






ComfyUI 最近更新,引入了遮罩和调度 LoRA 及模型权重功能,让我们可以对图像生成的不同区域进行权重控制。
遮罩功能使特定 LoRA 和权重能应用于 CLIP 和调节,而调度功能允许这些权重动态变化。通过 Create Hook LoRA 等节点,用户能实现遮罩分区和权重调度,对复杂图像合成尤为重要。
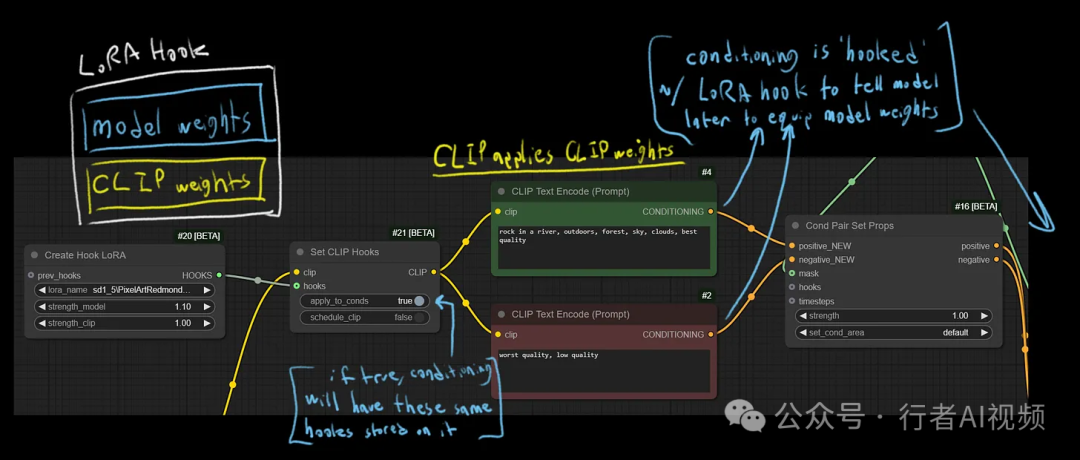
博客主页:https://blog.comfy.org/masking-and-scheduling-lora-and-model-weights/
先来看案例
先看一个分区生成的案例:生成图片时用了左右两个分区控制,左边控制主体,右边控制场景,左边分别输入不同的提示词。
左侧区域提示词:一张夜间拍摄的高分辨率照片,描绘了一位年轻女子坐在繁华城市的屋顶上。这名女子大概二十出头,皮肤白皙,身材苗条。她穿着一件合身的露肩红色连衣裙,突出了她的身材,黑色透明连裤袜突出了她的腿。她深色的头发扎成高马尾,穿着红色高跟鞋。她凝视着远方,表情沉思,带着一丝悲伤或内省。``右侧区域提示词:背景是充满活力的城市景观,有许多高楼大厦,被路灯和城市的夜灯照亮。一辆黄色出租车停在下面的街道上,几名行人沿着人行道行走,为现场增添了一种活动感。这些建筑融合了现代和古典建筑风格,玻璃窗反射着城市的光线。
生成的图片如下:
人物和背景使用写实 lora 的效果:

人物使用写实、背景使用动漫 lora 的效果:

