







》首先一张图像通过卷积会不会改变尺寸大小有以下几种情况:
- 卷积+padding(solid表示不填充,same表示填充到不改变图像大小,这是TensorFlow的叫法,其他框架不一样)
- 卷积+padding(非补全式填充)
- 卷积stride不等于1 ,除不尽就向下取整 #https://www.zhihu.com/question/270777218
- pooling池化层操作,一般stride(2,2),这样不会增加参数的数量。
在日常神经网络的构建过程中,用那种形式来实现对图像的降采样?
答:对于卷积神经网络,详情可以参考https://zhuanlan.zhihu.com/p/42559190,通过权值共享实现了平移不变性和参数减少的目的,增加了图像特征提取算法的鲁棒性。而通常在构建卷积核时,还是一般优选卷积+padding,保持通过卷积前后图像尺寸不变。
》图像的上采样形式有哪些?(https://blog.csdn.net/cs_softwore/article/details/86593604)
- 直接cv2.resize(内部算法是线性插值还是双线性插值)
- unconv反卷积操作,但反卷积一般会出现棋盘效应,一些避免棋盘操作的方法可参考https://blog.csdn.net/shwan_ma/article/details/80874366,总结起来就是两种:(1)kernel size与stride可以整除,比如核大小与步长都选择2;(2)利用双线性上采样+padding+卷积操作替换反卷积
- upsample操作(双线性插值,邻近插值等)
-
pixel_shuffle(pytorch)或depth_to_space(tensorflow),这两个操作功能是一样的,都是减少特征通道,扩大特征分辨率。详情可参考 https://blog.csdn.net/CHNguoshiwushuang/article/details/80878460
这些形式 的上采样有什么区别,一般采用哪种比较合适,在unet网络中优先选择双线性插值上采样,结合实际情况进行调整优化。
》图像的融合方式有add与concat两种形式一般选择哪种效果更好呢?(https://blog.csdn.net/xys430381_1/article/details/88355956)
Resnet是做值的叠加,通道数是不变的,DenseNet是做通道的合并。你可以这么理解,add是描述图像的特征下的信息量增多了,但是描述图像的维度本身并没有增加,只是每一维下的信息量在增加,这显然是对最终的图像的分类是有益的。而concatenate是通道数的合并,也就是说描述图像本身的特征增加了,而每一特征下的信息是没有增加,concat层多用于利用不同尺度特征图的语义信息,将其以增加channel的方式实现较好的性能,但往往应该在BN之后再concat才会发挥它的作用。
》图像锚点思想
锚点就是通过特征图上的点映射回原图上对应的区域,常用于目标检测中。

BN层和卷积层,池化层一样都是一个网络层,首先我们根据论文来介绍一下BN层的优点。
1)加快训练速度,这样我们就可以使用较大的学习率来训练网络。
2)提高网络的泛化能力。
3)BN层本质上是一个归一化网络层,可以替代局部响应归一化层(LRN层)。
4)可以打乱样本训练顺序(这样就不可能出现同一张照片被多次选择用来训练)论文中提到可以提高1%的精度。
这里首先介绍一下 Radosavovic 等人提出的网络设计空间(network design spaces)概念。其核心思想是,可以在设计空间中对模型进行采样,从而产生模型分布,并可以使用经典统计学中的工具来分析设计空间。在何恺明团队的这项研究中,研究人员提出,设计一个不受限制的初始设计空间的逐步简化版本。这一过程,就称为设计空间设计(design space design)。在设计过程的每个步骤中,输入都是初始设计空间,输出则是更简单、或性能更好的模型的精简模型。通过对模型进行采样,并检查其误差分布,即可表征设计空间的质量。

