






2 经典模型学习—监督学习
2.1 监督学习基本架构和流程
文字说明:一般来说,分为以下步骤:
(1)准备训练数据集
(2)特征抽取
(3)将数据集中抽取出来的特征与训练数据集中每一样本对应的目标/标记(可以认为是结果,或者需要预测、分类、判定的值)加入机器学习算法
(4)得出预测模型
(5)将测试集的数据通过同样的特征抽取方法进行特征抽取,并加入预测模型。得出预测记过,用一标准来衡量正确率。
流程图如下:

2.2 分类学习
之前已经提到过,监督学习一般可以分为分类学习和回归预测两类。在分类学习中主要分为以下几类:
(1)二分类问题:判断是非,一般分类都是 是或者不是
(2)多分类问题:类别多于两个,但是一个样本只能属于一个类别
(3)多标签问题:一个样本可以属于多个类别
经典例子:细胞肿瘤性质的判定(二分类),手写体识别(多分类)
2.2.1 分类学习—线性分类器Linear Classifiers(以良性/恶性肿瘤判定为例)
(1)what is the Linear Classifiers?
是一种假设特征与分类结果存在线性关系的模型。此模型通过累加计算每个维度的特征与各自权重的乘积来帮助类别决策。
例如在在肿瘤判定例子中,我们假设肿瘤细胞的各项检测指标与肿瘤结果存在某一线性关系。
(2)A classical linear classifier model–logistic函数
对于logistic的原理正文部分不赘述,直接使用肿瘤预测实例来实践这一分类器。
- 数据的预处理部分,包括导入和缺失值替换
# 导入pandas与numpy工具包。
import pandas as pd
import numpy as np
# 创建特征列表,这里对应书本的37-38页的数据描述
column_names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape', 'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin', 'Normal Nucleoli', 'Mitoses', 'Class']
# 使用pandas.read_csv函数从互联网读取指定数据。
#参数name代表数据列的名字,应该等于一个list,这里用的是之前创建的column_names列表
data = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data', names = column_names )
# 将?替换为标准缺失值表示。
#to_replace参数表示被替代的对象
#value表示替换后的对象
data = data.replace(to_replace='?',value=np.nan)
# 丢弃带有缺失值的数据(只要有一个维度有缺失)。
#any’ : If any NA values are present, drop that row or column.
data = data.dropna(how='any')
# 输出data的数据量和维度。
#print(data.shape)
- 样本分割
# 使用sklearn.cross_valiation里的train_test_split模块用于分割数据
#这里的train_test_split 是常用的分割数据集的模块,应该记住
from sklearn.model_selection import train_test_split
# 随机采样25%的数据用于测试,剩下的75%用于构建训练集合。
#cross_validation.train_test_split(train_data,train_target,test_size=0.4, random_state=0)
#参数解释:
X_train, X_test, y_train, y_test = train_test_split(data[column_names[1:10]], data[column_names[10]], test_size=0.25, random_state=33)
# 查验训练样本的数量和类别分布。
#print(y_train.value_counts())
# 查验测试样本的数量和类别分布。
#print(y_test.value_counts())
- 使用模型进行训练和学习
# 从sklearn.preprocessing里导入StandardScaler。
from sklearn.preprocessing import StandardScaler
# 从sklearn.linear_model里导入LogisticRegression与SGDClassifier。
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import SGDClassifier
X_train = X_train.astype(np.float64)
X_test = X_test.astype(np.float64)
# 标准化数据,保证每个维度的特征数据方差为1,均值为0。使得预测结果不会被某些维度过大的特征值而主导。
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
# 初始化LogisticRegression与SGDClassifier。
lr = LogisticRegression(solver='liblinear')
sgdc=SGDClassifier()
# 调用LogisticRegression中的fit函数/模块用来训练模型参数。
lr.fit(X_train, y_train)
# 使用训练好的模型lr对X_test进行预测,结果储存在变量lr_y_predict中。
lr_y_predict = lr.predict(X_test)
# 调用SGDClassifier中的fit函数/模块用来训练模型参数。
sgdc.fit(X_train, y_train)
# 使用训练好的模型sgdc对X_test进行预测,结果储存在变量sgdc_y_predict中。
sgdc_y_predict = sgdc.predict(X_test)
通过以上的训练,将会产生根据预测模型预测出来的预测结果,分别存储于lr_y_predict和lr_y_predict中。我们正常的操作是将预测的结果与实际的结果y_test作比较,而对于肿瘤细胞的判定,我们的判定指标要更加复杂一些。
在医学学术的评定上,一般用阳性(Positive)和阴性(Negative)来表示患病和不患病。在此实例中,类别用2和4表示。因此我们在比较的时候应该引入以下概念:
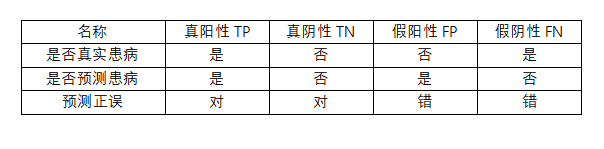
最应该注意的应该是假阳性的情况,因为误判会使得错过病人的诊治。
- 评测部分
在这里实例中,评测由四个部分组成:准确性Accuracy,召回率Recall,精确率Precision以及F1指标(F1 measure)
下面是具体的说明:
准确性=(TP+TN)/(TP+TN+FP+FN)
召回率=TP/(TP+FN) 表示被预测正确的病患数量在所有应该被检测出来的患病人群中的占比
精度=TP/(TP+FP) 表示在所有被预测为患病的人群中,真正患病的人群的占比。
F1 指标=2/((1/Precision)+(1/Recall))
# 从sklearn.metrics里导入classification_report模块。
from sklearn.metrics import classification_report
# 使用逻辑斯蒂回归模型自带的评分函数score获得模型在测试集上的准确性结果。
print ("Accuracy of LR Classifier:", lr.score(X_test, y_test))
# 利用classification_report模块获得LogisticRegression其他三个指标的结果。
print( classification_report(y_test, lr_y_predict, target_names=['Benign', 'Malignant']))
# 使用随机梯度下降模型自带的评分函数score获得模型在测试集上的准确性结果。
print( "Accuarcy of SGD Classifier:", sgdc.score(X_test, y_test))
# 利用classification_report模块获得SGDClassifier其他三个指标的结果。
print (classification_report(y_test, sgdc_y_predict, target_names=['Benign', 'Malignant']))
具体想要了解logistic原理和随机梯度下降模型的朋友可以看吴恩达老师的公开课















 2222
2222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









