







EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network
目录
3.1 Revisting Channel Attention
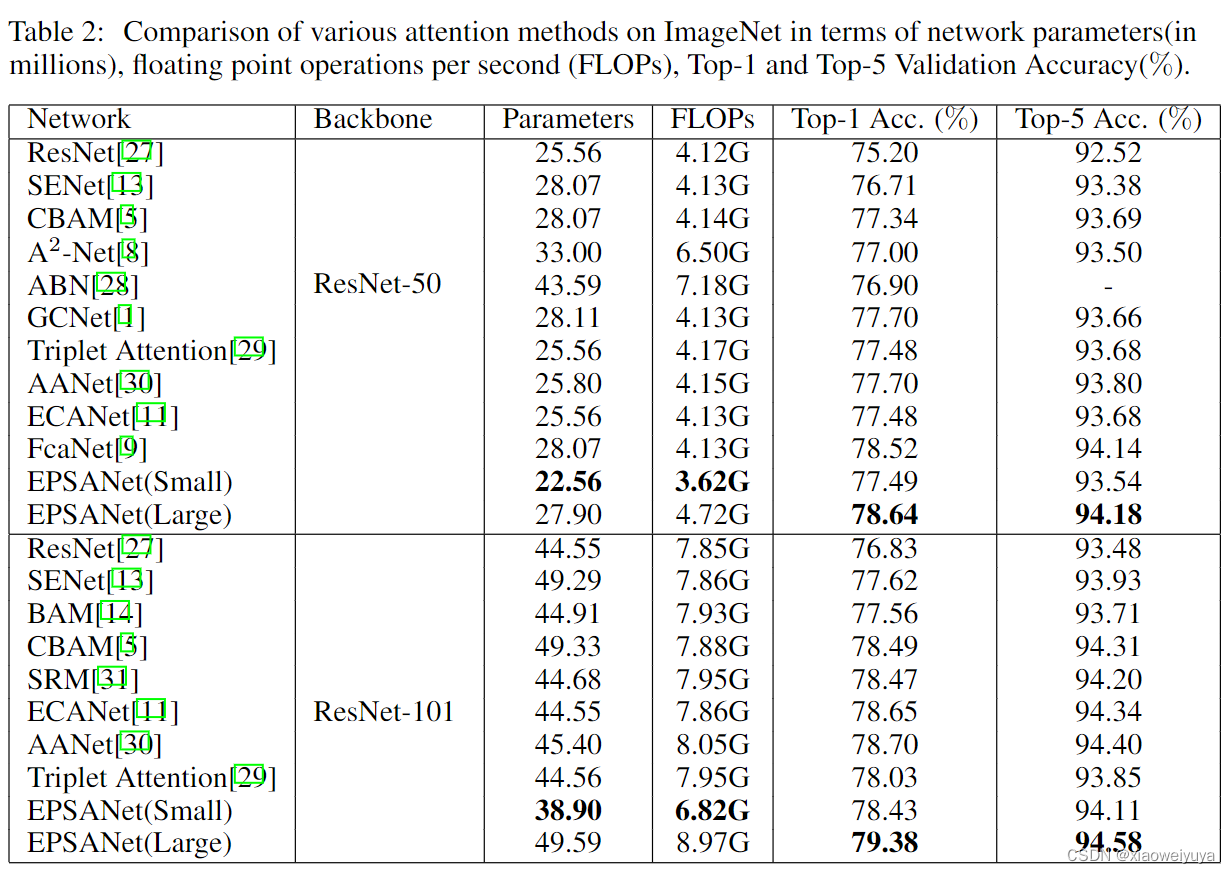
Image Classification on ImageNet
Abstract
最近,已经证明,通过将注意力模块嵌入其中,可以有效地提高深度卷积神经网络的性能。 在这项工作中,提出了一种名为 Pyramid Squeeze Attention (PSA) 模块的新型轻量级且有效的注意力方法。 通过在 ResNet 的bottleneck块中用 PSA 模块替换 3x3 卷积,获得了一个名为 Efficient Pyramid Squeeze Attention (EPSA) 的新型表示块。 EPSA 模块可以作为即插即用组件轻松添加到完善的骨干网络中,并且可以显着提高模型性能。 因此,通过堆叠这些 ResNet 风格的 EPSA 块,在这项工作中开发了一个简单而高效的主干架构 EPSANet。
相应地,所提出的 EPSANet 可以为各种计算机视觉任务提供更强的多尺度表示能力,包括但不限于图像分类、对象检测、实例分割等。没有花里胡哨,所提出的 EPSANet 的性能优于 大多数最先进的通道注意方法。 与 SENet-50 相比,ImageNet 数据集的 Top-1 准确率提高了 1.93%,通过在MS-COCO数据集上使用MASK-RCNN,获得了更大的+2.7 box AP用于目标检测和+1.7 mask AP用于实例分割的改进。
Introduction
注意机制被广泛应用于许多计算机视觉领域,如图像分类、目标检测、实例分割、语义分割、场景解析和动作定位[1,2,3,4,5,6,7]。具体来说,有两种注意方法,即通道注意和空间注意。最近,研究表明,通过使用通道注意、空间注意或两者同时使用,可以显著提高性能[PCANet, ECANet, ResNest]。