



 本文介绍了EPSANet,一种通过引入金字塔切分注意力(PSA)模块提升卷积神经网络性能的新型网络结构。PSA模块利用多尺度信息建立通道注意力依赖,实现在图像识别和目标检测中的显著性能提升。EPSANet的即插即用性质使其在各种计算机视觉任务中具有广泛应用潜力。
本文介绍了EPSANet,一种通过引入金字塔切分注意力(PSA)模块提升卷积神经网络性能的新型网络结构。PSA模块利用多尺度信息建立通道注意力依赖,实现在图像识别和目标检测中的显著性能提升。EPSANet的即插即用性质使其在各种计算机视觉任务中具有广泛应用潜力。
EPSANet:一种高效的金字塔切分注意力网络
一、引言
在深度学习领域,注意力机制已经成为提升卷积神经网络性能的关键技术。其中,一种新型网络结构——EPSANet,通过引入金字塔切分注意力(Pyramid Split Attention, PSA)模块,为注意力机制的研究和应用提供了新的思路。EPSANet不仅在图像识别任务中表现出色,还在计算参数量上实现了高效性。
二、PSA模块的设计
PSA模块的核心思想在于利用多尺度的输入特征图,提取并整合不同尺度的空间信息,从而建立多尺度通道注意力间的长期依赖关系。具体设计包括以下几个关键步骤:
- 分组:将输入特征图按照通道数进行分组,以便在不同尺度上并行处理。
- 卷积核大小变化:针对不同尺度的分组,使用不同大小的卷积核进行卷积操作,以捕获不同尺度的空间信息。
- 特征图拼接:将不同尺度上的特征图进行拼接,以融合多尺度信息。
- SE模块提取通道加权值:通过SE(Squeeze-and-Excitation)模块学习每个通道的权重,实现对通道注意力的调整。
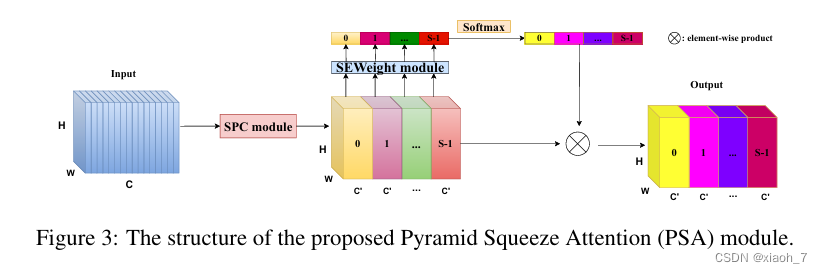
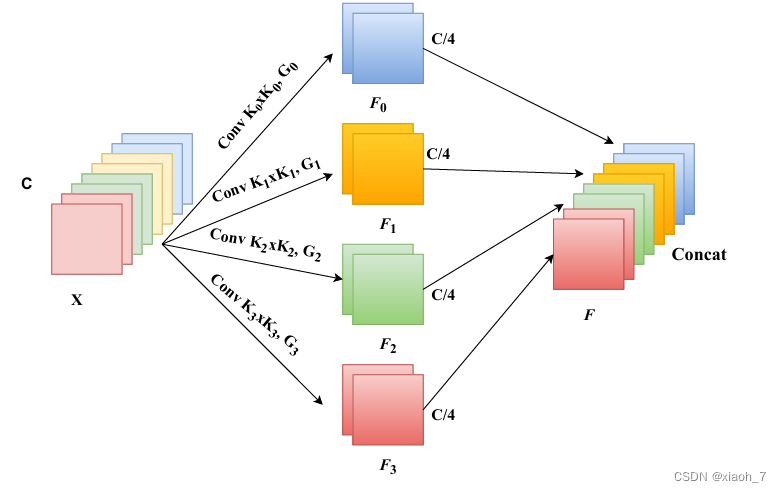
这种设计使得EPSANet能够以较低的模型复杂度学习注意力权重,并整合局部和全局注意力,建立长期的通道依赖关系。
三、EPSANet的性能
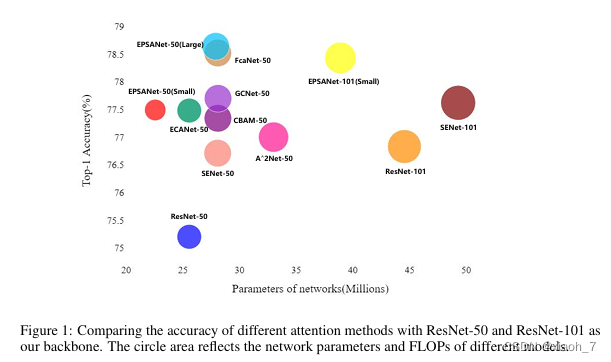
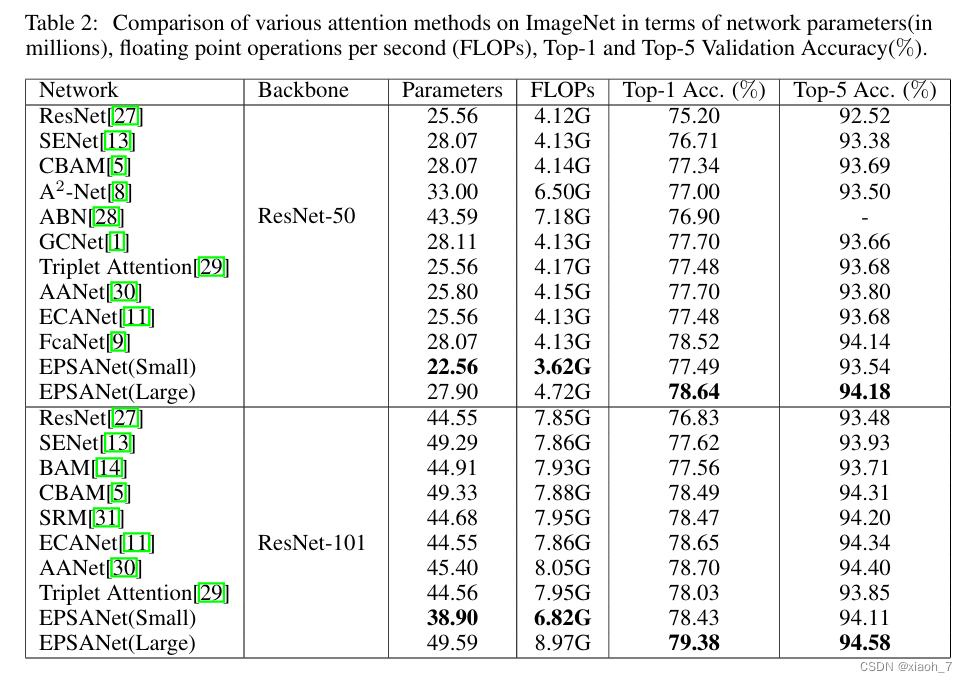
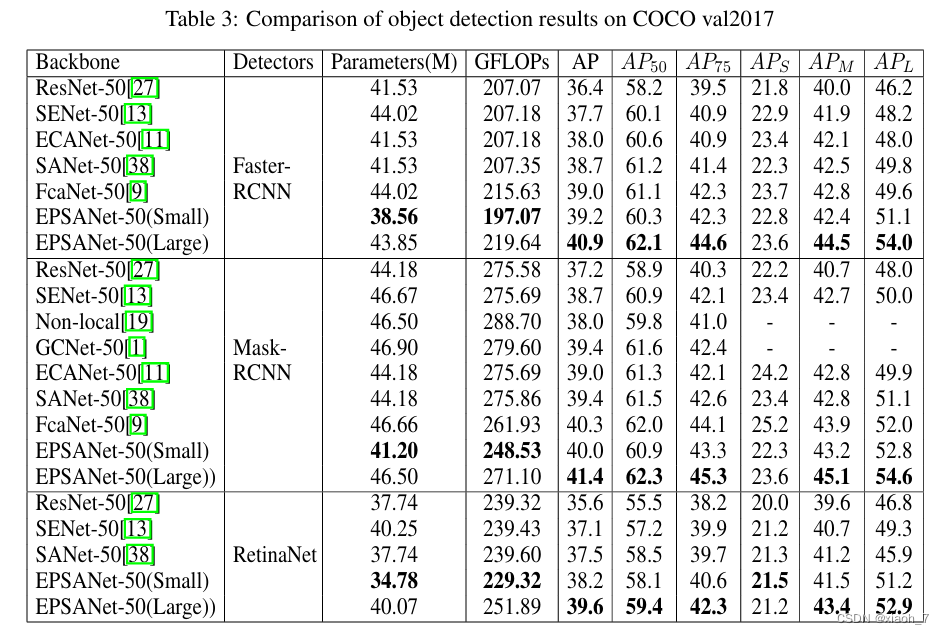
EPSANet在多个数据集上表现出色,尤其是在图像识别任务中。与SENet-50相比,EPSANet在ImageNet数据集上的Top-1准确率提高了1.93%。此外,在MS-COCO数据集上使用Mask-RCNN时,EPSANet的目标检测box AP提高了2.7,实例分割的mask AP提高了1.7。这些结果充分证明了EPSANet在提升模型性能方面的有效性。
即插即用的设计,EPSA模块具有即插即用的特性,可以轻松添加到现有的骨干网络中,无需复杂的修改即可获得显著的性能提升。这种设计理念使得EPSANet能够方便地应用于各种计算机视觉任务,为实际应用提供了极大的便利。
四、相关代码(pytorch)
import torch
import torch.nn as nn
