






本教程将从0构建 ComfyUI 三重细节填充放大工作流,人有多大胆,图有多大产
「四种放大」
。
AI绘画常用的图像放大思路有四个:像素放大、模型放大、重采样放大、区块放大。这四个并不是专业术语,也不是标准的分类,但我觉得这么分类非常有助于理解和实操,其他不常用的放大方法在此没有拿出来讨论的必要性。
「像素放大」
右侧是一张150px×150px的头像,左侧是使用图片编辑器(这里使用Photoshop也就是PS)的“调整图像大小”功能进行的简单两倍像素放大(也就是300px×300px)的效果。原来的蓝色眼瞳高光占2个像素,放大后占了约9个像素。

像素放大法只是单纯的将1个像素点复制出了N个,仅此而已(其实就是基于插值算法,计算出图像放大后新位置的像素值),它并不增加任何细节。当把镜头推远后,直观感觉上图像的质量并没有提升,该“糊”的地方还是很“糊”。


这个事情也侧面反映出,图像和视频并不是分辨率越高质量越好。所谓的“高清”、“超清”,讲的是单位面积的像素内所承载的内容密度。内容密度不够,分辨率再高也是糊。
“像素放大”方法是在“像素空间”做文章的放大方法,也是对提升清晰度来说最没用的一种放大方法。
「模型放大」
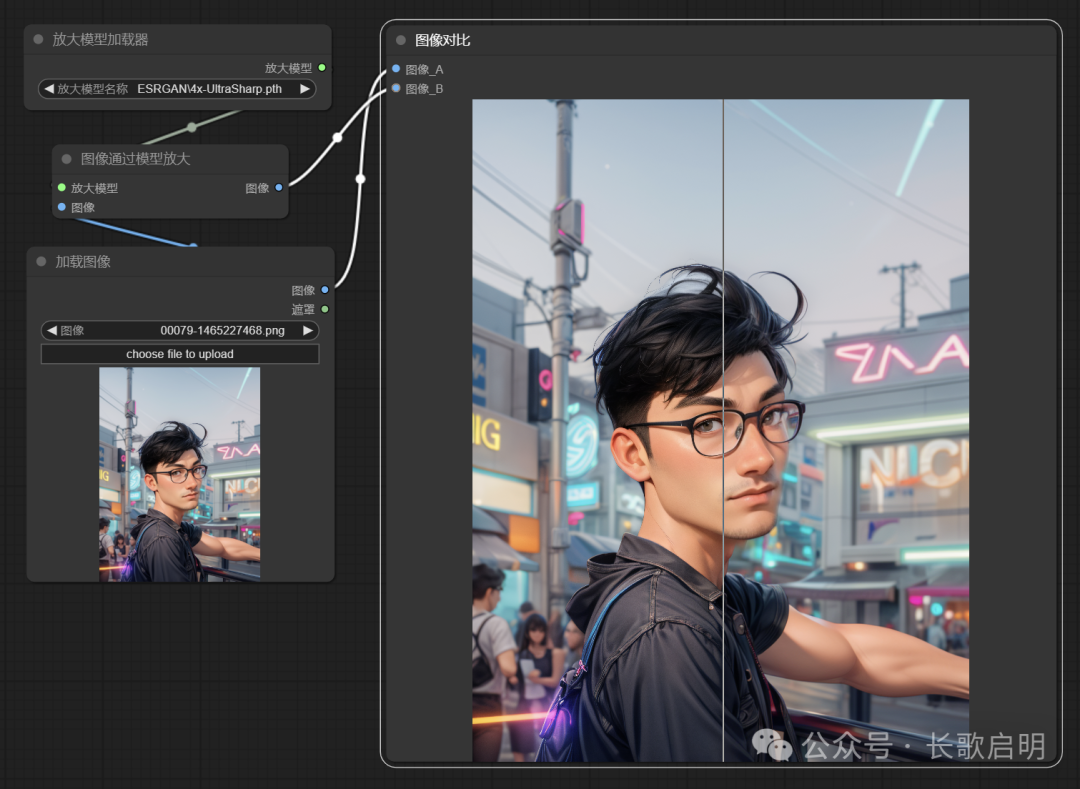
基于深度学习模型、网络对抗模型等现代算法来放大图片,在提高分辨率的同时保持能增强图像的细节、清晰度和逼真度。耳熟能详的有ESRGAN系列和它的升级版4x-ultrasharp。

