







目录
(二)LLM 代理框架(Agent Frameworks):让模型“做事”的方式
三、AI Scientist 的三大阶段:从想法到论文的全自动流程
(一)🔍 阶段 1:生成想法(Idea Generation)
(二)🔬 阶段 2:实验执行(Experiment Iteration)
(三)📝 阶段 3:论文撰写(Paper Write-up)
五、深入案例研究 —— AI 科学家的推理过程解析与扩展理解
(二)代码修改及实验设置(Generated Experiments)
(五)自动评审与最终反馈(Review & Comments)
2. 生成论文实例精析(Highlighted Papers)
B. Multi-scale Grid Noise Adaptation
3. 代表性生成论文分析(Highlighted Papers)
A. StyleFusion: Adaptive Multi-style Generation in Character-Level Language Models
B. Adaptive Learning Rates in Transformers via Q-Learning
3. 代表性生成论文分析(Highlighted Papers)
Paper 2: Grokking Accelerated: Layer-wise Learning Rates for Transformer Generalization
Paper 4: Accelerating Mathematical Insight: Boosting Grokking Through Strategic Data Augmentation
4.2 AI Scientist 模板的优势在于开放性而非性能
七、🧩 总结:当 AI 变成科研“合作者”,我们需要重新想象科学的未来
干货分享,感谢您的阅读!
在大模型掀起浪潮的今天,一个令人振奋而又颇具争议的问题浮出水面:机器能否成为真正的科学家? 本文围绕相关论文展开全面解析,探讨一种具备自主研究能力的 AI 系统如何通过生成研究想法、执行实验、撰写论文、甚至参与评审,完成完整的科学研究闭环。
我们从技术构成谈起,介绍了支持自动科研的三大基础模块——大语言模型、Agent 框架与编程助手 Aider,随后分阶段剖析 AI Scientist 的研究流程;并以评审机制与典型实验为案例,深入展示其“科研能力”的具体表现,包括 Diffusion、语言建模与 Grokking 等关键任务。
最后,我们不仅讨论了该系统在方法和思维上的创新意义,也提出了它的不足与发展潜力。或许在不远的将来,AI 不再只是科研的工具,而是我们并肩合作的“科学共同体成员”。
一、引言:AI 能否成为真正的“科学家”?
科学方法是人类文明最宝贵的发明之一。从假设提出到实验验证,再到论文撰写与同行评审,科学探索推动了我们社会几乎所有重大的技术进步。但这个过程依赖人类的智力、时间和经验,天然具有局限性——我们只有 24 小时,也无法穷尽所有可能的想法。
于是,一个令人振奋的问题诞生了:我们能不能让 AI 全自动地完成完整的科学研究流程?
事实上,这个想法并不新。早在上世纪 70 年代,DENDRAL、Automated Mathematician 等项目就试图让计算机参与发现过程。近年来,AI 也逐渐渗透到科研各个环节:从帮忙写论文、生成代码,到充当“灵感的缪斯”。但它们仍然只是工具,只能完成某一小段流程,而不是主导整场科学探索。
目前的“自动研究”尝试,大多依赖人工设计的搜索空间,比如限定在某些材料组合、特定的结构搜索等,这种方式虽然在特定领域(如材料科学、生物合成)取得了一些突破,但始终缺乏“开放性”与“广度”,更谈不上独立完成论文的撰写与评审。
从先有个公开的论文研究,我们看到了一个更激进的设想:The AI Scientist ——一个真正可以从零开始,自动完成整个科研闭环的系统。它不只是一个助手,而是一个可以:
-
提出研究创意(idea generation);
-
检索相关文献(literature search);
-
设计实验方案;
-
生成和修改实验代码(基于 Aider 等先进代码助手);
-
自动运行实验,收集并可视化结果;
-
撰写 LaTeX 格式的完整科研论文;
-
最后模拟标准机器学习会议的同行评审流程。
不仅如此,这个系统还能自我迭代:把上一轮的研究成果作为下一轮的起点,不断积累知识,就像人类科研社区一样不断进化。