class SEWeightModule(nn.Module):
def __init__(self, channels, reduction=16):
super(SEWeightModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(channels, channels//reduction, kernel_size=1, padding=0)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(channels//reduction, channels, kernel_size=1, padding=0)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.avg_pool(x)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
weight = self.sigmoid(out)
return weight
def conv(in_planes, out_planes, kernel_size=3, stride=1, padding=1, dilation=1, groups=1):
"""standard convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=False)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class PSAModule(nn.Module):
def __init__(self, inplans, planes, conv_kernels=[3, 5, 7, 9], stride=1, conv_groups=[1, 4, 8, 16]):
super(PSAModule, self).__init__()
self.conv_1 = conv(inplans, planes//4, kernel_size=conv_kernels[0], padding=conv_kernels[0]//2,
stride=stride, groups=conv_groups[0])
self.conv_2 = conv(inplans, planes//4, kernel_size=conv_kernels[1], padding=conv_kernels[1]//2,
stride=stride, groups=conv_groups[1])
self.conv_3 = conv(inplans, planes//4, kernel_size=conv_kernels[2], padding=conv_kernels[2]//2,
stride=stride, groups=conv_groups[2])
self.conv_4 = conv(inplans, planes//4, kernel_size=conv_kernels[3], padding=conv_kernels[3]//2,
stride=stride, groups=conv_groups[3])