效果是不是很赞,感兴趣的接着往下看。
ComfyUI 中使用
该插件,使用前需要将 ComfyUI 内核升级到最新版,否则无法正常使用。
想要实现上诉功能,大家先把 ComfyUI 内核升级到 0.3.7 版本。
更新版本后,可以在高级—hooks 中找到新增的节点。
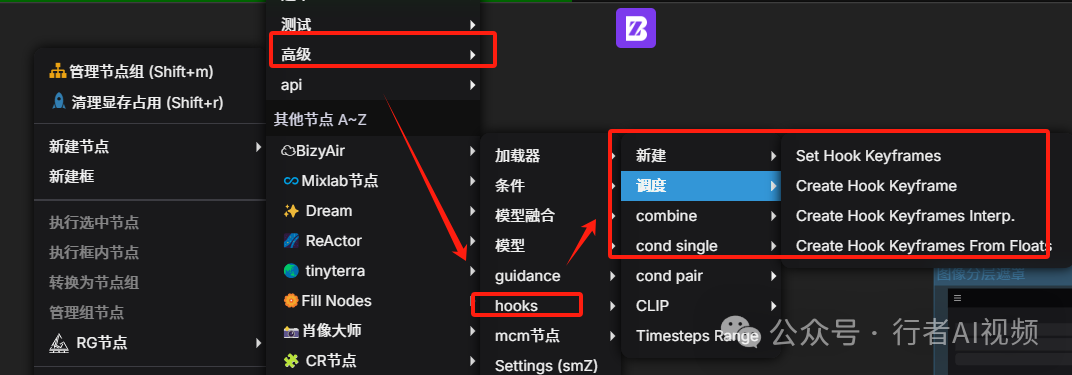
工作流 LIBLIB 平台地址:
https://www.liblib.art/modelinfo/121276edcd2f48c398c3ee334e6e0749?versionUuid=59fa66cb35a1442fadc49b3efa57e01e
工作流主界面:
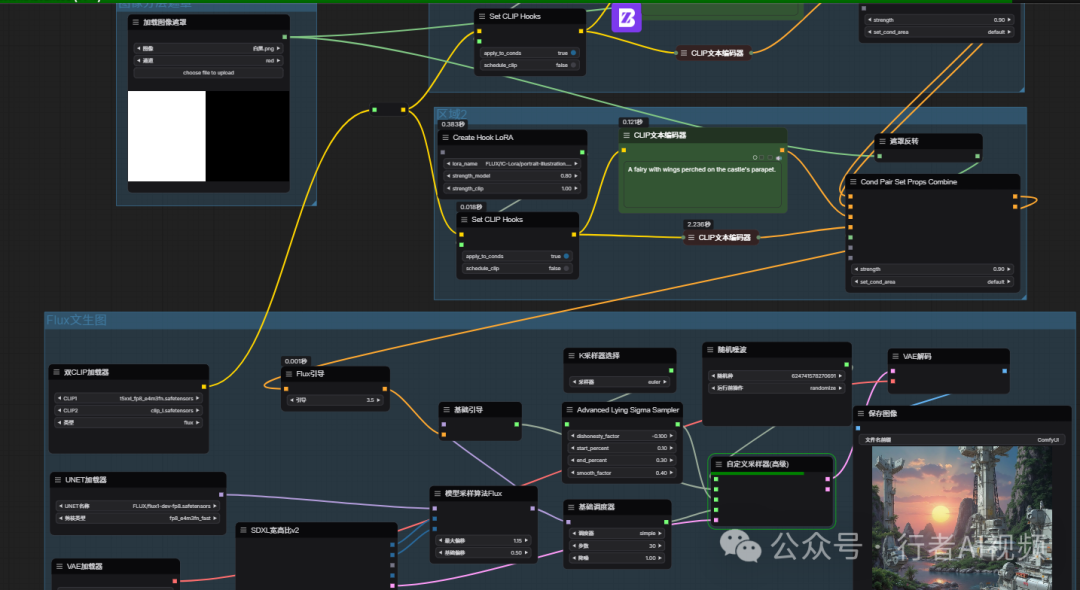
生图测试
左侧上传一张遮罩模版,右侧输入分区控制提示词,这两个区域可以使用不同风格的 lora,比如动漫和写实混合。
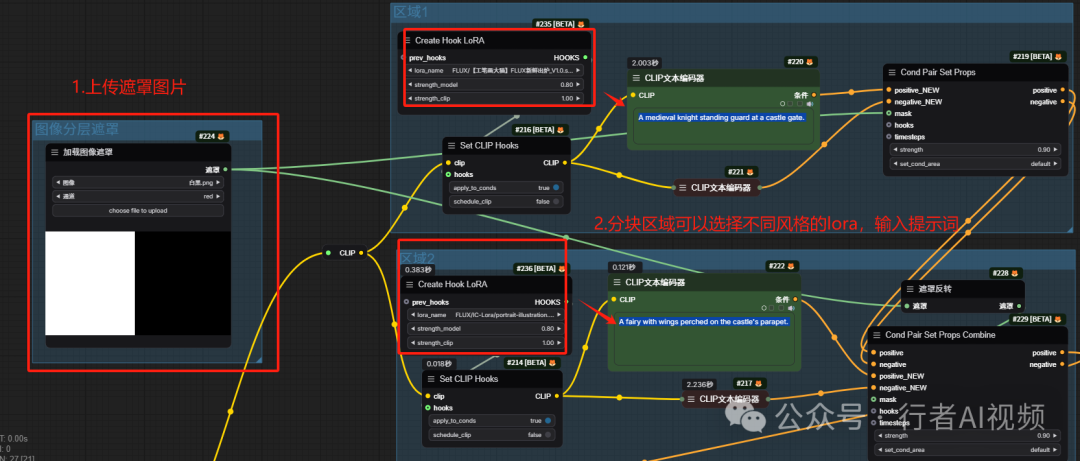
我使用的是 flux1-dev 模型,本地显卡低一些的可以使用 flux1-dev-fp8 模型。Lora 可以根据自己需求切换不同风格。
1)宇航员:
左侧提示词:A group of astronauts preparing for a spacewalk。
右侧提示词:The same astronauts gathered around a control panel in the space station。
左侧提示词:一群宇航员正在为太空行走做准备。
右侧提示词:同样的宇航员聚集在空间站的控制面板周围。

