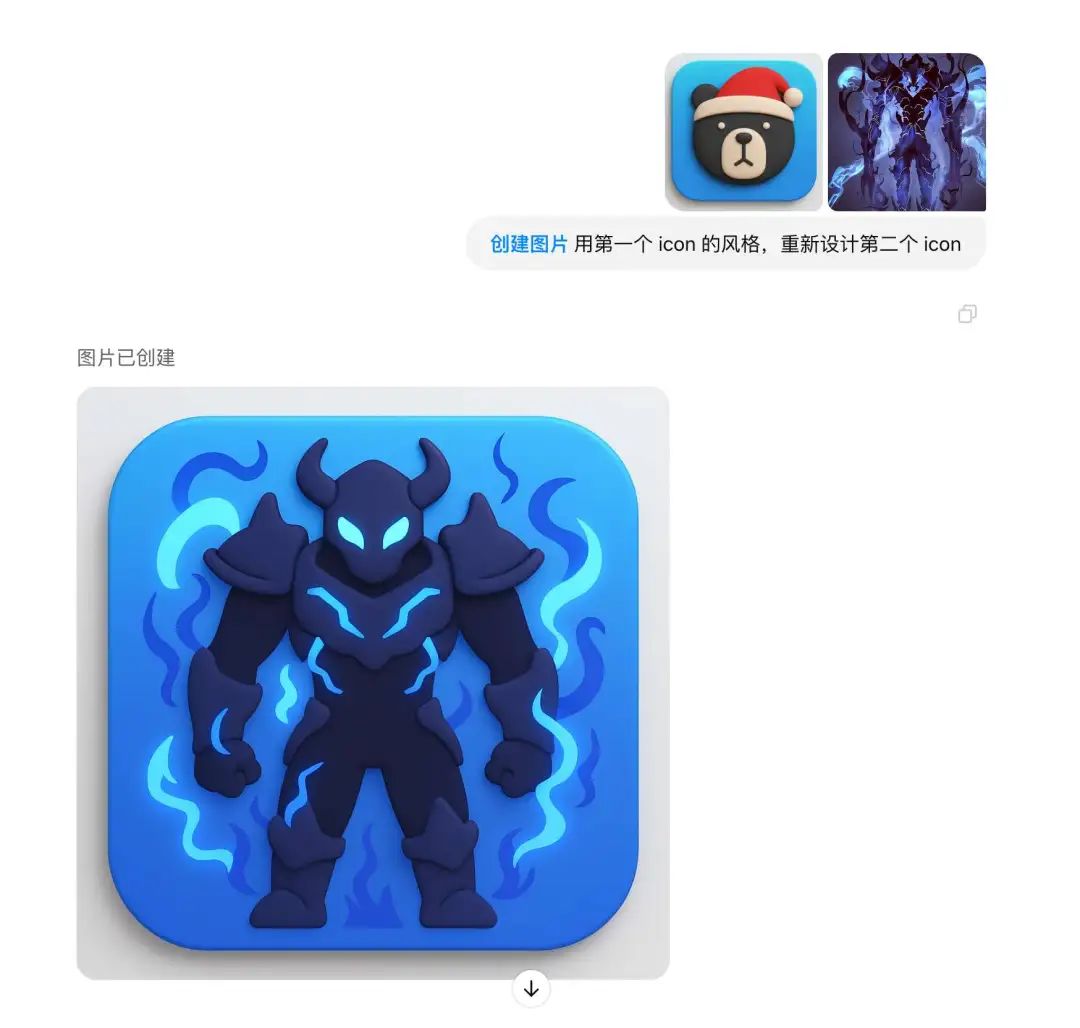
你能基于以上信息,请你帮我设计新的清明节海报,并提供拆解文案
一张卡尔·马克思在美国购物中心停车场匆匆走过的偷拍照片,他惊慌地回头看,试图避免被拍照。他手里拿着多个装满奢侈品的光滑购物袋。他的外套在风中飘动,其中一个袋子在他迈步时摇摆。背景模糊,汽车和发光的商场入口突显运动感。相机的闪光灯部分曝光过度,给图像一种混乱的八卦感。
马正好在海洋与天空相接的地平线上。使用三分法来定位马。由于相机距离拍摄对象非常远,马的大小是整个图像大小的1%。相机视角非常接近地面/海洋,就像虫眼视角。马正好在海洋与天空相接的地方奔跑。
做一个用火龙果的外皮的蜥蜴,画面逼真。
看不见的大象。
电商服装场景,直接试穿衣服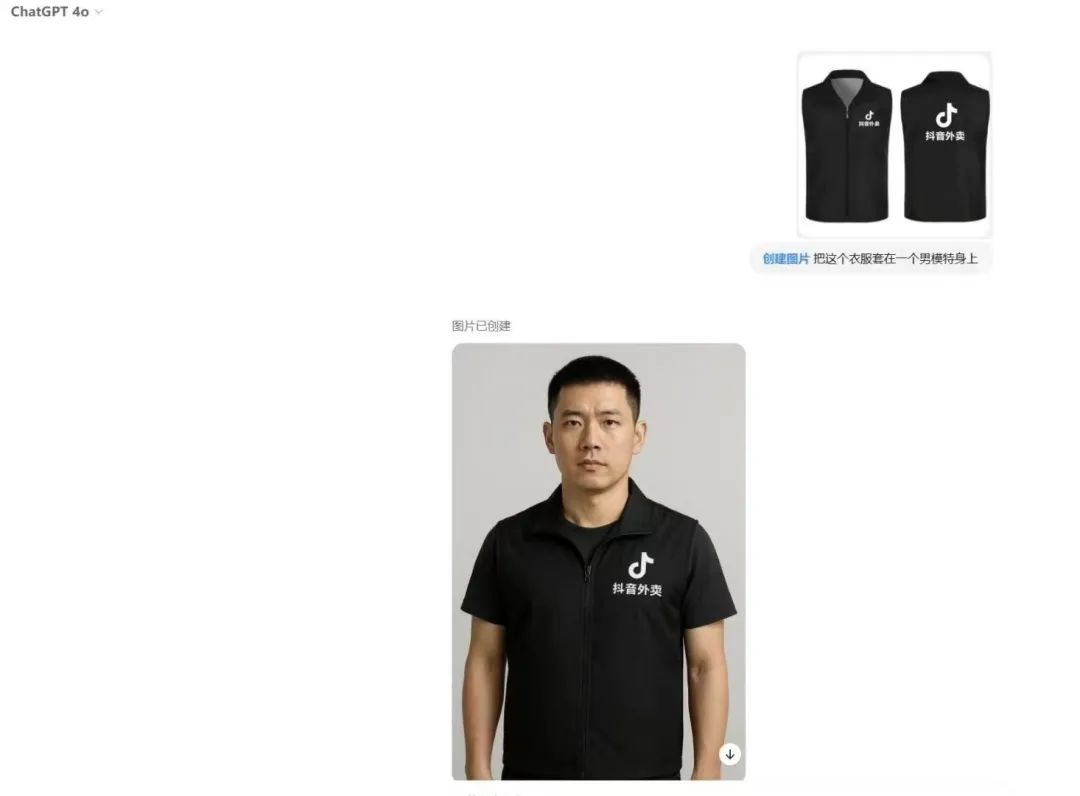
解剖图标记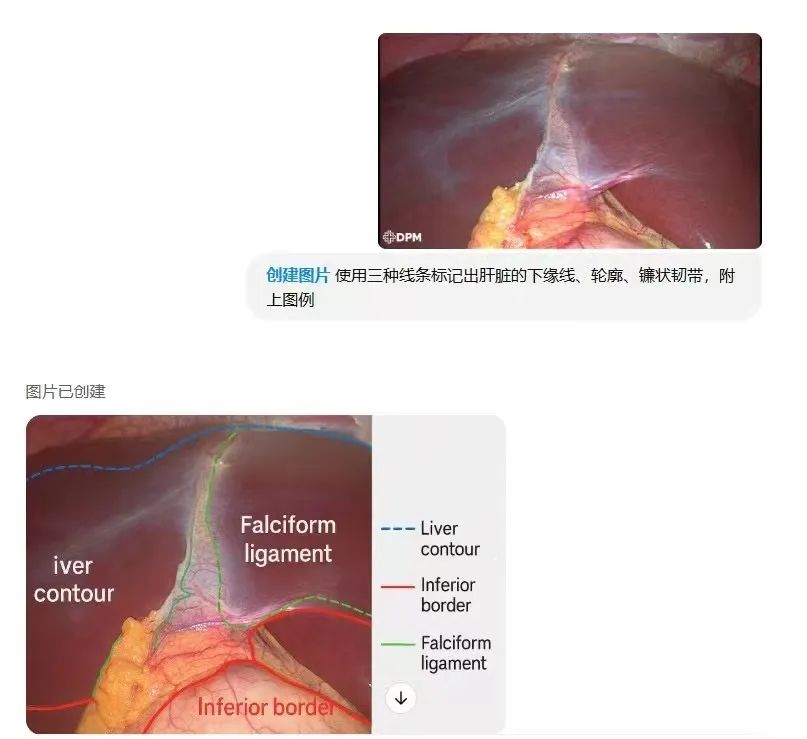
修复卫星图片
电商家具,室内设计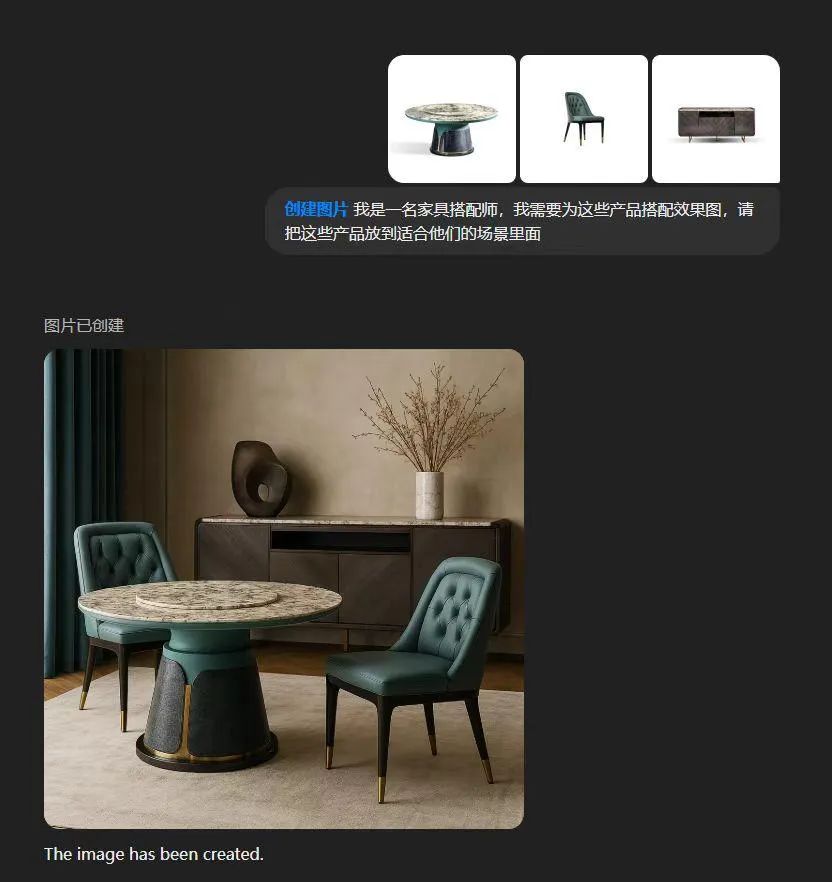