右半边是原图,左半边使用了 4x-ultrasharp 模型进行放大。嘴唇、皮肤、脖子上的金属首饰,质感得到了明显增强。直观上,4x-ultrasharp 增加了图像的“锐度”,这可能也是模型使用“sharp”这个词的原因。

同样是使用了 4x-ultrasharp 放大模型,注意头发和眉毛在经过模型放大后纹理和细节性的加强程度。
模型放大方法也是在“像素空间”做文章的放大方法,它总是尝试从低分辨率图像中生成高分辨率图像,然后不断判断生成的高分辨率图像与真实高分辨率图像之间的差异,多次迭代形成最优图像。
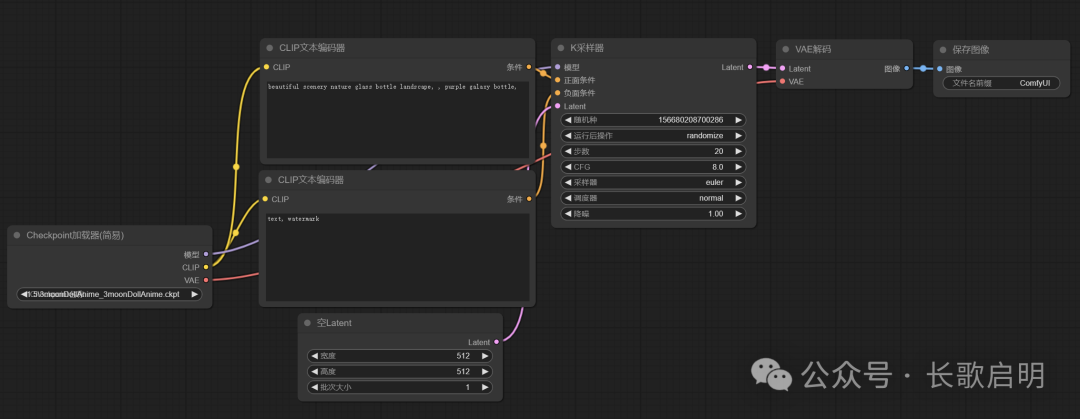
模型放大是最常用的图像还原和超清分辨率方法,快速、使用、质量高。工作流非常简单:
「重采样放大」
重采样放大也叫潜空间放大,顾名思义就是把“高维度像素空间”的图片,通过VAE编码打回到“更大尺寸的低维度潜空间”,通过添加额外的随机噪声,再VAE解码,实现图片的间接放大。(如果看不懂这一段,可以回顾一下这篇 [AI绘画] 简明扩散模型原理 - ComfyUI 从0到1复习相关概念)
如果你明白潜空间的含义,就知道重采样放大,实际上是一种图生图重绘,所以这种放大思路的缺点在于放大质量的不稳定性。重采样步骤和采样算法等因素的协调性,直接影响了放大的质量和与原图的一致性。
「区块放大」
区块放大严格意义上不是一种“算法”,它更像是一个工程技巧。它的基本思路是图像拆分->分别放大->重新组合。
更大的图像尺寸就是能够在单位像素面积下承载更多的内容,所以尽可能地在放大整体像素尺寸的同时填充内容,是大家都希望的。换句话说,只要硬盘够大,好的图片多大都不算大。
假设你的显卡和显存容量,能够支持一次性将1024×1024的图片放大4倍,也就是4096×4096,那么你还能将它再一次性超清放大4倍吗?然后再放大4倍呢?对于大多数家用电脑,答案是否定的,强如N卡GTX4090的显存也会爆掉。