最常用的通道关注力方法是 Squeeze-andExcitation(SE)模块[13],该模块可以以相当低的成本显著提高性能。SENet的缺点是忽略了空间信息的重要性。为此,提出Bottleneck注意模块(BAM)[14]和卷积块注意模块(CBAM)[5],通过有效结合空间注意和通道注意来丰富注意图。
然而,仍然存在两个重要且具有挑战性的问题。 第一个是如何有效地捕获和利用不同尺度的特征图的空间信息来丰富特征空间。 第二个是通道或空间注意力只能有效地捕获局部信息,而无法建立远程通道依赖关系。 相应地,提出了许多方法来解决这两个问题。 提出了基于多尺度特征表示和跨通道信息交互的方法,如PyConv [15]、Res2Net [16]和HS-ResNet [17]。另一方面,可以如 [2, 18, 19] 所示建立远程信道依赖关系。 然而,上述所有方法都带来了更高的模型复杂度,因此网络承受着沉重的计算负担。 基于上述观察,我们认为有必要开发一个低成本但有效的注意力模块。 在这项工作中,提出了一种名为 Pyramid Squeeze Attention (PSA) 的低成本高性能新型模块。提出的PSA模块具有处理多尺度输入张量的能力。具体来说,利用多尺度金字塔卷积结构对输入特征图的信息进行整合。同时,通过压缩输入张量的通道维数,可以有效地从每个通道特征图中提取不同尺度的空间信息。通过这样做,可以更精确地合并上下文特征的相邻尺度。最后,通过提取多尺度特征图的通道注意权重来构建跨维度交互。采用Softmax操作重新校准相应信道的注意力权重,从而建立长期信道依赖关系。在此基础上,将ResNet bottleneck块中的3x3卷积模块替换为PSA模块,得到了一个新的模块——Efficient Pyramid Squeeze Attention (EPSA)。此外,通过将这些EPSA块按ResNet样式堆叠,提出了一种名为EPSANet的网络。如图1所示,所提议的EPSANet不仅在Top-1准确性方面优于现有技术,而且在所需参数方面也更有效。
Contributions