比如,在上图中,从初始设计空间A开始,应用2个优化步骤来生成设计空间B,然后是C。C⊆B⊆A,可以看到,从A到B再到C,误差分布逐渐改善。也就是说,每个设计步骤的目的,都是为了发现能够产生更简单、更有效模型的设计原理。研究人员设计的初始设计空间是AnyNet。网络基本设计很简单:主干(步幅为 2 的 3×3 卷积,32个输出通道)+ 执行大量计算的网络主体 + 预测输出类别的头(平均池化,接着完全连接层)。在 AnyNetX 上,研究人员旨在实现4个目的:
-
简化设计空间结构
-
提高设计空间的可解释性
-
改善或维持设计空间的质量
-
保持设计空间的模型多样性
于是,将初始的 AnyNetX 称作 AnyNetXA,开始进行“A→B→C→D→E”的优化过程。
轻量网络设计:随着嵌入式人工智能成为热门话题,轻量级CNN设计越来越受到关注。SqueezeNet[36]使用1*1卷积压缩特征尺寸。IGCNet[37]、ResNeXt[33]和CondenseNet[38]利用组卷积。Xception[39]和MobileNet系列[9,10]基于深度可分离卷积。在ShuffleNet[40]中,密集的1*1卷积与通道变换分组。在轻量级设计方面,我们的OSNet类似于MobileNet,它使用了分解卷积,并进行了一些修改,这些修改在经验上更适合于全尺度的特性学习。
- EfficientNet与EfficientDet:对网络的扩展可以通过增加网络层数(depth,比如从 ResNet (He et al.)从resnet18到resnet200 ), 也可以通过增加宽度,比如WideResNet (Zagoruyko & Komodakis, 2016)和Mo-bileNets (Howard et al., 2017) 可以扩大网络的width (#channels), 还有就是更大的输入图像尺寸(resolution)也可以帮助提高精度。如下图所示: (a)是基本模型,(b)是增加宽度,(c)是增加深度,(d)是增大属兔图像分辨率,(d)是EfficientNet,它从三个维度均扩大了,但是扩大多少,就是通过作者提出来的复合模型扩张方法结合神经结构搜索技术获得的。

- RegNet:在大家都是在固定的搜索里寻找最优解的时候,作者想到了对Search space作优化。作者旨在进一步深化“设计空间设计”的理念。他们的目的不是要发现任何特定的网络,甚至也不是要找到某一类网络。正如他们所说,他们试图“发现一般的设计原则,这些原则描述的网络是简单的,工作良好,并且可以在不同的设置下推广。”AnyNet和随后的RegNet设计空间适合于low-compute, low-epoch的训练机制。这一目标本身就很有用,对于本文中所示的基于人口的方法也很有用。值得注意的是,他们的设计空间也适用于更复杂的模型。
- RepVGG:为每一个3x3卷积层添加平行的1x1卷积分支和恒等映射分支,构成一个RepVGG Block。这种设计是借鉴ResNet的做法,区别在于ResNet是每隔两层或三层加一分支,而Repvgg是每层都加。其特点就是同时利用多分支模型训练时的优势(性能高)和单路模型推理时的好处(速度快、省内存)。这里的关键显然在于这种多分支模型的构造形式和转换的方式。需要注明的是,RepVGG是为GPU和专用硬件设计的高效模型,追求高速度、省内存,较少关注参数量和理论计算量。在低算力设备上,可能不如MobileNet和ShuffleNet系列适用。

》图卷积
图卷积网络(GraphConvolutionalNetwork,GCN)是近年来逐渐流行的一种神经网络结构。不同于只能用于网格结构(grid-based)数据的传统网络模型LSTM和CNN,图卷积网络能够处理具有广义拓扑图结构的数据,并深入发掘其特征和规律,例如PageRank引用网络、社交网络、通信网络、蛋白质分子结构等一系列具有空间拓扑图结构的不规则数据。相比于一般的拓扑图而言,人体骨骼拓扑图具有更加良好的稳定性和不变性,因此从2018年开始,就有许多学者尝试将图卷积网络应用到基于人体骨骼的行为识别领域来,也取得了不错的成果。
- 什么是图(graph)?为什么要研究GCN?