区块放大,就是将这个4096×4096的图片,三横三竖砍成16个1024×1024的图块,然后分别对这16张局部图进行16次单独放大,再将他们按照原来的顺序和位置拼接好,从而实现对 4096×4096 放大4倍的效果。
实际的分块,要比上面这个计算尺寸大一个边,也就是说,块与块之间的边界,有内容重合的部分,比如每个块实际上是按照 1100×1100 来放大的。这么做的好处是,在最后一步拼接时,块与块之间会有更好的衔接,整张图会更整体。
「工作流拆解和创建」
三重放大的基本思路是组合上面介绍的四种放大中的后面三种,即:潜空间放大->分区放大->模型放大。这个组合顺序,从原理上来说可以总结为“潜空间重采样”、“像素空间局部模型放大”、“像素空间全局模型放大”。关于顺序说明如下:
如果把潜空间放大放在靠后的位置,它的重采样效果会破坏前置放大步骤为图像增添的细节和清晰度,因果关系就类似“先贴漂亮的墙纸、再把墙砸掉、再砌一面更好的墙”。所以所有的潜空间放大都应该放在最前面。
区块放大本质上是局部模型放大,它不破坏整体结构和内容协调性,是在“潜空间放大”增加了画面丰富度后,进一步进行画面的细节精细化处理并添加更好的光影效果。所以紧跟着潜空间执行。
模型放大作为全局整体执行时,不添加任何细节,而是把看起来很“糊”的东西变得更加清晰,可以简单的理解为是在把尺寸放大的同时锐化整个画面。
「添加潜空间放大节点」
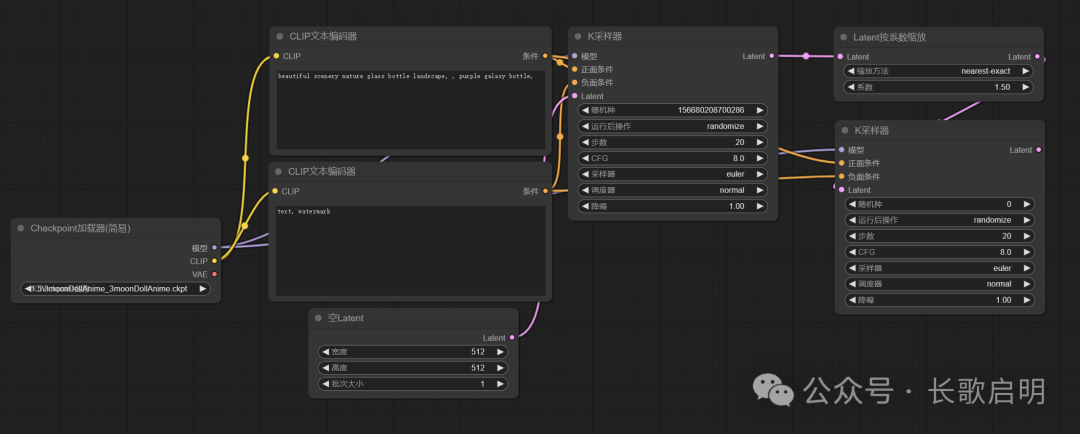
潜空间放大不需要把K采样器的结果进行解码,那么我们把基础工作流最后的VAE解码节点删除。之后添加两个节点:
-
新建 -> Latent -> Latent按系数缩放
-
新建 -> 采样 -> K采样器。