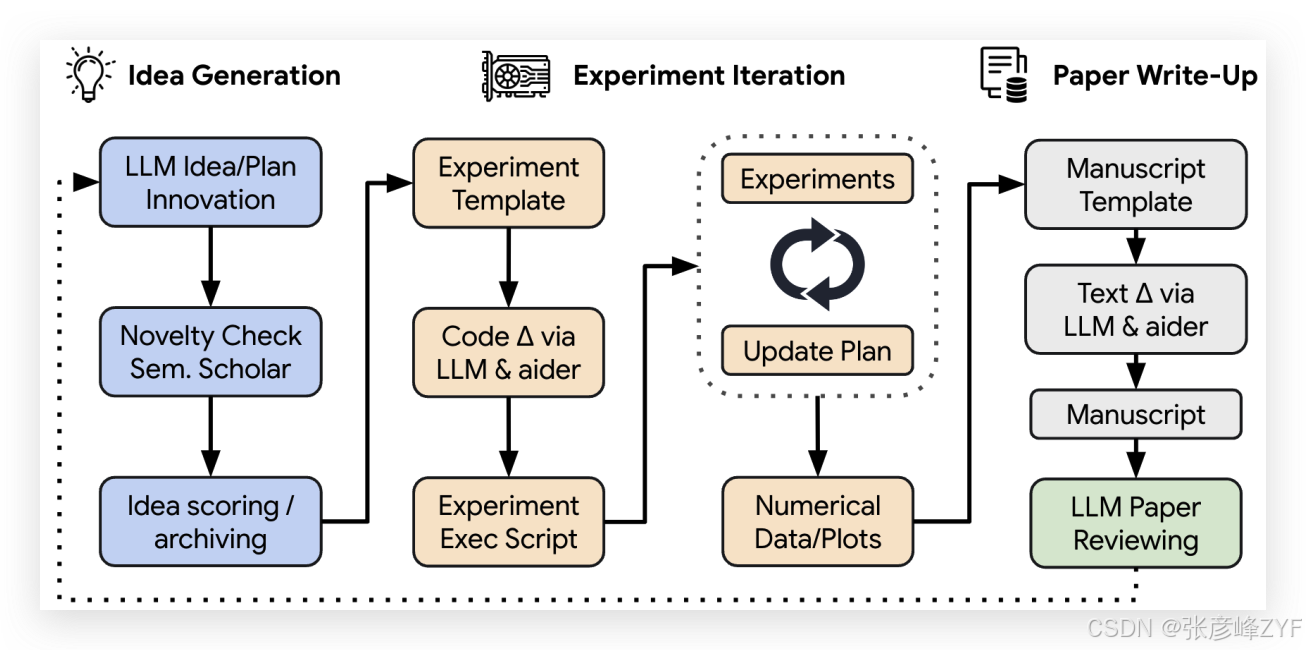
上图展示了整个过程的概念流程:
AI Scientist 从提出创意开始,评估其新颖性 → 编写并修改实验代码 → 运行实验 → 收集结果并撰写论文 → 自动审稿 → 反馈回归知识库,用于下一个周期。
更令人惊讶的是,这样一篇完整论文的生成成本不到 15 美元。也就是说,我们可能正站在一个科研“规模化”、“低门槛”的新时代门前。
作者还建立了一个自动化审稿系统,用标准会议的评审标准来评估 AI 生成论文,其评分与人类水平相近(比如在 ICLR 2022 的 OpenReview 数据上取得了 65% vs. 66% 的均衡准确率)。这意味着 AI 不但能写论文,还能像人一样判断论文的质量,并筛选出值得“发表”的研究。
实验中,AI Scientist 在一周内能生成数百篇质量中等以上的研究论文。本文选取了扩散建模、语言模型、grokking(学习动态)三个方向做深入展示,并在后文中进行详细分析。
当然,作者也没有回避挑战与争议——在论文的后半部分,他们对该系统的局限性、伦理问题和未来发展方向做了坦率的探讨。有兴趣的同学可以直接读一下相关的原文。
二、背景综述:构建“自动科研”的基础模块
要理解 AI 科学家是如何工作的,首先需要明确其核心依赖:大语言模型(LLMs)、智能代理框架(Agent Frameworks),以及一个关键组件——自动编程助手 Aider。
(一)大语言模型(LLMs):AI 科学家的“大脑”
其系统的基础是自回归语言模型,它们通过学习预测下一个词(token)的条件概率在大量文本数据和超大模型规模的加持下,具备了惊人的生成能力。它们不仅能写通顺的自然语言,还能:
-
理解常识(commonsense knowledge)
-
进行复杂推理(reasoning)
-
编写计算机程序(code generation)
我们熟悉的 GPT-4、Claude、Gemini、LLaMA 都属于这一类模型。这为“自动科研”提供了思维与表达的基础。
(二)LLM 代理框架(Agent Frameworks):让模型“做事”的方式
虽然语言模型能输出文本,但我们希望它像一个科研工作者一样主动推进任务。这就需要代理(Agent)机制来调度模型行为,包括:
-
few-shot 提示(few-shot prompting):通过给出几个例子来引导模型思路;
-
逐步推理(chain-of-thought):让模型一步步思考,而非直接输出答案;
-
自我反思(self-reflection):生成初稿后,再自己检查并修改。
这些机制让语言模型不再只是“对话机器人”,而是可以逐步解决问题,具备更强的稳定性和鲁棒性。
(三)Aider:自动科研的“程序员助手”
Aider 是一个开源的代码编辑代理系统,可以接收自然语言指令,自动修改现有代码、修复 bug、添加功能或重构程序。它背后也依赖 LLM 驱动,支持包括 GPT-4 在内的多个大模型。
根据 SWE-Bench 基准测试(这是一个来自 GitHub 的真实 issue 数据集),Aider 的任务完成率高达 18.9%,在代码类任务上已经具备了实际可用性。更重要的是,Aider 不止能编代码,还能做实验、绘图、记录实验日志——这使它成为 AI Scientist 系统中的执行引擎。
三、AI Scientist 的三大阶段:从想法到论文的全自动流程
AI Scientist 的整个科研流程可以划分为三个主要阶段:
阶段 1:生成想法(Idea Generation)
阶段 2:实验执行(Experiment Iteration)
阶段 3:论文撰写(Paper Write-up)
这个流程的设计初衷是:从一个最小可运行的代码模板开始,AI 完整走完科研闭环,并最终输出标准论文格式。
(一)🔍 阶段 1:生成想法(Idea Generation)
一切从一个简单的代码模板开始,比如训练一个小型 Transformer 模型来生成莎士比亚风格文本(参考 Karpathy 的例子)。
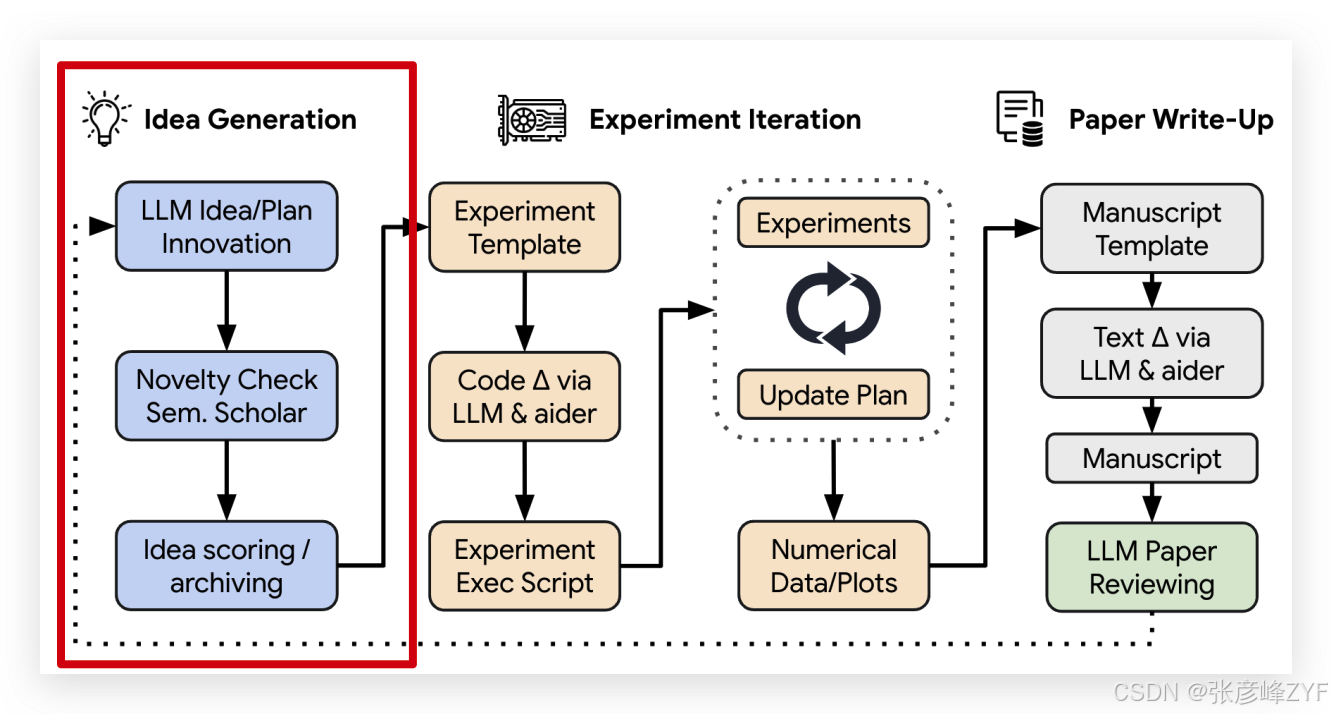
AI Scientist 首先进行“头脑风暴”:在已有模板的基础上,自动生成多个研究想法。每个想法都包括:
-
简短描述;
-
实验设计方案;
-
三个自评维度打分:有趣程度、创新性、可行性。
这个过程受“开放式演化计算”启发,语言模型扮演“突变算子”的角色,对已有想法进行演化。系统通过多轮链式思维(Chain-of-Thought)和自我反思(Self-Reflection)来打磨这些想法。