- 提出了一种新颖的 Efficient Pyramid Squeeze Attention (EPSA) 块,它可以有效地提取更细粒度的多尺度空间信息,并发展远程通道依赖性。 所提出的 EPSA 块非常灵活且可扩展,因此可以应用于各种网络架构,以完成众多计算机视觉任务。
- 提出了一种名为 EPSANet 的新型主干架构,它可以学习更丰富的多尺度特征表示,并自适应地重新校准跨维度通道注意权重。
- 大量实验表明,所提出的 EPSANet 可以在 ImageNet 和 COCO 数据集上的图像分类、对象检测和实例分割方面取得有希望的结果。
Method
3.1 Revisting Channel Attention
Channel attention
通道注意机制允许网络有选择地对每个通道的重要性进行加权,从而产生更多的信息输出。设为输入特征图,其中H、W、C分别表示其高度、宽度、输入通道数。一个SE block由两部分组成:squeeze 和 excitation,分别用于编码全局信息和自适应地重新校准信道关系。通常,可以使用全局平均池化来生成通道统计信息,该池化用于将全局空间信息嵌入到通道描述符中。 全局平均池化算子可以通过以下等式计算:
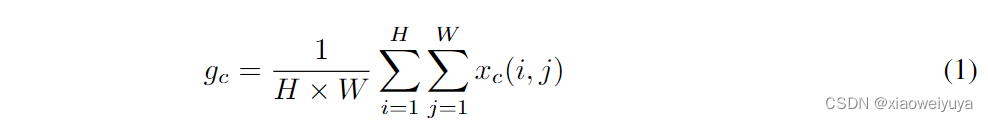
SE块中第c个通道的注意权重可以写为 :

符号代表RELU操作,
和
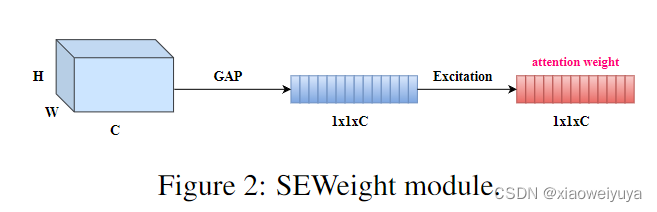
代表全连接层。通过两个全连接层,可以更有效地组合通道间的线性信息,有利于通道高维和低维信息的交互。 符号 σ 表示激励函数,实际中通常使用 Sigmoid 函数。 通过使用激励函数,我们可以在通道交互之后为通道分配权重,从而可以更有效地提取信息。 上面介绍的生成通道注意力权重的过程在SENet中被命名为SEWeight模块,SEWeight模块的示意图如图2所示。
3.2 PSA Module
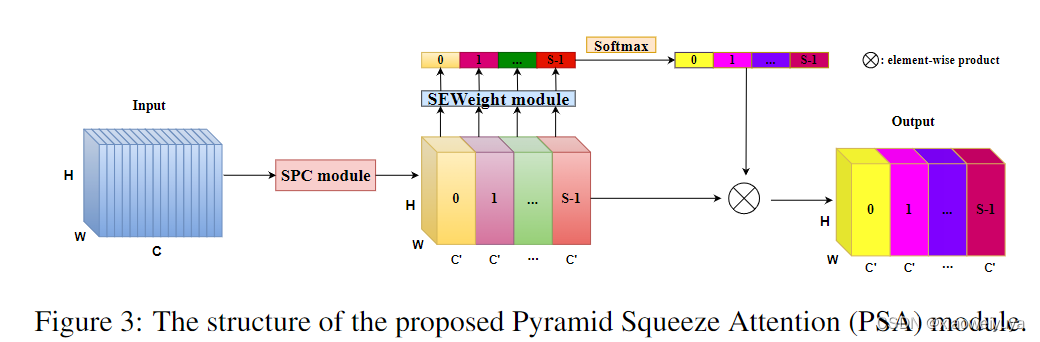