2)城镇广场:
左侧构图提示词:A bustling market in a historic European town square。
右侧构图提示词:A quiet, cobblestone alley leading to the same town square。
左侧构图提示词:历史悠久的欧洲城镇广场上熙熙攘攘的市场。
右侧构图提示词:一条安静的鹅卵石小巷,通往同一个城镇广场。

3**)森林麋鹿:**
左侧构图提示词:A serene forest with a deer drinking from a crystal-clear stream。
右侧构图提示词:A mystical cottage nestled deep within the same enchanted forest。
左侧构图提示词:一片宁静的森林,鹿在清澈的溪流中饮水。
右侧构图提示词:一座神秘的小屋坐落在同一片迷人的森林深处。

4**)宇宙飞船:**
左侧构图提示词:A futuristic cityscape at sunset。
右侧构图提示词:A retro-styled spaceship docked at a space station。
左侧构图提示词:日落时的未来主义城市景观。
右侧构图提示词:一艘复古风格的宇宙飞船停靠在空间站。

经过测试:
1.生成图片的时间蛮长的,我使用仙宫云 4090 显卡,运行生成一张图片的时间需要几分钟
2.本文中分别采用不同的 LORA 模型与提示词组结合,使用提示词描述不同的场景,而 LORA 可以不同权重或 LORAO 型,形成多样性的风格。如:动漫和写实结合等。
3.hooks 方案不仅适用于 Flux,也支持 SDXL 模型。
行者的 Flux 云端镜像
如果没有本地 ComfyUI 环境,或者本地显卡配置低于 16G 的,可以使用行者部署的仙宫云镜像,加载工作流直接使用。
镜像名称:行者 AI 绘画视频 ComfyUI 镜像
云平台地址:
镜像地址:https://www.xiangongyun.com/image/detail/2b6e9187-cb85-4ebd-89ee-00a19f83d1dd?r=1W8BDK
新用户通过邀请码注册,总共可获得 8 元奖励**,体验 4 个小时的 4090 作图时长。**
镜像包预置了主流的插件,内置了 FULX 多个模型和常用工作流,非常适合入门使用。
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