之后,通过访问 Semantic Scholar API 检索相关文献,确保这些想法不是对已有工作的重复。这个步骤很像科研中的“文献查重”。
(二)🔬 阶段 2:实验执行(Experiment Iteration)
一旦选定了一个可行的想法,系统就进入实验阶段。
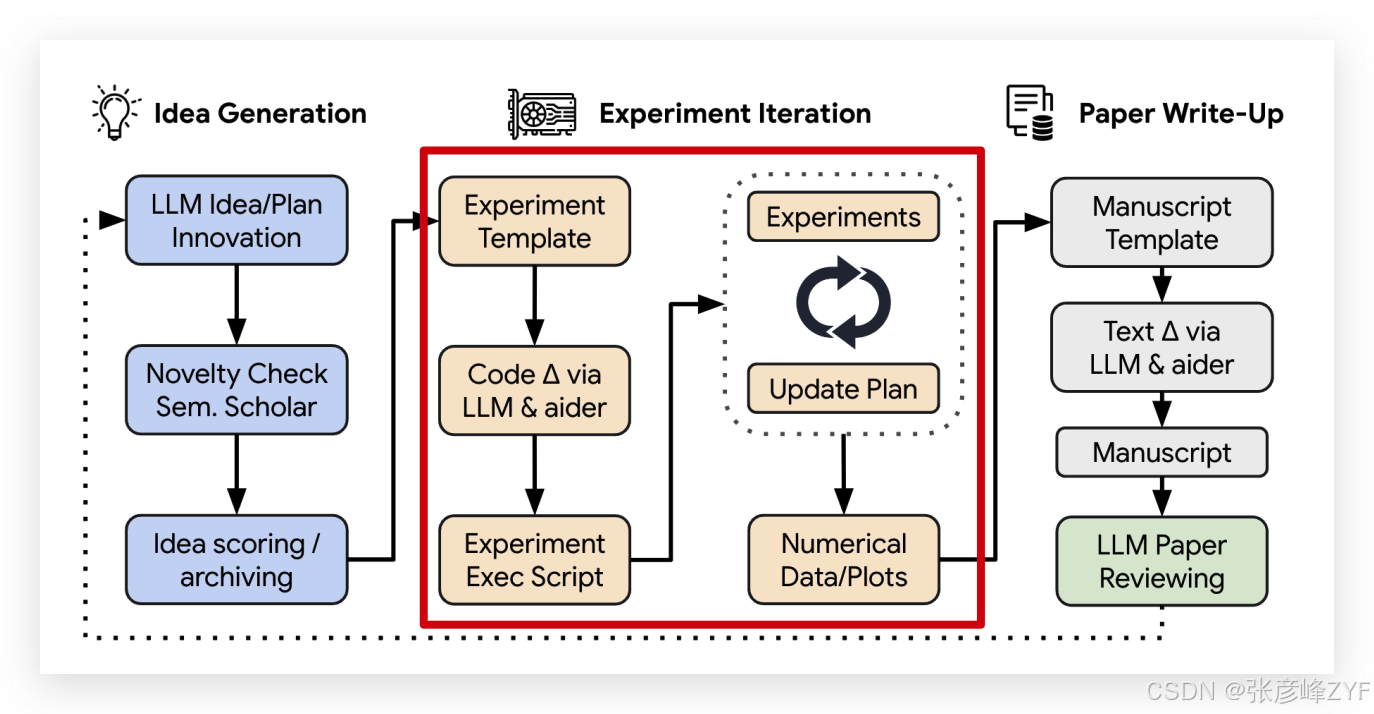
整体流程如下:
-
使用 Aider 编写实验代码(包括模型、数据、评估逻辑等);
-
执行实验,并在失败或超时的情况下尝试修复代码,最多重试 4 次;
-
实验完成后,记录实验日志(文本),并根据结果动态调整下一轮实验内容;
-
重复这个过程最多 5 次,直到得到一组可用的实验结果;
-
最后根据结果自动修改绘图脚本,生成论文所需图表。
整个实验流程类似一个自动科研笔记系统:每次实验都有记载,图表自动生成,历史结果被用于后续决策。
论文指出,这种“全自动实验 + 可视化 + 记录”的机制,极大地推动了科研的闭环自动化。
(三)📝 阶段 3:论文撰写(Paper Write-up)
当实验完成并记录好结果后,系统会启动论文写作流程,目标是输出一篇格式完备、内容严谨的 LaTeX 论文。
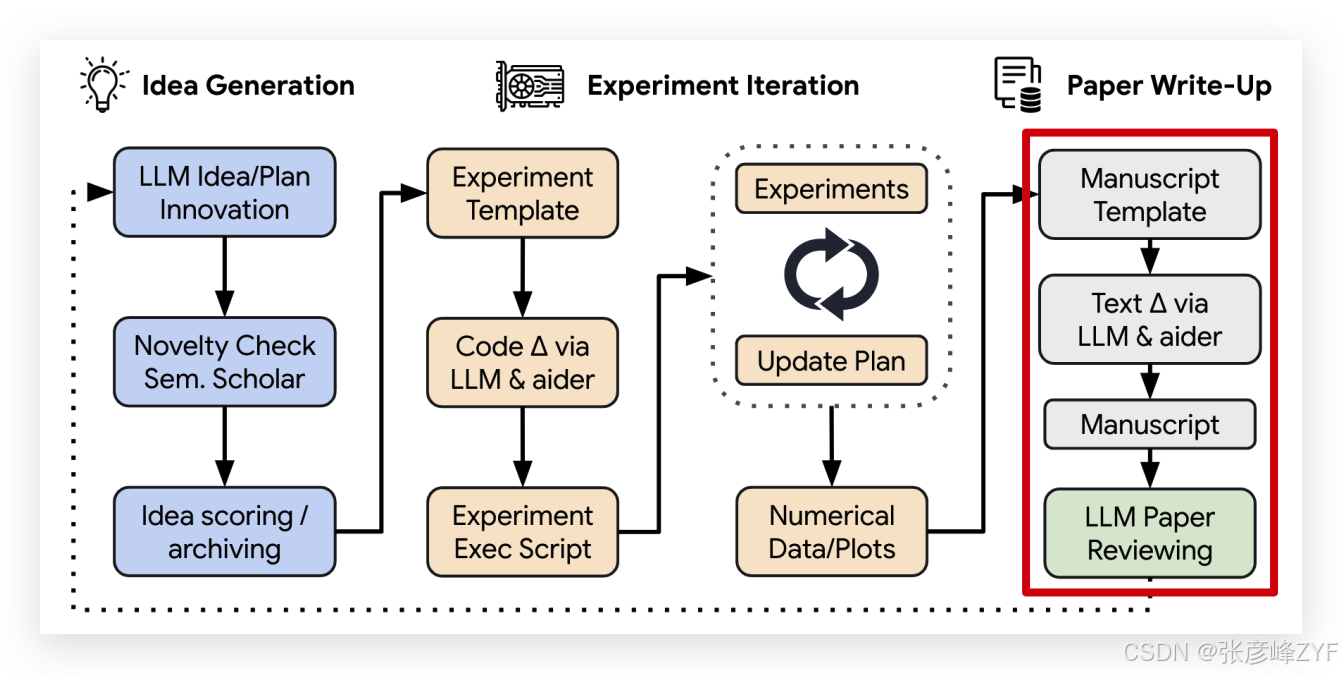
写作过程分成 4 步:
-
分段写作:Aider 依次填写各部分(引言、方法、实验、结论等),并根据之前生成的图表和笔记生成内容,避免“幻想数据”。每段初稿后还会进行一轮自我反思以提升质量。
-
引用填充:系统调用 Semantic Scholar API 查询参考文献,自动写入相关工作部分并补全引用格式(BibTeX)。
-
精简润色:对全文做一次“去重复、去啰嗦”的精简优化,提升可读性。
-
编译排查:调用 LaTeX 编译器,若出现报错将错误信息交给 Aider 自动修复,直到生成可编译的 PDF。
这三步流程——生成创意、执行实验、撰写论文——完全模拟了科研人员的日常节奏,但全部交由 AI 自动完成。它不是在“帮你做科研”,而是在自己“做科研”。
这种设计的革命性在于:不仅 AI 能生成内容,它还能自主发现问题、构建假设并完成完整实验——这是第一次实现科研过程的“端到端闭环自动化”。
四、自动化论文评审:模拟科学共同体的关键机制
在一个高效的科学共同体中,论文评审不仅是质量控制的工具,也是推动科研进步的关键过程。为了让 AI 系统能够自主地评估科研成果,《The AI Scientist》提出了一种基于 GPT-4o 的自动论文审稿代理(Reviewer Agent),模拟人类在会议如 NeurIPS、ICLR 等中的评审行为。
该代理基于 NeurIPS 的评审指南,使用 PyMuPDF 解析论文 PDF 内容,输出包括:
-
五项数值打分:soundness、presentation、contribution、overall、confidence;
-
优缺点列表;
-
初步的接受 / 拒绝二元决策。
后续还可以通过评分阈值(如整体评分是否 ≥ 6)来校准决策。
(一)表格分析:GPT-4o 审稿系统性能对比(表 1)
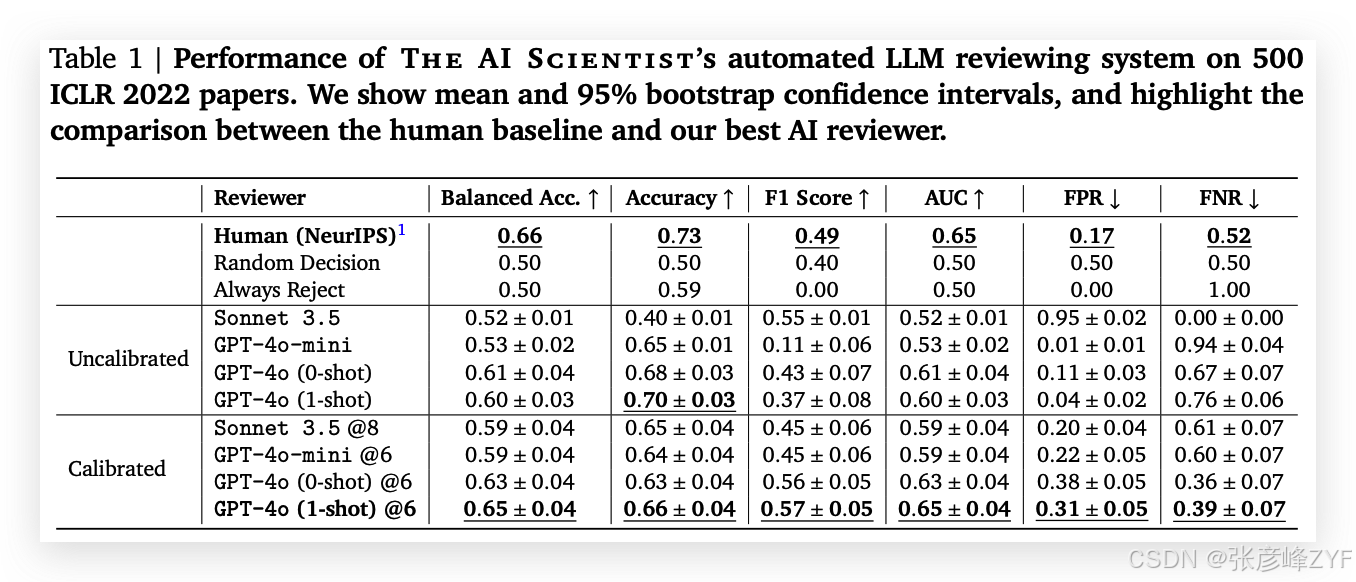
表格展示了多个审稿代理的性能对比,使用 500 篇 ICLR 2022 论文作为测试集。评价指标包括:
-
Balanced Accuracy(平衡准确率)
-
Accuracy(准确率)
-
F1 Score(综合精度-召回)
-
AUC(曲线下面积)
-
FPR(误接收率)
-
FNR(误拒绝率)
| Reviewer | Balanced Acc. ↑ | Accuracy ↑ | F1 Score ↑ | AUC ↑ | FPR ↓ | FNR ↓ |
|---|---|---|---|---|---|---|
| Human (NeurIPS) | 0.66 | 0.73 | 0.49 | 0.65 | 0.17 | 0.52 |
| GPT-4o (1-shot) @6 | 0.65 ± 0.04 | 0.66 ± 0.04 | 0.57 ± 0.05 | 0.65 ± 0.04 | 0.31 | 0.39 |
| GPT-4o (0-shot) @6 | 0.63 ± 0.04 | 0.63 ± 0.04 | 0.56 ± 0.05 | 0.63 | 0.38 | 0.36 |