首饰替换,电商场景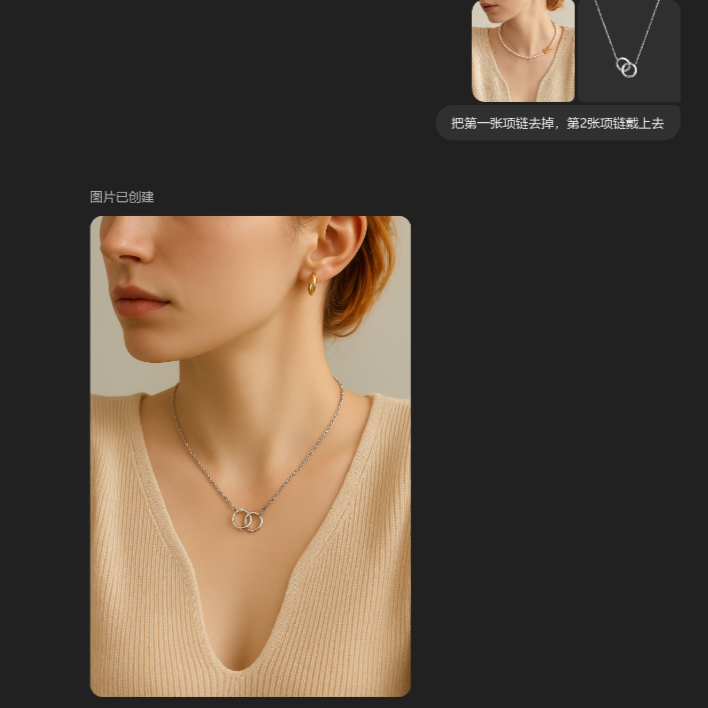
老照片修复 看完这些作图能力,真的太可怕了,这次 GPT 又将让一大批人失业,对于很多行业,简直是降维打击,让我想到《三体》里面的那句台词:我消灭你,与你无关。****五、一个全新的图像生成时代已经到来GPT-4o 的原生多模态能力以前所未有的成熟姿态横空出世,其近乎完美的生成质量和丝滑的多模态对话体验,预示着一个全新的图像生成时代的到来。这已经不仅仅是“能不能用”的问题,而是将彻底颠覆现有 AI 绘图生态,并深刻改变人们与 AI 进行图像创作的交互方式。它将无差别地替代初级执行职位,曾经那些针对大模型的工程优化也将面临严峻挑战,甚至逐步侵蚀更上层的专业领域。这就像一场数字时代的工业革命,曾经看似坚固的技术壁垒和工作流程,在 GPT-4o 面前正被无情地瓦解。我们仿佛已经看到,大量重复性的机械工作将被高效智能的 AI 所取代。虽然在专业和工业级领域,对精度和可控性的需求依然存在,为 ComfyUI 等工具留有一席之地,但这股变革的浪潮已不可阻挡。要么成为弄潮儿,要么被时代抛弃。你,会选择哪一个?
