







 本文是Python学习笔记系列的第三篇,重点介绍了pandas模块的数据处理技巧,包括频数统计、缺失值处理(删除与填充)以及数据映射的高效方法。此外,还探讨了如何使用apply函数避免循环,以及如何通过groupby与aggregate函数进行数据汇总。
本文是Python学习笔记系列的第三篇,重点介绍了pandas模块的数据处理技巧,包括频数统计、缺失值处理(删除与填充)以及数据映射的高效方法。此外,还探讨了如何使用apply函数避免循环,以及如何通过groupby与aggregate函数进行数据汇总。
在pandas数据框(2)我们使用pandas模块实现观测的筛选、变量的重命名、数据类型的变换、排序、重复观测的删除、和数据集的抽样,这期我们继续介绍pandas模块的其他新知识点。包括频数统计、缺失值处理、数据映射、数据汇总。
一、频数统计
我们以被调查用户的收入数据为例,来谈谈频数统计函数value_counts
#读数据 import pandas as pd income = pd.read_excel('income.xlsx') #数据前4行 print(income.head(4))
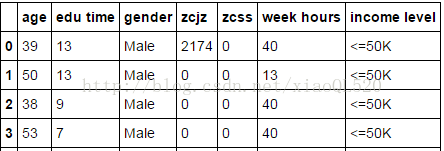
图片来源:http://mp.weixin.qq.com/s/b8Lce66ViRuvxtAYM8e28Q
频数统计,顾名思义就是统计某个离散变量各水平的频次
countedIncome =income.gender.value_counts() print(countedIncome)
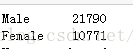
这里统计的是性别男女的人数,是一个绝对值,如果想进一步查看男女的百分比例,可以通过下面的方式实现:
percentIncome = income.gender.value_counts()/sum(income.gender.value_counts()) print(percentIncome)
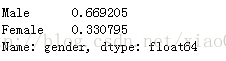
如上是单变量的频数统计,如果需要统计两个离散变量的交叉统计表,该如何实现?pandas模块提供了crosstab函数,我们来看看其用法:
result = pd.crosstab(index=income.gender,columns=income['income level']) print(result)

二、缺失值处理
在数据分析或建模过程中,我们希望数据集是干净的,没有缺失、异常之类,但面临的实际情况确实数据集很脏,例如对于缺失值我们该如何解决?一般情况,缺失值可以通过删除或替补的方式来处理。首先是要监控每个变量是否存在缺失,缺失的比例如何?这里我们借助于pandas模块中的isnull函数、dropna函数和fillna函数
#导入第三方模块库 import pandas as pd import numpy as np #手工编造一个含缺失值的数据框: df =pd.DataFrame([[1,2,3,4],[np.NaN,6,7,np.NaN],[</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2622
2622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