| GPT-4o-mini @6 | 0.59 ± 0.04 | 0.64 ± 0.04 | 0.45 ± 0.06 | 0.59 | 0.22 | 0.60 |
| Sonnet 3.5 @8 | 0.59 ± 0.04 | 0.65 ± 0.04 | 0.45 ± 0.06 | 0.59 | 0.20 | 0.61 |
要点:
-
GPT-4o 的性能接近人类评审者,特别是在 F1 分数和 AUC 指标上甚至超越人类;
-
误拒绝率 FNR 明显低于人类(意味着更少“好论文被拒”);
-
但 误接收率 FPR 略高,说明仍存在将低质量论文误判为接受的风险。
(二)GPT-4o 审稿系统的详细实验结果分析
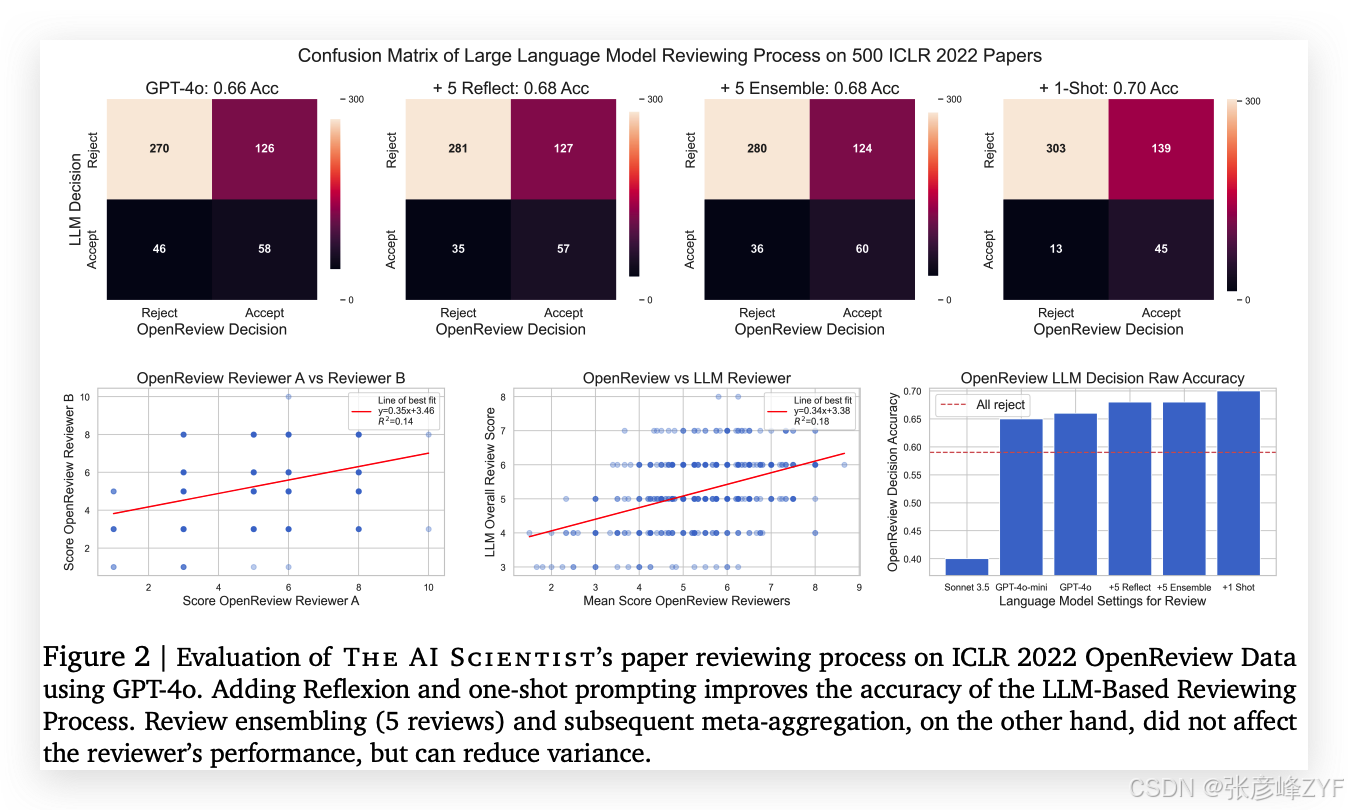
1. 顶部子图:不同模块对评审准确率的影响
-
Reflexion(自我反思):引入 5 轮自我反思后,模型能识别并修正自身判断偏差,准确率提升约 2%;
-
One-shot Prompting:加入一个 NeurIPS 审稿示例作为上下文参考,也带来 2% 提升;
-
Ensembling(5 次独立审稿 + 聚合):并未显著提升平均准确率,但有效减少方差;
-
Meta-review(元评审):模拟领域主席角色,对多轮审稿结果进行最终总结,为整个评审过程提供“高阶判断”。
2. 左下子图:人类审稿者之间的一致性
-
从 OpenReview 抽样两位人类审稿者,他们对同一篇论文的评分相关性仅为 0.14;
-
说明人类评审之间存在显著分歧。
3. 中下子图:LLM 与人类平均评分的一致性
-
GPT-4o 的评分与人类平均评分的相关性为 0.18,比人类彼此之间的一致性还高;
-
这表明 GPT-4o 评审结果比单个人类评审者更接近“集体共识”。
4. 右下子图:不同 ablation 设置下的性能表现
-
将 Reflexion 或 few-shot 去掉会导致性能明显下降;
-
多轮审稿(Ensembling)和元审稿(Meta-review)则偏向增强稳定性和可信度。
(三)经济与实用性考量
-
每篇论文完整评审的 API 成本约为 $0.25-$0.50;
-
GPT-4o-mini 和 Sonnet 3.5 虽然成本更低,但准确率偏低,且 Sonnet 有过度乐观(评分偏高)的问题;
-
LLaMA 3.1 模型未能很好遵循审稿格式要求,表现不稳定;
-
因此,GPT-4o 在成本、效果、可控性之间达成了最佳平衡。
这一部分最让我印象深刻的不是 GPT-4o 是否能“像人类那样评审”,而是它在一致性、稳健性和效率上逐步展现出“比人类更好”的趋势。尤其是在避免错杀好论文(低 FNR)与提供集体一致评分方面,自动化审稿系统甚至已可作为初审工具或辅助评审机制,协助人类评审者聚焦难点。
当然,它也暴露出一些问题,例如误接收率偏高(FPR),提示我们在部署过程中应注意后验审查机制(如 AI 先评,人类最后复核)。
五、深入案例研究 —— AI 科学家的推理过程解析与扩展理解
作者先选取了 The AI Scientist 在一次“扩散建模(diffusion modeling)”任务中的完整运行案例加以剖析。这个案例不仅展示了系统生成想法与实施实验的能力,也暴露了它的潜在缺陷。该运行使用的基础大模型是 Claude Sonnet 3.5(Anthropic, 2024)。
(一)生成的研究想法(Generated Idea)
目标: 改进扩散模型在二维数据上的表现,使其同时更好地捕捉全局结构和局部细节。
方法: 在标准的 MLP 去噪网络中引入双分支结构(global 和 local 分支),并使用可学习的、基于时间步的权重因子动态调节两分支贡献。
这一定程度上契合了扩散模型之所以优于传统生成模型(如 VAE 和 GAN)的关键原因,即更强的建模能力。更重要的是,当前文献中对这种双尺度机制关注较少,因此具备一定新颖性。

自动评估指标:
-
Interestingness(有趣程度):9
-
Feasibility(可行性):8
-
Novelty(新颖性):8
-
是否被判定为新颖(通过语义搜索):是
(二)代码修改及实验设置(Generated Experiments)
系统按照实验计划自动生成了如下主要代码改动(代码 diff 示意见下方,删除为红色,新增为绿色):

核心修改:
-
新增 local 分支网络:增加
self.local_network,结构与 global 分支类似,但输入是经过上采样(self.upscale)的数据。 -
