







目录
1、参考文章:
1.1参考文章:xgb原论文阅读翻译
1.2 XGB算法梳理
1.3 XGB简介(比较详细的可以大概了解损失函数的作用、意义)
1.4 xgboost原理分析以及实践(详细的推导了公式,并且有手推树的例子讲解)
1.5 不平衡处理:xgboost 中scale_pos_weight、给样本设置权重weight、 自定义损失函数 和 简单复制正样本的区别(详细介绍了xgb里面scale_pos_weight,包括其影响的位置、源代码中的位置)
2、理解:
1、xgb作为一个加法串行的树模型,每一棵子树都是基于上一棵树的残差来进行训练;其计算公式是不包含权重项的(面试被问到过,主要是因为GBDT模型的加法公式中是包含权重项的);其计算公式如下所示:
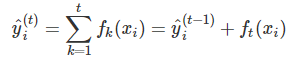
2、损失函数
每一次迭代都是为了使本次的损失函数值最小,从而再迭代更新出本棵树。
主要是通过损失函数来更新每棵树的叶子节点上的权重(这个大家应该注意一下,我是反复看了很多文章,最终在看原论文时才注意到),因为每棵树的叶子结点都会给划入此节点的样本一个“分数”,所以每次训练得到的树的叶子节点上都需要有一个“分数”。具体的损失函数及权重("分数")的更新公式如下所示:
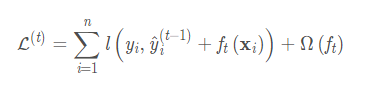 ,w("分数")的更新公式为
,w("分数")的更新公式为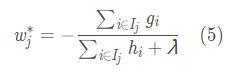 ,其中
,其中、
分别为
关于损失函数的一阶及二阶导数;
![]() 为惩罚项,T为本棵树的叶子节点树,w则为权重("分数"),每一棵树都会对应自己的惩罚项。
为惩罚项,T为本棵树的叶子节点树,w则为权重("分数"),每一棵树都会对应自己的惩罚项。
由此计算出当前树的损失。
3、每课树上节点的划分
并不是采用CART树中的基尼指数作为节点划分的依据,而是采用下述公式来选择最优划分节点:
 ;
;
缺失值的处理:在所有的贪婪算法搜索最优分裂节点中,约定将统一将缺失值划分到右子树中;
4、3.2~3.3中所提到的“关于贪婪算法选择最优分裂节点的算法”所引入的近似算法没有看明白???
5、大多数树学习算法只能处理连续型数据,因此在处理离散型数据时需要进行处理,如one-hot处理;
6、作者在4.1中指出,最耗时的部分就是数据的排序
7、学习率(或learning rate):XGB模型的计算公式是加法公式,里面的每一项都是加上本棵树的训练结果
,但是在参数里面却有一个
或learning rate,这是因为在代码实现的时候,实际上还是会给
乘上一个学习率,从而避免过拟合(在2.3节中提到,但是暂时还没找到源代码中是怎么写的);
8、xgb里面避免过拟合所采取的措施:
①正则项:L1(稀疏化,加快收敛速度)/L2(防止过拟合)正则项,两个参数分别为、
,在损失函数的计算公式中是直接乘上
的一范数、二范数;
②引入学习率与列采样;
③scale_pos_weight:根据官方文档,可以设置为负样本数/正样本数,其中标签为0的认为是负样本,标签为1的认为是正样本,本质上影响的是损失函数(github地址);
if (label == 1.0f) {
w *= _scale_pos_weight;
}3、常用的参数介绍:
①gamma:默认为0。在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。因为gamma值越大的时候,损失函数下降更多才可以分裂节点,所以树生成的时候更不容易分裂节点。范围: [0,∞];
②min_child_weight:原本表示的是损失函数的二阶导,但在大多数情况下可以理解为叶子上的最小样本数。(参考网址:“张泽荣”的回答:是在均方误损失且不加正则项的情况下,损失函数的二阶导恰好等于叶子节点上的样本数)















 4283
4283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