我们知道,CNN在处理图像数据时具有很强的特征抽取能力和整合能力,这得益于卷积核(kernel,orfilter)的参数共享机制和加权平均机制。卷积本质上就是一种加权求和的过程,而卷积核的参数就是不同像素点对应的权重,并且不同的图片都共享同一个卷积核,这使得CNN能够通过对卷积核参数的迭代更新来隐式的学习图像中具有的像素排列规律,进而学习到不同的形状特征和空间特征。
但值得注意的一点是,CNN所处理的数据都具有规则的网格结构,也就是排列很整齐的矩阵,具有EuclideanStructure,例如RGB图片(图1)。如果要将CNN应用于非图像领域,就必须将数据组合为规整的网络结构,才能作为CNN的输入。例如在18年之前的行为识别研究中,常用的方法就是以一定的顺序将一个动作的关节坐标序列转换为一张RGB图片,从而将动作识别工作转化为图像识别工作。

图1规则空间结构数据
然而现实生活和科学研究中有很多数据都不具备完整的矩阵结构,相反,更多的是以一定的连接关系聚合在一起,如图2所示。社交网络,通信网络,互联网络等都具有类似的结构。
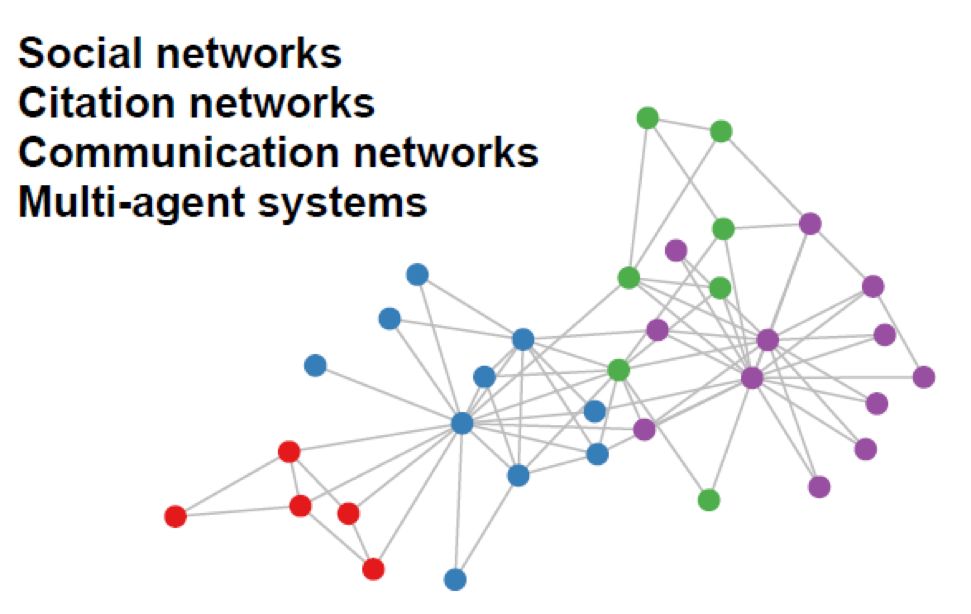
图2社交网络拓扑图
类似这样的网络结构就是图论中所定义的拓扑图。更一般的,图就是指图论中用顶点和边建立相应关系的拓扑图。我们可以用一个点和边的集合来表示图:G=(E,V);其中E表示边的集合,V表示顶点的集合。那么对于这种具有拓扑图结构的数据而言,CNN处理起来是非常困难的(但也不是没有办法哦),而且通常不能很好的抽取节点与节点之间的连接关系信息(是否相连),这也是我们研究GCN的重要原因。当然,根本的原因还是在于数据的多样性,广义上来讲,任何数据在赋范空间内都可以建立拓扑关联,谱聚类就是应用了这样的思想。所以说拓扑连接是一种广义的数据结构,GCN有很大的应用空间。
图卷积操作如何进行呢?