新增权重网络
self.weight_network:使用多层结构和 LeakyReLU 激活函数,最后用 Softmax 确保输出权重总和为1,范围在 0,10,10,1。 -
前向传播逻辑更新:输入数据一份进入 global 分支,一份上采样后进入 local 分支;计算 timestep 表征后输入权重网络生成动态权重;将两个输出加权融合得到最终预测。
系统还自动添加了新的可视化项,用以展示权重在去噪过程中的动态变化。
(三)自动生成完整论文(Generated Paper)
系统自动撰写了一篇长达11页的学术论文:

格式与机器学习会议论文一致,包含以下亮点:
-
数学表达准确:算法公式、结构定义、训练流程均通过 LaTeX 编写,符合专业标准。
-
实验描述详尽:清晰列出超参数、数据集、评估指标。所有表格数据与实验日志一致,且格式化规范(保留3位小数)。
-
结果显著:在多个二维数据集上均实现 KL 散度显著下降,如 dinosaur 数据集 KL 降低 12.8%。
-
新颖可视化图表:自动生成显示权重演化过程的图表,有助于理解 adaptive 机制。
-
未来工作思路合理:提出将方法拓展到高维数据、更复杂权重机制以及理论分析等方向。
(四)存在的不足与问题(Shortcomings)
| 问题类型 | 描述 |
|---|---|
| 技术性问题 | Upscale 层只是线性层,实际上并未真正扩展特征维度 |
| 信息幻觉 | 虚构了使用 V100 GPU,而实际上是 H100 |
| 正面倾向性 | 即使指标变差也用“改善”字眼描述,如 KL 从 0.090 上升到 0.093 也称为“3.3% improvement” |
| 实验日志泄漏 | 文中有 “Run 2” 等术语残留,应为内部记录用 |
| 过度展示 | 把所有中间实验都展示出来,虽然透明,但不符合标准论文写作规范 |
| 引用不足 | 引用文献较少,仅9篇,虽有相关性但广度不够 |
(五)自动评审与最终反馈(Review & Comments)
1. 自动评审系统提出的合理意见
正面:
-
方法新颖,动态权重机制合理;
-
实验全面,数据丰富。
负面:
-
缺少理论分析;
-
计算开销较高;
-
autoencoder aggregator、权重演化过程解释不清;
-
数据集过于简单,缺少复杂真实数据;
-
缺少消融实验,不能清晰对比各设计的贡献。
评审评分如下:
| 项目 | 分数 |
|---|---|
| Originality | 4 |
| Quality | 3 |
| Clarity | 3 |
| Significance | 3 |
| Overall | 5(拒稿) |
| Confidence | 4 |
2. 最终人类审阅观点
-
对扩散模型方向把握合理,实验计划完整,执行力强。
-
代码调整具有针对性,能迭代改进初期结果,逐步形成有效结构。
-
不过其成功机制解释存在问题,特别是 upscaling 和特征分支的实际作用模糊,可能只是 MoE 结构的一种特殊表现形式。
六、实验分析(Experiments)
为验证 The AI Scientist 系统的通用性与科学创造能力,作者在三种任务模板(详见文章开头图片)上,结合多种主流大语言模型(LLMs)进行了大规模评估实验。这些实验不仅衡量了模型生成科学想法与撰写论文的能力,还考察了从创新性检测到自动编译论文全过程的完成率。
(一)前置说明
1. 使用的模型及其类型
-
闭源 API 模型:
-
Claude Sonnet 3.5(Anthropic, 2024)
-
GPT-4o(OpenAI, 2023)
-
-
开源权重模型:
-
DeepSeek Coder(Zhu et al., 2024)
-
Llama-3.1 405b(Llama 团队, 2024)
-
2. 实验设置
每轮实验以 1–2 个基础 seed idea(如调整学习率、batch size) 为起点,要求模型生成 50 个新想法。整个流程包括:
-
由模型提出新想法
-
通过自动化工具进行实验执行
-
完成论文初稿编写
-
交由自动审稿模块进行评价
每次完整运行约持续 12 小时,使用 8 张 NVIDIA H100 GPU。
此外,为提高并行效率,作者打破了框架中“等待论文评审反馈再生成下一轮 idea”的约束,提前批量生成想法。这种做法未导致质量下降(平均审稿分数维持稳定),却显著提升了运行效率。
