






写在前面:
伴着《似夜流月》,已到七月下旬。黄宁然,看你看过的算法系列,就要完结了。
参考文献镇楼:
[1] 扫地机器人
[2]徐征辉,基于BRIEF描述子的特征点匹配系统
[3]zhaocj,Opencv2.4.9源码分析——BRIEF
注:csdn发文助手提示“外链过多”,故文献链接网址请见评论区。
问题来源:
笔者的执念。
1、原理简介
在求出图像的关键点后,需要对关键点做出描述,以便进行后续的图像匹配。SIFT描述子具备抗噪声、光照不变、尺度旋转不变的特性,SURF亦是对SIFT的改进。但SIFT、SURF选择的特征点描述符结构较为复杂,描述符的维数多且采用浮点格式,嵌入式平台下处理能力、存储能力均受限[1]。基于二进制位串的BRIEF、ORB描述子可以较好解决上述问题。
BRIEF(Bianry Robust Independent Elementary Features)由Calonder M 等人于2010年提出。BRIEF 算法以检测到的特征点为中心,通过选取符合高斯分布的点对进行像素强度的对比,将对比的结果记录为二进制字符串,这个二进制字符串就称为该特征点的 BRIEF 描述子。两个二进制 BRIEF 描述子之间可以通过计算它们的汉明距离(Hamming Distance)来判断描述子是否匹配,这样简化了描述子匹配过程,也加快了描述子匹配的速度[2]。
BRIEF描述子的主要步骤为:
(1)对原始图像进行平滑处理
(2)选取以目标点为中心的S*S正方形区域作为采样窗口
(3)在采样窗口内,选择
n
d
n_d
nd组点对,对每一组点对,进行下式的运算:
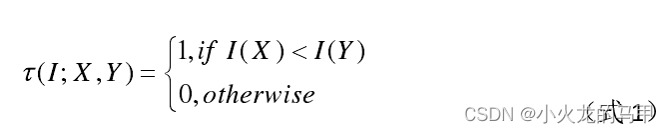
I是平滑处理后的图像,X、Y分别是以目标点为中心的S*S区域内的坐标位置。
(4)将每组点对得到的τ串起来(形成二进制数据流),得到BRIEF描述子:
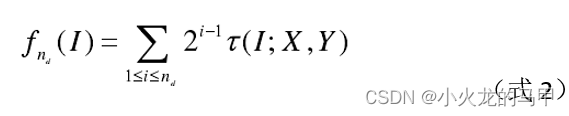
具体的,参考opencv源码brief.cpp文件以及文献3,首先以特征点为中心,选取S*S中的区域,opencv源码中S取48(代码中为PATCH_SIZE);然后在该区域内,选择
n
d
n_d
nd个像素点对,按照式(1)进行比对。从opencv源码中可看出,式(1)中的I,取的是KERNEL_SIZE为9的方形区域内所有像素之和。
2、python源码实现
参阅opencv源码brief.cpp文件,自行编写brief算子
#coding=utf8
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import math
import cv2
import os,sys
import scipy.ndimage
import time
import scipy
import re
from pygame import Rect
PATCH_SIZE = 48 #对每一个关键点,在48*48矩形区域内,形成比较点对
KERNEL_SIZE = 9 #对每一个比较点,求该点9*9区域内的像素和
从opencv原始代码中,找到generated_16.i(或generated_32.i)文件,并修改其后缀变成.txt文件。该文件中定义了比较点对的位置。通过读取该文件,筛选出比较点对,供后续使用。
def get_pt_lines(rawstr):#从原始txt文档中,获取比较点对
lines = rawstr.split(";")
pt_bytes = []
for l in lines: #对于所有行中的每一行
pt_byte=get_pt_line(l)#提取每一行的点对
if len(pt_byte)!=0:
pt_bytes.append(pt_byte)#保存点对
return pt_bytes
def get_pt_line(line):#从原始文件的每一行中,提取出比较点对,每一行8个点对,对应一个字节
line = line.replace(" ","")#删除空格
blocks = line.split("+")#按‘+’进行分割
pts=[]
for b in blocks:
str1 = re.findall("\(SMOOTHED\((.+?)\)<SMOOTHED",b)#匹配关键字副
str2 = re.findall("<SMOOTHED\((.+?)\)\)", b) #匹配关键字副
if str1!=[] and str2!=[]:
str1 = str1[0].split(',')
str2 = str2[0].split(',')
num1 = np.array(str1).astype(int)#得到左边数字
num2 = np.array(str2).astype(int)#得到右边数字
pts.append((num1,num2)) #保存点对
return pts #返回点对数组,8个点对
在上文描述中,算子整个过程涉及到两个矩形框,PATCH_SIZE和KERNEL_SIZE,对于原始的关键点,需要对位置越界的关键点进行剔除。
def runByImageBorder(kps,img_src,border_size):#剔除越界的关键点
r = Rect(border_size,border_size,img_src.shape[1]-border_size,img_src.shape[0]-border_size)
newkp=[]
for kp in kps:
x,y = kp.pt
if x >= r[0] and y >= r[1] and x < r[2] and y < r[3]:
newkp.append(kp)
return newkp
公式(1)中I的是求取中心位置附近KERNEL_SIZE大小区域的像素之和,为便于实现,使用积分图像作为函数输入参数,代码实现为:
def get_sum_from_integral(x,y,img_sum):
# 以x,y为中心,选择矩形框,求该矩形区域内所有像素点之和
# 矩形框左上和右下的坐标为([-HALF_KERNEL,-HALF_KERNEL],[HALF_KERNEL+1,HALF_KERNEL+])(相对于中心点的偏移坐标)
# 因输入图像已经是积分图像,所以原图该区域的像素点之和,等同于,在积分图像上对该矩形四个顶点处像素的加减运算
x, y= int(x),int(y)