这项工作的动机是建立一个更高效和有效的通道注意力机制。 因此,提出了一种新的pyramid squeeze attention(PSA)模块。 如图 3 所示,PSA 模块主要分四个步骤实现。 首先,通过所提出的 Squeeze and Concat (SPC) 模块获得通道方面的多尺度特征图。 其次,通过使用 SEWeight 模块提取不同尺度的特征图的注意力,获得通道级注意力向量。 第三,通过使用Softmax重新校准channel-wise attention向量,获得多尺度通道的重新校准权重。 第四,将元素乘积的操作应用于重新校准的权重和相应的特征图。 最后,可以获得更丰富的多尺度特征信息的细化特征图作为输出。
如图4所示,在提出的PSA中实现多尺度特征提取的基本算子是SPC,我们以多分支的方式提取输入特征图的空间信息,每个分支的输入通道维度为 C。通过这样做,我们可以获得更丰富的输入张量的位置信息,并在多个尺度上并行处理。这样就可以得到一个包含单一类型内核的特征映射。相应地,可以通过在金字塔结构中使用多尺度卷积核可以生成不同的空间分辨率和深度。 并且通过压缩输入张量的通道维度,可以有效地提取每个通道特征图上不同尺度的空间信息。
最后,每个不同尺度Fi的feature map具有共同的信道维数 且
。需要注意的是,C可以被s整除,对于每个分支,它独立学习多尺度空间信息,并以局部的方式建立跨通道交互。但是,随着内核大小的增加,参数的数量将得到巨大的改进。为了在不增加计算代价的情况下处理不同核尺度下的输入张量,引入了一种组卷积方法,并将其应用于卷积核。在此基础上,我们设计了一种新的准则,在不增加参数数目的情况下选择组的大小。多尺度核大小与组大小的关系为:

K是核的大小,G是组的大小,上述等式已通过我们的消融实验得到验证,特别是当 k × k 等于 3 × 3 且 G 的默认值为 1 时。最后,多尺度特征图生成函数由下式给出:
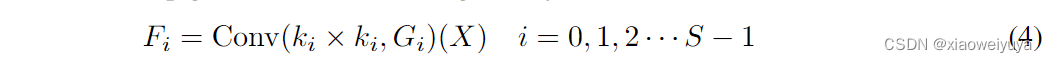 第i个核大小ki = 2×(i+1)+1 ,第i组group大小