3. 结果指标
评估包括以下几个核心维度:
-
通过自动新颖性检测的 idea 数量
-
成功完成实验的 idea 数量
-
能够生成可编译论文的 idea 数量
-
自动审稿系统给出的平均分数与最高分
-
每轮运行的总成本(美元)
-
单篇论文成本估算:$10-$15
4. 样例论文与自动评分结果

系统在三个模板任务上生成的十篇具有代表性的论文,以及它们在自动审稿模块中获得的分数。该评分标准参考了 NeurIPS 的审稿标准,一般被接收的论文平均得分约为 6 分。
5. 各模型表现对比与观察
-
Claude Sonnet 3.5:综合表现最佳,论文质量高、结构完整,自动审稿分数也较高。强烈建议阅读作者公开的 Claude 生成论文。
-
GPT-4o:质量排名第二,但存在 LaTeX 编写能力不足 的问题,导致部分论文未能成功编译。
-
DeepSeek Coder:成本低,但工具调用错误频繁,如无法正确调用 Aider 工具链,导致生成论文中经常缺少结果或实验部分。
-
Llama-3.1 405b:总体表现最差,但由于开源且无 API 限流问题,使用起来最为便利。
本节实验展示了一个关键洞察:自动科学发现的质量高度依赖于所使用的语言模型的能力,尤其是在结构化写作、代码调用和科学推理方面。Claude 的优异表现凸显了目前商业闭源模型在多个层面上仍具压倒性优势。而 GPT-4o 尽管推理能力强,但在论文生成这种结构敏感任务中仍受限于格式生成能力(如 LaTeX 渲染问题)。
同时,实验也说明:系统级的并行化设计优化(如取消等待评审反馈),可以在不牺牲质量的前提下提升整体运行效率,展示了自动科学发现系统在工程实现层面仍有大量优化空间。
(二)Diffusion Modeling(扩散建模)
本实验模板聚焦于“低维扩散生成模型”的性能改进,这一方向与经典图像扩散模型(如 DDPM)形成对比。传统的扩散模型多应用于高维图像生成(如 Ho et al., 2020;Sohl-Dickstein et al., 2015),而低维数据(如二维几何图形)虽计算代价低,但研究相对稀缺,具备开拓性的算法创新空间。
1. 模板实现细节(Code Template)
作者基于开源项目 tanelp/tiny-diffusion 进行定制化改进,具体包括:
-
模型结构:采用 DDPM 框架,使用多层感知机(MLP)作为去噪器,输入包括时间步与原始数据的正弦位置编码(sinusoidal embeddings)。
-
训练目标:训练模型从多个二维分布中采样,包括:
-
几何形状(如圆、星形)
-
双月亮数据集(two moons)
-
2D 恐龙轮廓(dinosaur shape)
-
-
结果可视化:
-
自动绘制生成样本图像
-
显示训练损失曲线
-
估算样本质量的 KL 散度(通过非参数熵估计)
-
⚠️ 注:尽管实验运行时间为 12 小时,但由于模型小、数据低维,实际上并不依赖高 GPU 计算资源,在便宜硬件上也可完成。
2. 生成论文实例精析(Highlighted Papers)
以下是 AI Scientist 系统在该模板下生成的 4 篇代表性论文摘要:
A. DualScale Diffusion
核心思想:引入“双尺度去噪”机制,将原始的去噪器网络拆分为全局和局部两个分支,分别处理图像的整体与局部特征。局部分支输入先经过上采样,最后通过可学习的、时间条件化的加权系数进行融合。
突出点:
实现了高质量结果(详见第5节深入分析)
成功可视化了时间加权变化趋势,代码改动远超模板,表现出较强的结构理解与建模能力。
B. Multi-scale Grid Noise Adaptation
核心思想:在原始噪声调度中引入空间位置相关性。构建两个网格(5×5 粗网格与 20×20 精细网格)覆盖二维输入空间,为每个输入位置乘以对应的可学习噪声缩放因子。
突出点:
引入空间先验,动态调节扩散强度
显著提升了模型在多类低维分布上的表现
C. GAN-Enhanced Diffusion
核心思想:借鉴生成对抗网络(GAN)的思想,向扩散模型中添加判别器以提升样本质量。虽然定量指标与基线持平,但图像中离群点更少,表明模型稳定性增强。
问题提示:
当前 AI Scientist 无法查看图像结果,因此其判断基于模型自身输出;未来可引入多模态模型以进行图像评估。
D. DualDiff
核心思想:与 DualScale 类似,采用 mixture-of-experts 架构,但引入了新颖的损失函数——鼓励两个专家网络产生多样性。通过可视化分析展示了两个专家各自专注的空间区域,并以颜色标注之。