看完这些作图能力,真的太可怕了,这次 GPT 又将让一大批人失业,对于很多行业,简直是降维打击,让我想到《三体》里面的那句台词:我消灭你,与你无关。****五、一个全新的图像生成时代已经到来GPT-4o 的原生多模态能力以前所未有的成熟姿态横空出世,其近乎完美的生成质量和丝滑的多模态对话体验,预示着一个全新的图像生成时代的到来。这已经不仅仅是“能不能用”的问题,而是将彻底颠覆现有 AI 绘图生态,并深刻改变人们与 AI 进行图像创作的交互方式。它将无差别地替代初级执行职位,曾经那些针对大模型的工程优化也将面临严峻挑战,甚至逐步侵蚀更上层的专业领域。这就像一场数字时代的工业革命,曾经看似坚固的技术壁垒和工作流程,在 GPT-4o 面前正被无情地瓦解。我们仿佛已经看到,大量重复性的机械工作将被高效智能的 AI 所取代。虽然在专业和工业级领域,对精度和可控性的需求依然存在,为 ComfyUI 等工具留有一席之地,但这股变革的浪潮已不可阻挡。要么成为弄潮儿,要么被时代抛弃。你,会选择哪一个?
对了,最后想要免费体验这个功能的小伙伴,可以复制下面链接浏览器打开即可:
如何使用GPT-4o的图像生成能力?
想要亲自体验这些强大的功能?可以通过以下途径:
👉 即刻体验: https://agi.maynor1024.live/
平台特点与使用说明
| 特点 | 详细说明 |
|---|---|
| 强大功能 | 全面支持GPT-4o最新图片生成,以及知识问答、文案撰写、论文降重、PDF/Word文档精读分析、PPT制作、代码编写与BUG解决、网站设计等多种实用任务。 |
| 国内友好 | 无需特殊网络环境,无需注册,注重用户隐私保护。服务对标OpenAI官方,功能齐全,但价格仅为官方一半左右。 |
| 便捷体验 | 免注册即可上手体验。使用免费授权码 maynorai2025 即可开始。平台力求1:1还原官网体验,功能不多不少。 |
| 授权码优势 | 提供的4o授权码支持24小时内可用300次,远超OpenAI官方3小时40次的频率限制。平台承诺长期维护,若遇不可抗力导致服务中止,将按未生效日期及购买价比例退款。 |
好啦!朋友****别忘了,点赞、在看、转发,你的反馈真的很重要!
小手一赞,年薪百万!😊👍👍👍


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











