







这篇文章主要介绍sparksql中Distribution的源码体系,Distribution是我们理解Physical Plan、executed Plan、shuffle、SparkSQL的AQE机制等的一个比较基础的知识点。
如果你正好也想了解这块,点赞、收藏吧
Distribution定义了查询执行时,同一个表达式下的不同数据元组(Tuple)在集群各个节点上的分布情况。
它用在什么地方呢?
每个physical operator都实现了requiredChildDistribution方法,以获得一个Distribution的实例,用于表示 operator对其input数据分布情况的要求。
类的依赖关系图

我们挨个来解释
1、UnspecifiedDistribution
未指定分布,无需确定数据无组之间的位置关系 。
case object UnspecifiedDistribution extends Distribution {
override def requiredNumPartitions: Option[Int] = None
override def createPartitioning(numPartitions: Int): Partitioning = {
throw new IllegalStateException("UnspecifiedDistribution does not have default partitioning.")
}
}这个是指啥?
我们知道Distribution是physical operator 用于表示operator对其input数据(child节点的输出数据)分布情况的要求,那UnspecifiedDistribution的意思就是对Child的分区规则没有要求,无所谓,你啥样都行
比如:
select a,count(b) from testdata2 group by a
== Physical Plan ==
HashAggregate(keys=[a#3], functions=[count(1)], output=[a#3, count(b)#11L])
+- HashAggregate(keys=[a#3], functions=[partial_count(1)], output=[a#3, count#15L])
+- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#3]
+- Scan[obj#2]SerializeFromObject节点,
它的requiredChildDistribution就是UnspecifiedDistribution:
SerializeFromObject-SerializeFromObjectExecrequiredChildDistribution:List(UnspecifiedDistribution)requiredChildOrdering:List(List())outputPartitioning:UnknownPartitioning(0)
2、BroadcastDistribution
广播分布,数据会被广播到所有节点上。构造参数mode为广播模式BroadcastMode,广播模式可以为原始数据IdentityBroadcastMode或转换为HashedRelation对象HashedRelationBroadcastMode。
case class BroadcastDistribution(mode: BroadcastMode) extends Distribution {
override def requiredNumPartitions: Option[Int] = Some(1)
override def createPartitioning(numPartitions: Int): Partitioning = {
assert(numPartitions == 1,
"The default partitioning of BroadcastDistribution can only have 1 partition.")
BroadcastPartitioning(mode)
}
}以 BroadcastHashJoinExec 为例:

如果是Broadcast类型的Join操作假设左表做广播,那么requiredChildDistribution得到的列表就是[BroadcastDistribution(mode),UnspecifiedDistribution],表示左表为广播分布;
如果是Broadcast类型的Join操作假设右表做广播,那么requiredChildDistribution得到的列表就是[UnspecifiedDistribution,BroadcastDistribution(mode)],表示右表为广播分布;
3、OrderedDistribution
构造参数ordering是seq[SortOrder]类型该,分布意味着数据元组会根据ordering计算后的结果排序。
case class OrderedDistribution(ordering: Seq[SortOrder]) extends Distribution {
require(
ordering != Nil,
"The ordering expressions of an OrderedDistribution should not be Nil. " +
"An AllTuples should be used to represent a distribution that only has " +
"a single partition.")
override def requiredNumPartitions: Option[Int] = None
override def createPartitioning(numPartitions: Int): Partitioning = {
RangePartitioning(ordering, numPartitions)
}
}以 SortExec 为例:

在全局排序的sort算子中,requiredChildDistribution得到的列表是[OrderedDistribution(sortOrder)],其中sortOrder是排序表达式,相同的数据ordering计算结果相同因此能够保持连续性并被划分到相同分区中
4、AllTuples
只有一个分区,所有的数据元组存放在一起
case object AllTuples extends Distribution {
override def requiredNumPartitions: Option[Int] = Some(1)
override def createPartitioning(numPartitions: Int): Partitioning = {
assert(numPartitions == 1, "The default partitioning of AllTuples can only have 1 partition.")
SinglePartition
}
}以 GlobalLimitExec 为例:

选取全局前K条数据的GlobalLimit算子,requiredChildDistribution得到的列表就是AllTuples,表示执行该算子需要全部的数据参与
5、ClusteredDistribution
构造参数clustering是Seq[Expression]类型,起到了hash函数的效果,数据经过clustering计算后,相同value的数据元组会被存放在一起。如果有多个分区的情况,则相同的数据会被存放在同一个分区中;如果只能是单个分区,则相同的数据会在分区内连续存放。
case class ClusteredDistribution(
clustering: Seq[Expression],
requiredNumPartitions: Option[Int] = None) extends Distribution {
require(
clustering != Nil,
"The clustering expressions of a ClusteredDistribution should not be Nil. " +
"An AllTuples should be used to represent a distribution that only has " +
"a single partition.")
override def createPartitioning(numPartitions: Int): Partitioning = {
assert(requiredNumPartitions.isEmpty || requiredNumPartitions.get == numPartitions,
s"This ClusteredDistribution requires ${requiredNumPartitions.get} partitions, but " +
s"the actual number of partitions is $numPartitions.")
HashPartitioning(clustering, numPartitions)
}
}以 HashAggregateExec 为例:
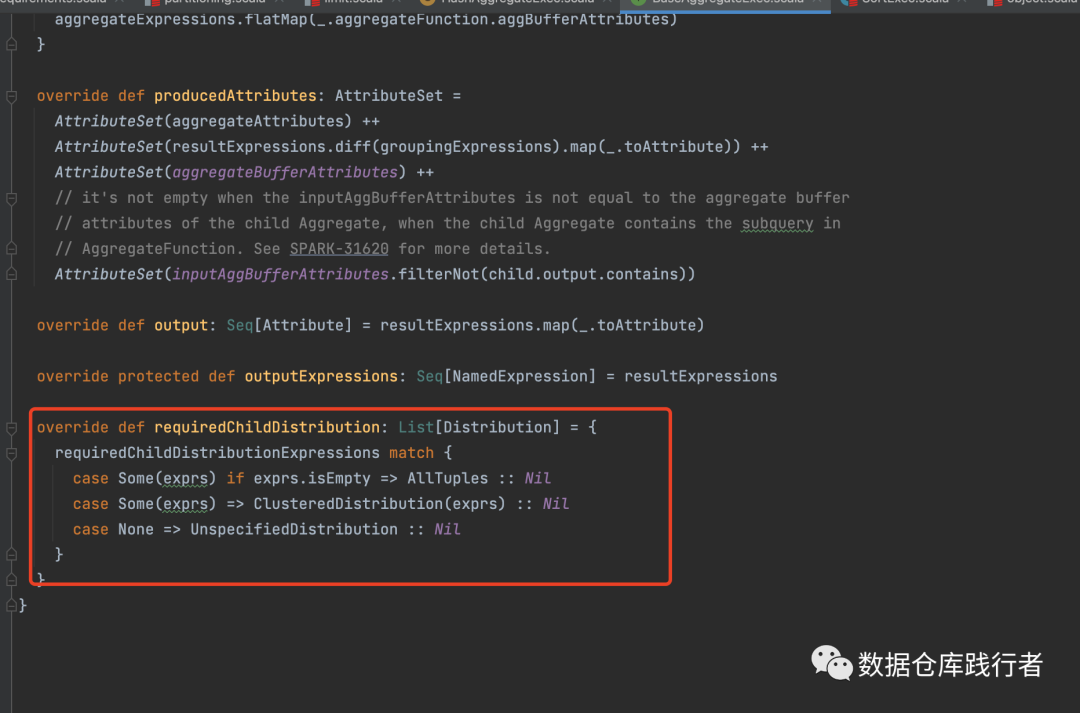
HashAggregateExec 沿用父类BaseAggregateExec 的requiredChildDistribution 方法 ,其执行的前提是“所有具有相同aggregation key的record放到同一个处理单元中”。
在Spark中,这样的处理单元就是RDD的一个partition,因此也就是要满足“所有group by 的column具有相同value的record被分配到RDD的同一个partition中”。
HashAggregateExec的requiredChildDistribution就是ClusteredDistribution。
6、HashClusteredDistribution
HashClusteredDistribution与ClusteredDistribution类似,构造参数expressions是Seq[Expression]类型,起到了hash函数的效果。
但是比ClusteredDistribution更严格,不仅保证具有相同key的record被分配到同一个partition内,而且保证了对每一个key分配到的partition id也都是确定的。
case class HashClusteredDistribution(
expressions: Seq[Expression],
requiredNumPartitions: Option[Int] = None) extends Distribution {
require(
expressions != Nil,
"The expressions for hash of a HashClusteredDistribution should not be Nil. " +
"An AllTuples should be used to represent a distribution that only has " +
"a single partition.")
override def createPartitioning(numPartitions: Int): Partitioning = {
assert(requiredNumPartitions.isEmpty || requiredNumPartitions.get == numPartitions,
s"This HashClusteredDistribution requires ${requiredNumPartitions.get} partitions, but " +
s"the actual number of partitions is $numPartitions.")
HashPartitioning(expressions, numPartitions)
}
}以 SortMergeJoinExec 为例:

在Spark的实现里,SortMergeJoinExec的实现简单来说就是把join两边的RDD中具有相同id的partition zip到一起进行关联。
ClusteredDistribution保证的是具有相同key的record能聚集到同一个partition中,但对join来说这样还不够。
在RDD1中假设join key为1的record分配到了partition 0,那么如果RDD1和RDD2要进行join,则RDD2中所有join key为1的record也必须分配到partition 0中。Spark通过在左右两边的shuffle中使用相同的hash函数和shuffle partition number来保证这一点。
SortMergeJoinExec对join两边的requiredChildDistribution列表是
[HashClusteredDistribution(leftKeys),HashClusteredDistribution(rightKeys)],表示左表数据根据leftKey表达式计算分区,右表数据根据rightKeys表达式计算分区。
推荐阅读:
sparksql源码系列 | 最全的logical plan优化规则整理(spark2.3)
sparksql源码系列 | 一文搞懂with one count distinct 执行原理
Sparksql源码系列 | 读源码必须掌握的scala基础语法
澄清 | snappy压缩到底支持不支持split? 为啥?
Hey!
我是小萝卜算子
欢迎关注:数据仓库践行者
分享是最好的学习,这里记录我对数据仓库的实践的思考和总结
每天学习一点点
知识增加一点点
思考深入一点点
在成为最厉害最厉害最厉害的道路上
很高兴认识你















 2188
2188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