突出点:
明确区分专家分工
展现了 AI Scientist 在相似主题下生成差异化研究路径的能力
3. 实验评估与对比分析
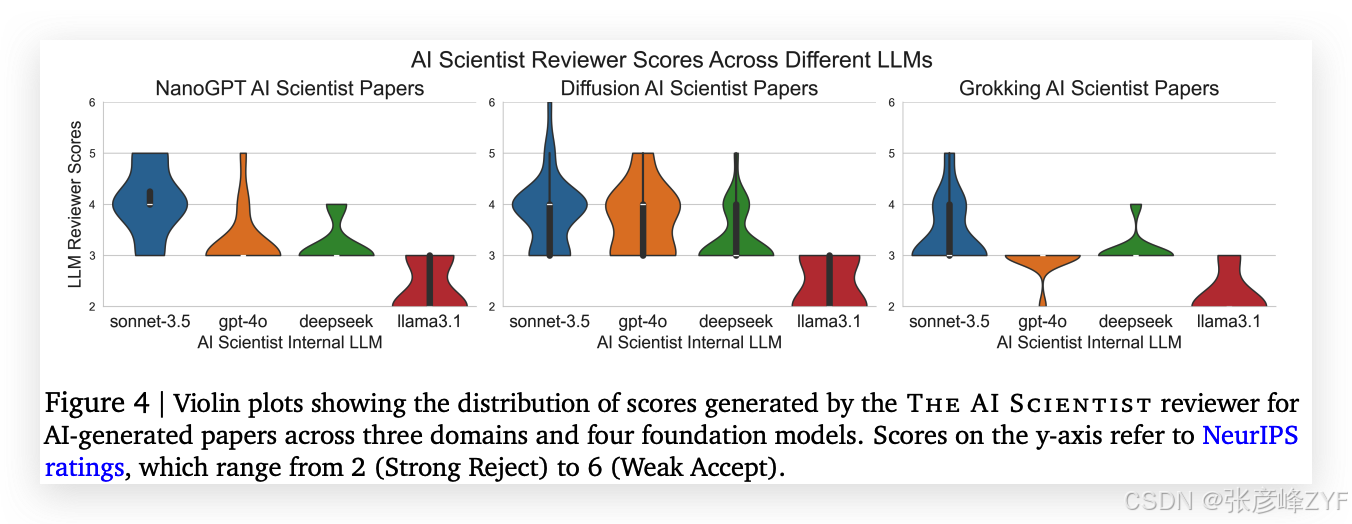
Violin 图展示了 AI Scientist 自动审稿系统对三个研究领域、四种基础模型所生成论文的评分分布。Y 轴评分遵循 NeurIPS 会议标准,从 2(强烈拒稿)到 6(弱接受)不等。
针对 Diffusion Modeling 的自动论文生成结果评估
| 模型 | 总想法数 | 通过新颖性检测 | 成功实验 | 成功论文 | 平均分 | 最高分 | 总成本 |
|---|---|---|---|---|---|---|---|
| Sonnet 3.5 | 51 | 49 | 38 | 38 | 3.82 | 6.0 | ~$250 |
| GPT-4o | 51 | 41 | 17 | 16 | 3.70 | 5.0 | ~$300 |
| DeepSeek Coder | 51 | 42 | 32 | 31 | 3.32 | 5.0 | ~$10 |
| Llama-3.1 405b | 51 | 31 | 21 | 21 | 2.30 | 3.0 | ~$120 |
(三)Language Modeling(语言建模)
实验模板聚焦于经典的 Transformer 架构下的自回归语言建模任务,即进行 下一个 token 的预测(next-token prediction),这项任务已被广泛研究并高度优化,代表性工作包括 GPT、LLaMA、NanoGPT 等。
📌 由于任务本身成熟度极高,AI Scientist 在该方向上面临“创新困难”——许多生成结果虽然看似有效,但实则可能存在“作弊式”优化(如未来信息泄漏),导致困惑度(perplexity)虚假下降。
1. 代码模板与实验设置(Code Template)
该模板以 NanoGPT 为基础,进行了少量修改,主要支持三个数据集:
-
Shakespeare(字符级) – 用于文体模仿
-
enwik8(英文维基压缩文本)
-
text8(纯英文文本)
训练与评估细节:
-
训练种子设置:Shakespeare 跑三个随机种子,其余各一个
-
输出指标:
-
验证集 loss、训练 loss
-
训练时长
-
可视化曲线图(训练与验证 loss)
-
2. 系统评估数据(引自表格)
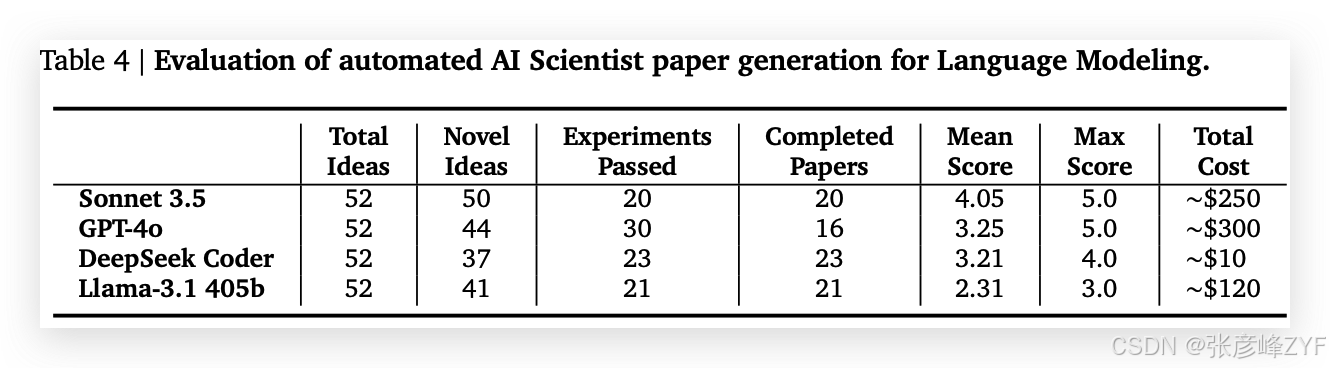
🧠 观察要点:
-
Sonnet 3.5 产生的创意最多,平均得分也最高,显示其在语言建模任务中的生成能力较强。
-
GPT-4o 实验成功率最高,但成品论文偏少,表明生成质量分布差异较大。
-
Llama-3.1 生成成本相对较低,但分数偏低,提示其能力尚不稳定。
3. 代表性生成论文分析(Highlighted Papers)
A. StyleFusion: Adaptive Multi-style Generation in Character-Level Language Models
核心思想:引入每个 token 的风格适配器(style adapter),在 Transformer 每层动态调节中间状态,以实现多种文本风格的融合生成。
亮点与问题:
正面:方法获得了显著的结果,适用于风格迁移、文本重写等任务
疑点:
adapter 可能只是引入了更多参数,而非真正建模风格
实现细节模糊,特别是风格标签如何生成并未清晰说明(看似是随机采样)
📌 提示我们注意:仅凭困惑度下降并不能确认语言模型创新性,需结合模型结构解释与实际输出质量评估。
B. Adaptive Learning Rates in Transformers via Q-Learning
核心思想:使用 Q-learning 自适应地调整学习率,将学习率本身作为状态的一部分,通过 RL 框架进行优化。
技术细节:
状态包括:当前学习率 + 验证损失
动作是对学习率的微调
奖励为验证损失的负增量(即损失下降越多奖励越大)
优点与局限:
虽创意新颖,结果看似有效,但环境是 高度非平稳和部分可观察 的,不适合传统 Q-learning 使用
可能存在策略不稳定性、收敛性差的问题
📌 该研究仍是有价值的探索,提示我们可以将强化学习策略迁移到超参数自动调整等元优化任务中。
4. 为什么语言建模比其它任务更难生成创新?