目前有两种类型的图卷积操作,一种是基于空域的图卷积,另一种是基于谱域的图卷积,这里着重介绍第一种。
前面我们提到,卷积操作的本质意义就是对一个范围内的像素点进行加权求平均,这能有助于提取空间特征,那么如何将这种思想应用到拓扑图上呢?我们可以换一种方式来理解卷积操作,如图3,对于featuremap(蓝色部分)中的一个点(红色),其特征值实际上是周围所有像素点将特征值传播到中心点后进行加权平均,这种操作等效于传统的卷积操作,只不过我们人为的为特征添加了一个传播方向(边),将每个像素点当成顶点,从而在图结构上再次定义了卷积操作。
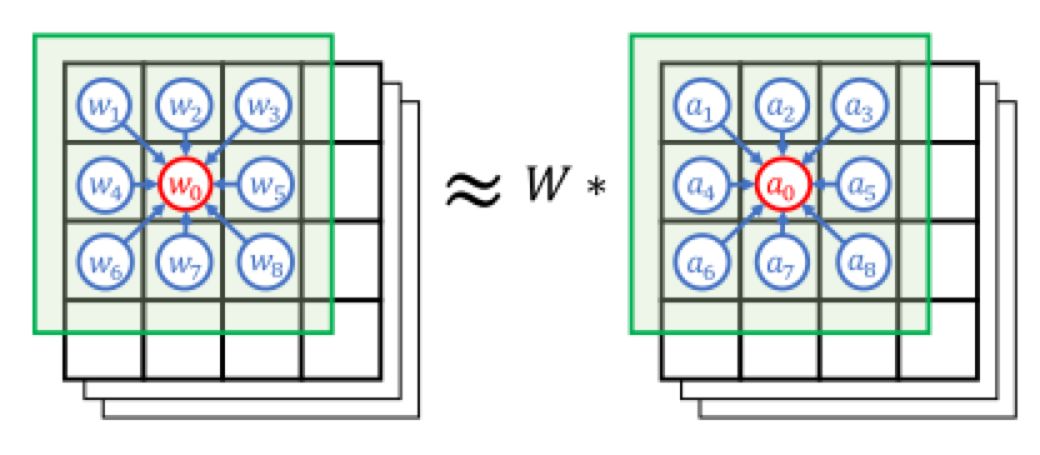
图3卷积操作的另一种理解
进一步的,对于广义拓扑图结构的数据,也可以按照这种思想来定义卷积操作,如图4所示,将每个节点的邻居节点的特征传播到该节点,再进行加权平均,就可以得到该点的聚合特征值,只不过在CNN中,我们将这个聚合特征值当做了featuremap中的一个点,而在GCN中没有featuremap的概念,我们直接将这个聚合特征值作为传播到下一层的特征值。蓝色部分就是图卷积操作对应的kernel,这里是为了理解才画出这个蓝色区域,在GCN中也没有kernel的概念,这也是因为图是不规则的。
类似于CNN,图卷积也采用共享权重,不过不同于CNN中每个kernel的权重都是规则的矩阵,按照对应位置分配,图卷积中的权重通常是一个集合。在对一个节点计算聚合特征值时,按一定规律将参与聚合的所有点分配为多个不同的子集,同一个子集内的节点采用相同的权重,从而实现权重共享。例如对于图4,我们可以规定和红色点距离为1的点为1邻域子集,距离为2的点为2邻域子集。当然,也可以采用更加复杂的策略,例如按照距离图重心的远近来分配权重。权重的分配策略有时也称为label策略,对邻接节点分配label,label相同节点的共享一个权重。
到这里想必你已经发现了,其实图卷积操作就是传统的卷积操作在拓扑图上的概念延伸和转移,通过对比二者,你能更好的学习到图卷积网络的精髓。
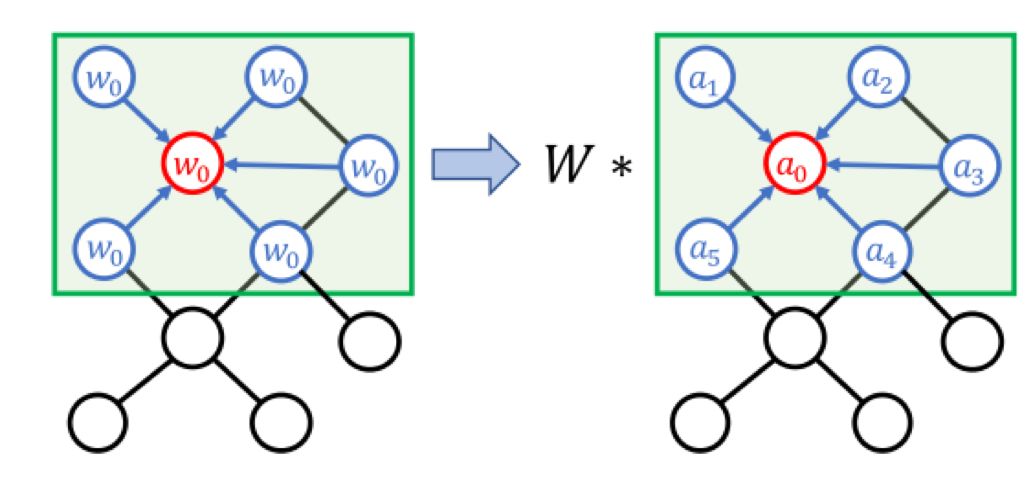
图4拓扑图上的卷积操作
特征在层与层之间的传播方式可以用公式表示如下:
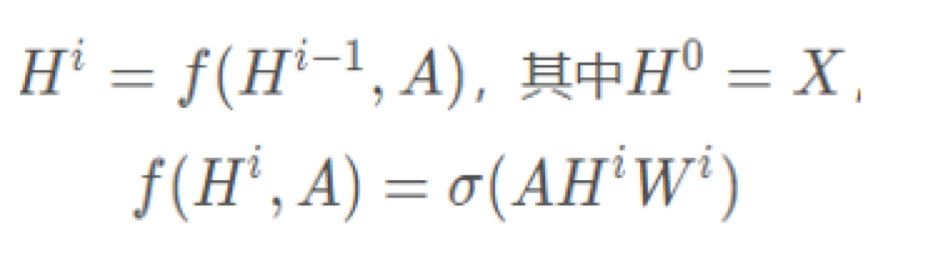
其中Hi是第i层的特征矩阵,当i=0时,H0就表示输入图的节点特征矩阵。A是输入图的邻接矩阵,Wi表示第i层的权重矩阵。σ表示激活函数。通过邻接矩阵左乘特征矩阵,可以实现特征的聚合操作,然后再右乘权重矩阵,可以实现加权操作。权重矩阵W和邻接矩阵H是用图卷积做行为识别工作时的重点研究对象。邻接矩阵的示例如下图:

图5邻接矩阵示例
如果两个节点相邻,那么在矩阵中对应位置为1,否则为0。这是一种非常基础的定义,不同的行为识别工作会在此基础上设计不同的变体定义。