第i个核大小ki = 2×(i+1)+1 ,第i组group大小,不同尺度的特征图
。整个多尺度预处理特征图可以通过concat的方式获得:

为得到的多尺度特征图。通过从多尺度预处理特征图中提取通道注意力权重信息,得到不同尺度的注意力权重向量。 在数学上,注意力权重的向量可以表示为:
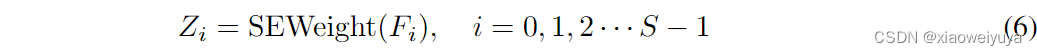
是注意力权重,SEWeight 模块用于从不同尺度的输入特征图中获取注意力权重。 通过这样做,我们的 PSA 模块可以融合不同尺度的上下文信息,并为高级特征图产生更好的像素级注意力。 进一步,为了实现注意力信息的交互,在不破坏原始通道注意力向量的情况下融合交叉维度向量。 因此,整个多尺度通道注意向量以concat方式获得为:
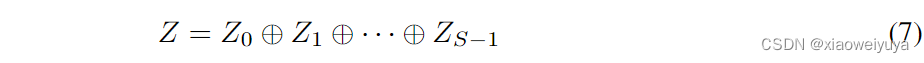
表示concat操作,Zi是从Fi中获得的注意力值,Z是多尺度注意力权重向量。跨通道使用软注意力来自适应地选择不同的空间尺度,这是由紧凑的特征描述符 Zi 引导的。 软分配权重由下式给出:
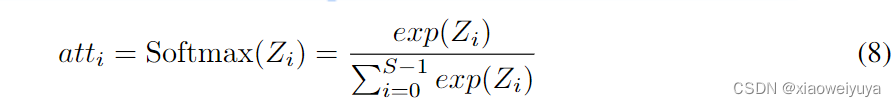
其中Softmax用于获取多尺度信道的重校准权重atti,其中包含了空间上的所有位置信息和通道中的注意权重。通过这样做,实现了本地和全局注意力之间的交互。然后对特征重标定的通道注意进行concat融合,得到整个通道注意向量为:
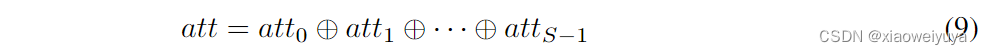
其中att为注意交互后的多尺度通道权值。然后,我们将多尺度通道注意力atti的重标定权值与对应尺度的特征图Fi相乘 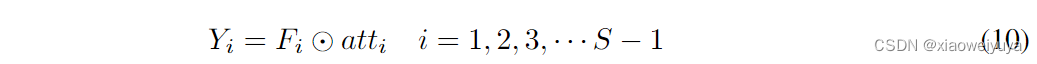
代表通道级乘法,Yi为获得了多尺度channel-wise注意权重的feature map。Concat操作比sum求和更加有效因为它可以在不破坏原始特征图信息的情况下整体保持特征表示。 总之,获得精细化输出的过程可以写成:
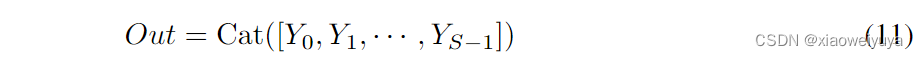
如上述分析所示,我们提出的PSA模块可以将多尺度空间信息和跨通道注意力整合到每个特征组的块中。因此,我们提出的PSA模块可以更好地实现局部和全局通道注意之间的信息交互。
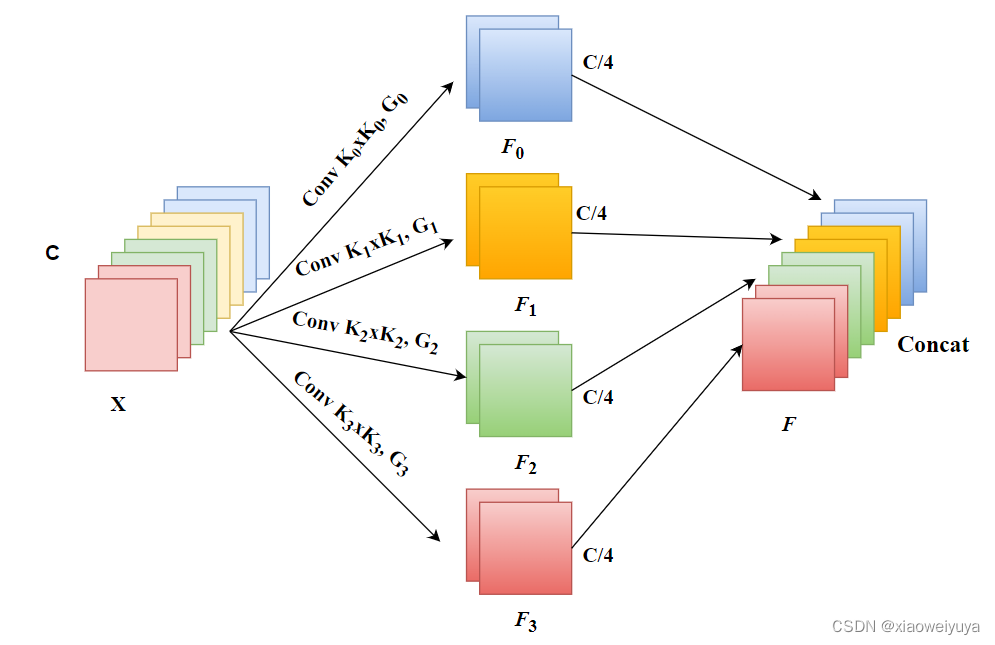
*图4:详细说明S=4时提出的Squeeze and Concat (SPC)模块,其中“Squeeze”表示在通道维度上相等地挤压,K是内核大小,G是组大小,“Concat”表示在通道维度上连接特征。
3.3 Network Design
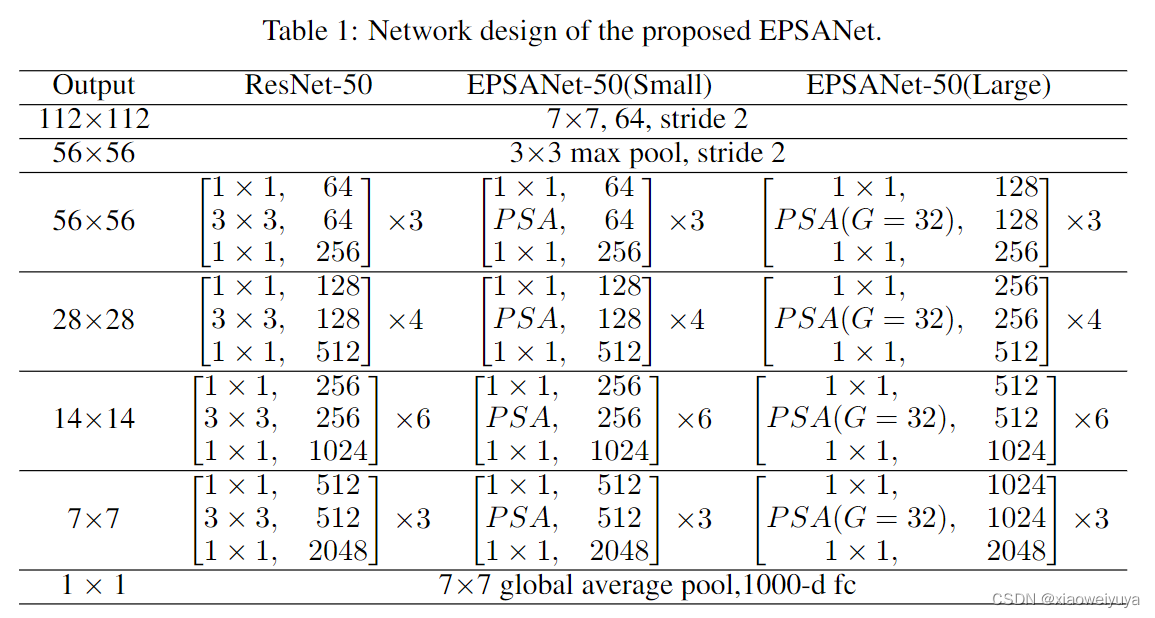
如图5所示,在ResNet bottleneck块的相应位置,将3x3卷积替换为PSA模块,得到了一个新的块,名为 Efficient Pyramid Squeeze Attention( EPSA)块。我们的PSA模块将多尺度空间信息和跨通道注意信息集成到EPSA块中。因此,EPSA块可以在更细粒度的层次上提取多尺度空间信息,并形成长程通道依赖性。相应的,将提出的EPSA块按照ResNet的方式进行堆叠,形成了一种新的高效骨干网络EPSANet。所提出的 EPSANet 继承了 EPSA 块的优点,因此它具有强大的多尺度表示能力,并且可以自适应地重新校准跨维度的通道权重。如表1所示,EPSANet的两种变体,EPSANet(Small)和EPSANet(Large)被提出。对于提出的EPSANet(Small), SPC模块的内核大小和分组大小分别设置为(3,5,7,9)和(1,4,8,16)。建议的EPSANet(Large)具有更高的群组大小,在SPC模块中设置为(32,32,32,32)
Experiments
Image Classification on ImageNet
Object Detection on MS COCO
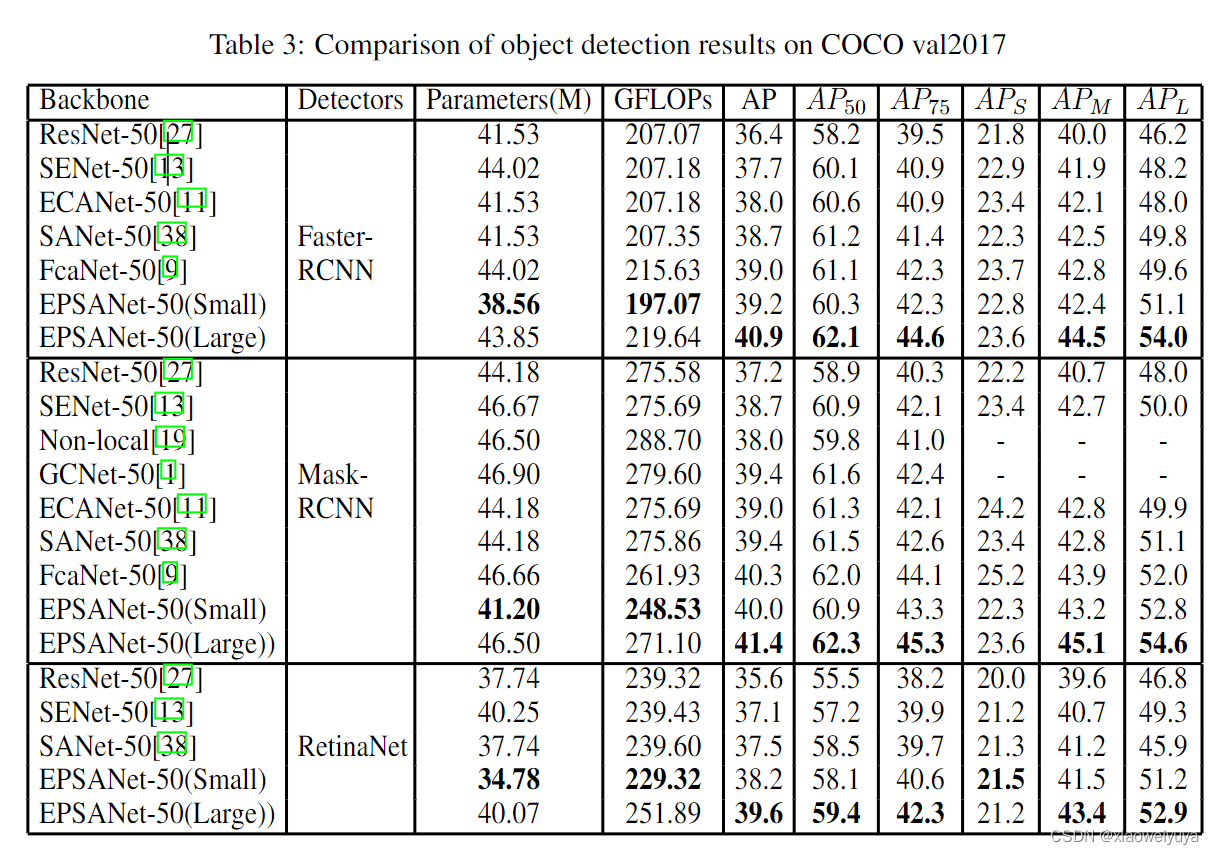