self.se = SEWeightModule(planes // 4)
self.split_channel = planes // 4
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
batch_size = x.shape[0]
x1 = self.conv_1(x)
x2 = self.conv_2(x)
x3 = self.conv_3(x)
x4 = self.conv_4(x)
feats = torch.cat((x1, x2, x3, x4), dim=1)
feats = feats.view(batch_size, 4, self.split_channel, feats.shape[2], feats.shape[3])
x1_se = self.se(x1)
x2_se = self.se(x2)
x3_se = self.se(x3)
x4_se = self.se(x4)
x_se = torch.cat((x1_se, x2_se, x3_se, x4_se), dim=1)
attention_vectors = x_se.view(batch_size, 4, self.split_channel, 1, 1)
attention_vectors = self.softmax(attention_vectors)
feats_weight = feats * attention_vectors
for i in range(4):
x_se_weight_fp = feats_weight[:, i, :, :]
if i == 0:
out = x_se_weight_fp
else:
out = torch.cat((x_se_weight_fp, out), 1)
return out
# 测试PSA模块
if __name__ == '__main__':
model = PSAModule(inplans=384, planes=384).cuda() # 创建测试模块
input = torch.rand(3, 384, 64, 64).cuda() # 创建随机输入数据
output = model(input) # 前向传播
print(output.shape)
五、结论
EPSANet作为一种高效的金字塔切分注意力网络,通过引入PSA模块,实现了对多尺度空间信息的有效处理和整合。其出色的性能和即插即用的设计使得EPSANet在深度学习领域具有广泛的应用前景。随着研究的深入,我们期待看到更多基于EPSANet的应用和改进,为计算机视觉领域带来更多的创新和突破。
参考资料
论文:EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network
版权声明
本博客内容仅供学习交流,转载请注明出处。

















 1271
1271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