概括的来说,图卷积操作就是将每个节点的特征与其邻居节点的特征加权平均后传播到下一层。这种图卷积操作称为在空域上的图卷积,有如下几个特点:
1.随着层数的加深,每个节点能聚合到的特征越远,也就是感受野越大。
2.权重是共享的,不会具体到每个节点,这和传统CNN相同。(直观的理解,如果权重是因节点而不同的,那么一旦图结构发生变化,权重就会立刻失效)
3.每个顶点的邻居节点数可能不同,这导致邻居节点多的顶点的特征值更显著。
4.邻接矩阵在计算时无法将节点自身的特征包含到聚合特征值中。
此外,为了克服空域图卷积的缺点,学者们提出了谱域上的图卷积,大概思想是利用图的拉普拉斯矩阵和傅里叶变换来进行卷积操作。基于谱域的图卷积目前在行为识别中应用较少,并且原理非常复杂,这里不做详细介绍,有兴趣的同学可以阅读相关文章。
GCN在行为识别领域的应用
行为识别的主要任务是分类识别,对给定的一段动作信息(例如视频,图片,2D骨骼序列,3D骨骼序列),通过特征抽取分类来预测其类别。目前(18年过后)基于视频和RGB图片的主流方法是two-stream双流网络,而基于骨骼数据的主流方法就是图卷积网络了。
人体的骨骼图本身就是一个拓扑图,因此将GCN运用到动作识别上是一个非常合理的想法。但不同于传统的图结构数据,人体运动数据是一连串的时间序列,在每个时间点上具有空间特征,而在帧于帧之间则具有时间特征,如何通过图卷积网络来综合性的发掘运动的时空特征,是目前的行为识别领域的研究热点。笔者选取了自18年以来将GCN和行为识别相结合的代表性工作,用于讨论并分析这些工作的核心思想,以及在此基础上可以尝试的idea。
参考文献:
1、SpatialTemporalGraphConvolutionalNetworksforSkeleton-BasedActionRecognition
2、DeepProgressiveReinforcementLearningforSkeleton-basedActionRecognition
3、Part-basedGraphConvolutionalNetworkforActionRecognition
4、Actional-StructuralGraphConvolutionalNetworksforSkeleton-basedActionRecognition
5、AnAttentionEnhancedGraphConvolutionalLSTMNetworkforSkeleton-BasedActionRecognition
6、SemanticGraphConvolutionalNetworksfor3DHumanPoseRegression















 4367
4367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