HALF_KERNEL = (int)(KERNEL_SIZE / 2)
return img_sum[y-HALF_KERNEL,x-HALF_KERNEL] + img_sum[y+HALF_KERNEL+1,x+HALF_KERNEL+1] \
-img_sum[y-HALF_KERNEL,x+HALF_KERNEL+1] - img_sum[y+HALF_KERNEL+1,x-HALF_KERNEL]
公式(2)中,对所有比较点对进行逐个判断并保存为二进制串,代码实现为:
def generated_des(kpx,kpy,sum_img,pt_arr):#为每一个关键点生成描述符
byte_arr = []
for pt_byte in pt_arr: #对于所有点对(例如,32×8个点对)中的每一字节对点(1×8个点对)
byte_val = 0
for bit in pt_byte:#对于每个字节点对(8个点对)中的每一点对
byte_val = byte_val<<1
left_offset,right_offset = bit#得到待比较的左、右点
left_cx,left_cy = kpx+0.5+left_offset[1],kpy+0.5+left_offset[0]#得到左边中心点
right_cx, right_cy = kpx+0.5 + right_offset[1], kpy +0.5+ right_offset[0]#得到右边中心点
#根据左、右中心点,获取相应区域的像素和 ,并进行大小比较
bit = get_sum_from_integral(left_cx,left_cy,sum_img) < get_sum_from_integral(right_cx,right_cy,sum_img)
bit = bit.astype(int)
byte_val = byte_val+bit#将bit保存至byte中
byte_arr.append(byte_val)#保存该byte至byte数组中
return np.array(byte_arr)#返回byte数组,例如32个bytes
完整的brief算子实现为:
def my_brief_des(img_src,kps_src,bytes=32):
#先读取文件,获得比较点对
if bytes==16:
filename = 'generated_16.txt'
else:
filename = 'generated_32.txt'
with open(filename) as f:
rawtxt = f.read()
pt_arr = get_pt_lines(rawtxt)
# 生成积分图像,便于后续的加速运算
sum_img = cv2.integral(img_src, sdepth=cv2.CV_32S)
# 对关键点进行筛选,剔除边界之外的点
kps = runByImageBorder(kps_src, img_src, PATCH_SIZE / 2 + KERNEL_SIZE / 2)
# 为所有关键点生成描述符
des = []
for kp in kps:
byte_arr = generated_des(kp.pt[0],kp.pt[1], sum_img,pt_arr)#计算每一个关键点的描述符
des.append(byte_arr)
return kps, np.array(des)
主程序调用:
if __name__ == '__main__':
img_src = cv2.imread('susan_input1.png',cv2.IMREAD_GRAYSCALE)
#使用fast算子,寻找出图像的关键点
fast = cv2.FastFeatureDetector_create(threshold=10,type=cv2.FastFeatureDetector_TYPE_9_16)
fast.setNonmaxSuppression(True)
fast_kps = fast.detect(img_src)
#使用自行编写的brief函数生成描述符
my_kps,my_des = my_brief_des(img_src, fast_kps, bytes=32)
3、基于opencv实现
Opencv自带BRIEF算子,可以直接对关键点生成描述子。这里使用的opencv版本为3.4.11。
调用方式为:
brief = cv2.xfeatures2d.BriefDescriptorExtractor_create(bytes=16)
kps,des = brief.compute(img_src, kps)
主程序调用,并与自行编写的brief算子进行比较:
if __name__ == '__main__':
img_src = cv2.imread('susan_input1.png',cv2.IMREAD_GRAYSCALE)
#使用fast算子,寻找出图像的关键点
fast = cv2.FastFeatureDetector_create(threshold=10,type=cv2.FastFeatureDetector_TYPE_9_16)
fast.setNonmaxSuppression(True)
fast_kps = fast.detect(img_src)
#使用自行编写的brief函数生成描述符
my_kps,my_des = my_brief_des(img_src, fast_kps, bytes=32)
#调用opencv库的brief算子生成描述符
brief = cv2.xfeatures2d.BriefDescriptorExtractor_create(bytes=32)
kps,des = brief.compute(img_src,fast_kps)
#检验误差范围
err = 1.0*my_des - des
print(np.max(abs(err)))
对于给定的图,自行编写的brief算子和opencv库中的brief算子,计算结果一致。
4、python源码下载
Python程序源码下载地址
https://download.csdn.net/download/xiaohuolong1827/86221146















 589
589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