如表3所示,我们提出的模型可以实现目标检测任务的最佳性能。与ImageNet上的分类任务类似,提出的EPSANet-50(Small)在参数更少和计算成本更低的情况下比SENet-50表现得更好。EPSANet-50(Large)与其他注意方法相比,效果最好。从复杂性(参数和FLOPs)的角度来看,EPSANet-50(Small)与SENet50相比具有较高的竞争性能,即在Faster-RCNN、Mask-RCNN和retina et上的包围盒AP分别高出1.5%、1.3%和1.1%。此外,与SENet50相比,EPSANet-50(Small)在Faster RCNN、Mask RCNN和RetinaNet上的参数数量可进一步减少到87.5%、88.3%和86.4%。与ResNet-50相比,EPSANet-50(Large)能够在上述三个探测器上提高大约4%的平均精度。值得注意的是,最引人注目的性能改进出现在的测量中。在计算复杂度几乎相同的情况下,与FcaNet相比,我们提出的EPSANet-50(Large)在fast - rcnn和Mask-RCNN检测器上的AP性能分别提高了1.9%和1.1%。结果表明,所提出的EPSANet具有良好的泛化能力,可以很容易地应用于其他下游任务。
Ablation Study
Kernel and Group sizes
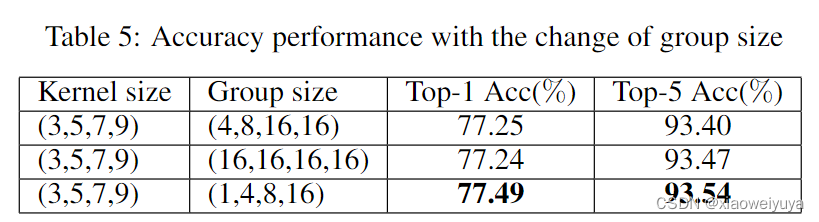
如表5所示,我们调整组的大小,以验证我们的网络在ImageNet[32]数据集上的有效性。并行地增加内核大小将导致参数量的显著增加。为了在不增加计算量的情况下充分利用空间域多尺度的位置信息,我们对不同尺度的特征图单独应用群卷积。通过适当调整组的大小,可以使参数的数量和计算代价减少一个因子,该因子等于子组的数量。如表5所示,我们提出的EPSANet可以在性能和模型复杂性之间取得良好的平衡。

















 2435
2435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