将原K采样器的Latent输出连接到新增的Latent按系数缩放节点的输入上,并将它的输出连接到新增K采样器的Latent输入上;将模型加载节点的模型输出连接到新增K采样器的对应输入上;将两个CLIP文本编辑器的输出连接到新增K采样器的对应输入上。
Latent按系数缩放和K采样器,完成“潜空间放大”
「添加区块放大节点」
区块放大节点是一个特别大的节点,因为它傻瓜式融合了分块、区块模型放大、区块拼接、接缝重绘整合等多个步骤。区块放大节点的位置
- 新建->图像->放大->SD放大
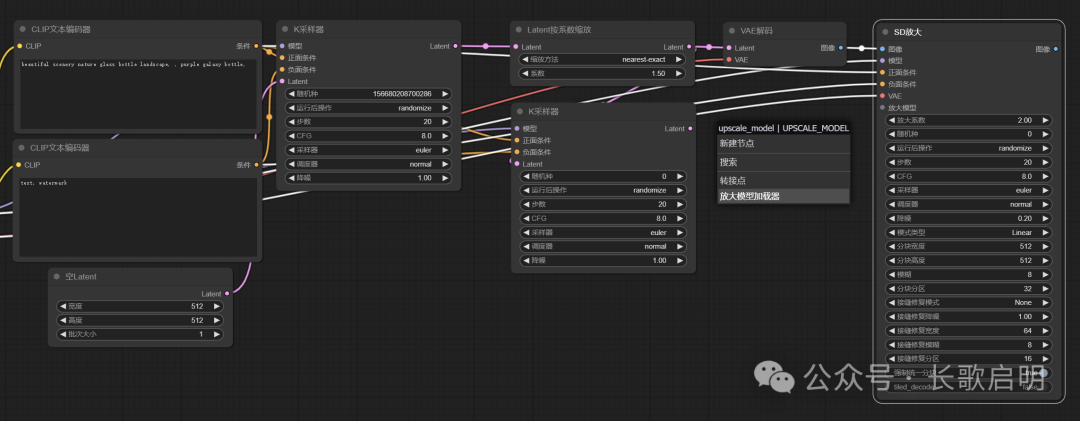
有两点需要注意。第一,区块放大节点的输入不同于潜空间放大,它的输入不是Latent而是图像,所以我们要现在区块放大节点之前,增加一个VAE解码器,以便把前一步潜空间放大的结果转换为像素空间图像。第二,区块放大本质是模型放大,所以需要放大模型加持。我们直接从区块放大节点的“放大模型”输入点上用鼠标连线到空白处,在弹出的选项中选择“放大模型加载器”。
随后,将最前面模型加载节点的模型输出连接到区块节点的对应输入上;将最前面模型加载节点的VAE输出连接到区块放大节点对应的输入上;将前面两个CLIP文本编辑器的输出连接到新增K采样器的对应输入上。这样我们就连接好了区块放大节点。
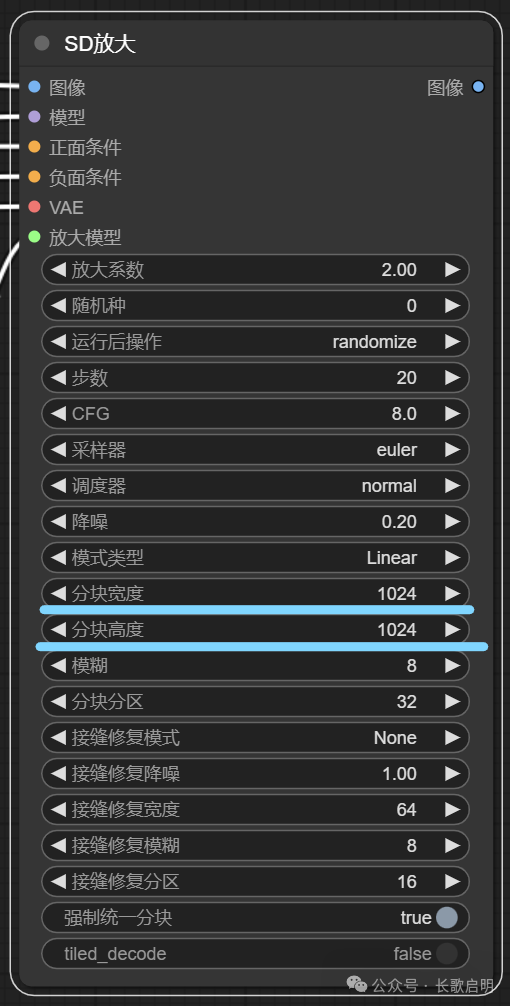
为了简化教程,目前我们只需要关注分块宽度和分块高度。如果你的基模是SD1.5系列,这两个值为512或768。如果你的基模是SDXL、Pony或更高版本,这两个值至少是1024并且是64的整数倍。
这两个值什么意思呢?我们刚刚说过,区块放大就是把一张图,切割成若干子图,分别对子图放大后在拼接成大图。这两个值,就决定了切割出来的子图的大小,用一张图示意如下:

这是一张 2200×1400 的图,当我们设置分块为 1024×1024 时,图片大约会按照上面这个切分方式分为 2×3 的网格,并分6次局部执行局部模型放大。

上面是一个简化算法。实际的切分方法要更加复杂一些。为了确保子图与子图在最终拼接时具有更加丝滑的接缝过度,实际上分块与分块之间会重合,重合的宽度由叫做“接缝修复宽度”的参数控制。实际分块可视化后大概像这样:

「添加模型放大节点」
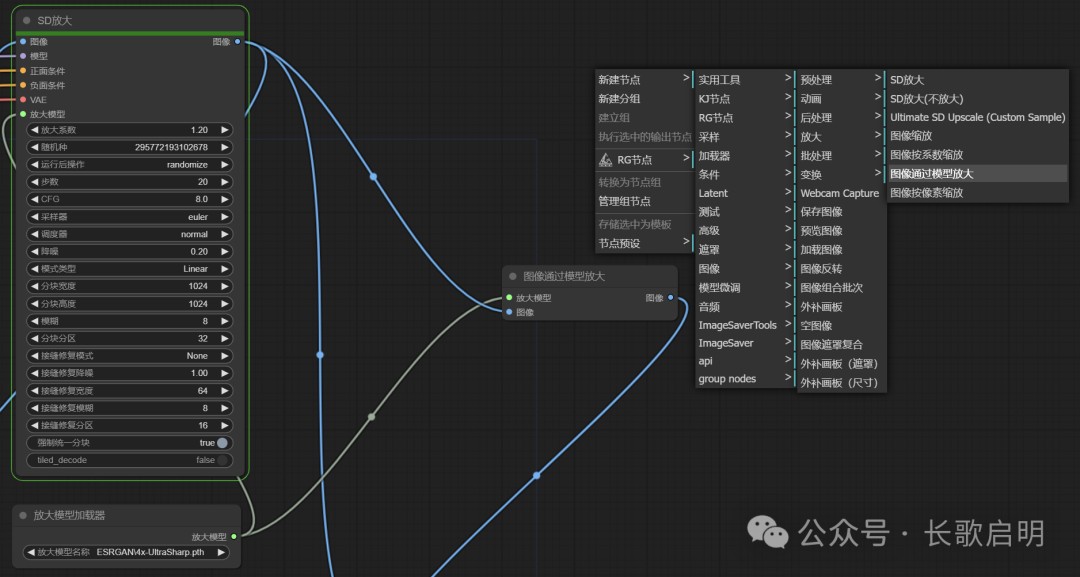
这一步就比较简单了,添加一个“图像通过模型放大”节点即可
- 新建->图像->放大->图像通过模型放大
将上一步区块放大节点的图像输出给到模型放大的图像输入,将上一步的放大模型加载其的输出,再拉一根线到模型放大节点的放大模型输入上,这样就完成了全局模型放大节点的搭建。
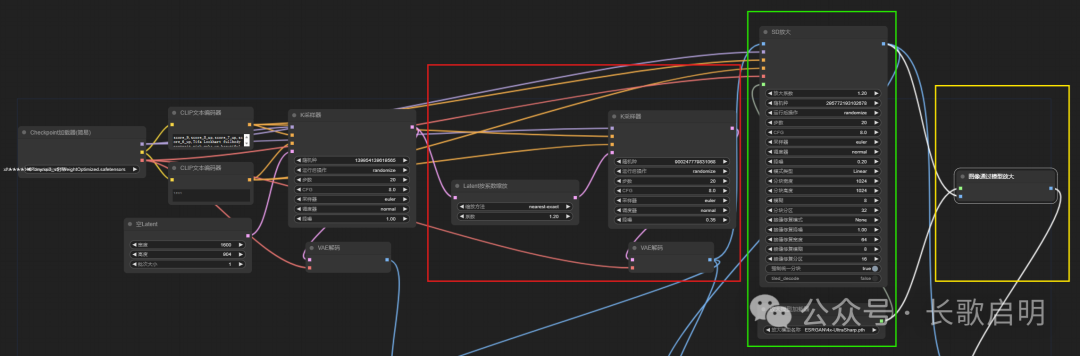
至此,我们就完成了三重超清放大工作流的全部搭建工作,这个工作流现在长这样,其中红框为“潜空间放大”,绿框为“区块放大”,黄框为“模型放大”,红框前面的部分是我们前面讲过的文生图绘图模型:
「放大效果」
「潜空间放大效果前后对比」
 左:原图 右:潜空间重采样 眉毛纹理、睫毛根数和瞳仁深度得到细节增强
左:原图 右:潜空间重采样 眉毛纹理、睫毛根数和瞳仁深度得到细节增强
 左:原图 右:潜空间重采样 珍珠重绘和高光增强
左:原图 右:潜空间重采样 珍珠重绘和高光增强
「区块放大效果前后对比」
 左:上一步原图 右:区块放大结果 花蕊重绘细节增强
左:上一步原图 右:区块放大结果 花蕊重绘细节增强
 左:上一步原图 右:区块放大结果 鼻子高光、唇部高光
左:上一步原图 右:区块放大结果 鼻子高光、唇部高光
「全局模型放大前后对比」
 左:上一步原图 右:模型放大结果 全局锐化
左:上一步原图 右:模型放大结果 全局锐化
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除

















 78
78

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