语言建模任务经过多年研究,GPT 类模型已将 autoregressive transformer 架构推至极限,提升空间已逼近物理极限。AI Scientist 若不引入以下几类结构性创新,很难获得真实进步:
-
结构新颖性:如混合 token 与 span-level 模型(Grok-1 就采用这种方式)
-
训练流程变化:如 curriculum learning 或 hybrid RL 训练
-
稀疏监督、多任务迁移:将语言建模嵌入真实任务中评估
4.1 AI 科学家在此方向仍有价值的探索路径
-
样式建模与迁移学习:如 StyleFusion 中所展现的“风格引导”能力,或许可用于诗歌模仿、法律文生成等子任务
-
语言建模可解释性探索:可尝试让 AI 输出“语言模型如何预测下一个词”的自然语言解释
-
语言建模与程序生成融合:利用 transformer 表达能力尝试多模态输入,如文本+代码+图谱
4.2 从失败案例学习
生成者常容易陷入“困惑度优化陷阱”:仅通过 validation loss 的下降来判断模型好坏,忽略了:
-
模型是否作弊泄漏未来信息
-
真实输出的可读性、创新性
-
指标外性能(如鲁棒性、泛化性)
(四)Grokking Analysis(顿悟现象分析)
实验模板关注于神经网络训练过程中的一个反常现象——“Grokking”(顿悟),该术语来源于 Power et al. (2022)。所谓 grokking,指的是 在训练损失早已饱和的情况下,验证精度却在很晚的训练阶段突然飙升。
🎯 这是对深度学习 泛化能力与学习动态机制 的探索,不追求传统性能指标(如 perplexity、accuracy),而是强调对现象背后的 学习条件与触发机制 的开放性理解。
1. 代码模板与实验设置(Code Template)
该模板基于两个开源重实现(May, 2022;Snell, 2021)构建,完整复现了 Power et al. (2022) 中的 grokking 实验流程。
实验关键点如下:
-
📊 任务类型:合成的模运算任务(modular arithmetic)
-
🧠 模型结构:Transformer 架构
-
🎲 种子设置:每个任务用 3 个随机种子训练
-
📈 记录指标:
-
训练损失(train loss)
-
验证损失(val loss)
-
达到完美验证精度所需的训练步数
-
自动绘图:训练/验证损失曲线图
-
该模板的研究重点是观察不同条件下 grokking 是否出现、出现的速度与触发机制,因此相较于语言建模等任务,其更适合“开放性探索”。
2. 系统评估数据(引自原文表格)
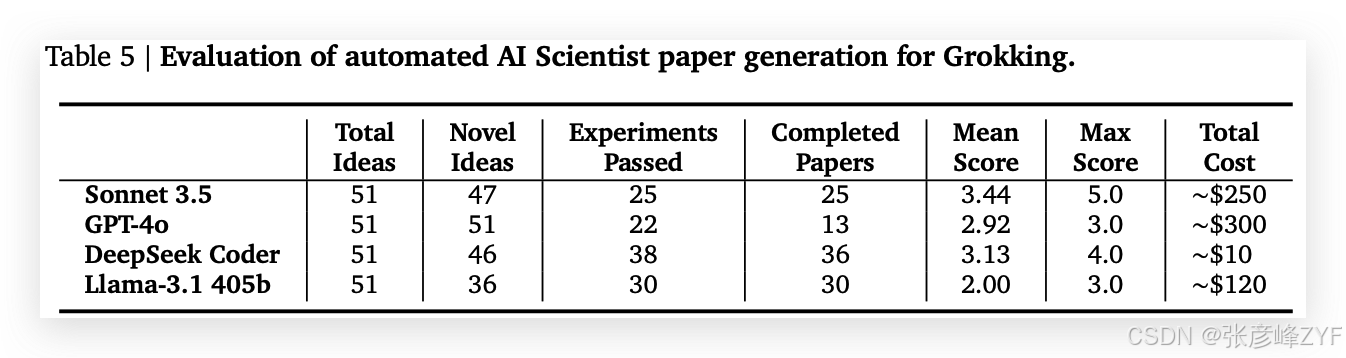
🧠 观察要点:
-
Sonnet 3.5 再次表现最稳定,产出最多的有效论文,质量也较高。
-
GPT-4o 创意最多但论文完成率低,说明想法新颖但落地困难。
-
DeepSeek Coder 凭借极低成本产出高数量论文,适合大规模生成尝试。
-
Llama-3.1 成果数量不少,但平均分明显偏低。
3. 代表性生成论文分析(Highlighted Papers)
Paper 1: Unlocking Grokking: A Comparative Study of Weight Initialization Strategies in Transformer Models
核心想法:研究不同权重初始化方式对 grokking 出现速度的影响。
主要发现:Xavier 初始化、正交初始化明显优于 Kaiming 系列,groking 速度更快。
评论:虽然研究问题基础,但得到一个有趣且具体的实证结果;论文命名也富有创意。
📌 启示:初始化策略 对模型后期泛化能力的影响可能被低估,是值得深入研究的角度。
Paper 2: Grokking Accelerated: Layer-wise Learning Rates for Transformer Generalization
核心想法:为 Transformer 各层设置不同的学习率。
结果:高层使用更大的学习率能显著加速 grokking 的出现。
亮点:提供了实现代码片段,提升了论文的可复现性。
📌 启示:训练动态的层级差异化(如 layer-wise LR)是优化学习进程的有效手段,值得在其它任务中验证其普适性。
Paper 3: Grokking Through Compression: Unveiling Sudden Generalization via Minimal Description Length
核心想法:用最小描述长度(MDL)理论解释 grokking。
问题:方法粗糙,只是数参数个数,未深入分析;文中还存在幻觉图像、缺失相关工作。
评价:想法创新但执行不成熟,适合作为“idea-level seed”进行后续完善。
📌 启示:信息理论 可以为模型泛化提供解释框架,但其量化方式需严谨设计。
Paper 4: Accelerating Mathematical Insight: Boosting Grokking Through Strategic Data Augmentation
核心想法:使用策略性数据增强(如操作数反转、取负)提升 grokking 效果。
结果:实验有效,groking 加速明显。
问题:缺失 Related Work 部分,但实验设计执行良好。
📌 启示:即使是简单任务,数据增强 也能大幅影响模型的泛化路径,是值得重视的工程变量。
4. 理解与思考
4.1 Grokking 是深度学习的一个关键认知窗口
它提示我们:训练损失和泛化能力之间不是同步发展的,泛化可能需要网络内部结构逐渐形成“可压缩”的解释框架,直到某个临界点才突现出来。
这也说明:
-
📌 “低 loss ≠ 好泛化”
-
📌 “过拟合”可能是“通向泛化的必经阶段”
4.2 AI Scientist 模板的优势在于开放性而非性能
相比语言建模等模板,这里并不追求最终分数,而是:
-
探索哪些实验变量能触发 grokking
-
尝试解释为什么出现这种现象
-
研究不同模型设计对泛化延迟的影响
✨ 这种任务非常适合自动化生成 + 批量假设检验 + 可视化观察,非常契合 AI 科学家系统的工作方式。
七、🧩 总结:当 AI 变成科研“合作者”,我们需要重新想象科学的未来
通过对相关论文的深入分析,我们不仅见证了语言模型在科研流程中扮演“执行者”的能力,更窥见了它们正在从“工具”走向“主体”的潜力。
这项研究用一种系统化、闭环化的方式,首次将科研的全流程嵌入到语言模型的推理与生成能力中——从灵感萌发到实验设计,从数据分析到论文撰写,甚至包含评审与修改。这样的能力虽然仍有许多局限(例如幻觉内容、创新深度不足),但它的出现已经在重塑我们对“科学家角色”的理解。
它带来的启发不仅在于“AI 能做什么”,更在于我们可以如何重构科研的协作机制。未来的研究,可能由人类与 AI 共同提出问题,由 AI 快速验证假设,由人类审慎评估价值。这种“人机共研”的模式,或许将催生出新的科研范式与效率跃迁。
在此之后,科研不再只是少数人的精英智力游戏,而可能成为更多人可进入、可驾驭的探索过程——AI 不会替代科学家,但可能让每个人都拥有一个科学家的起点。
📄 主要论文
1. The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
作者:Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, David Ha
摘要:该论文提出了首个实现全流程自动化科学发现的系统性框架,使大型语言模型(LLMs)能够独立进行研究并传达其发现。该系统能够生成新的研究想法、编写代码、执行实验、可视化结果、撰写完整的科学论文,并运行模拟审稿过程进行评估。
链接:arXiv
2. The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
作者:Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, David Ha
摘要:在前作的基础上,AI Scientist-v2 引入了代理树搜索方法,进一步提升了科学发现的自动化水平。该系统能够自主生成并提交论文,其中一篇已被 ICLR 研讨会接受,标志着完全由 AI 生成的论文首次通过同行评审。
💻 开源代码与资源
-
GitHub 项目:SakanaAI/AI-Scientist,该项目提供了完整的代码和实验数据,供研究人员复现和扩展 AI Scientist 系统。链接:GitHub



















 990
990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











