










这篇论文是作者Benchmarking Detection Transfer Learning with Vision Transformers论文的扩展,没有正式出版,也没有经过同行评议。
论文研究了使用一个单一的、没有层次设计的VIT架构作为backbone用于目标检测领域,使得原始VIT经过微调就可用于检测任务而不需要重新设计一个层次的backbone进行预训练。主要有两点:
- 在单尺度的特征映射上(没有公共的FPN)构建一个简单的特征金字塔就足够了
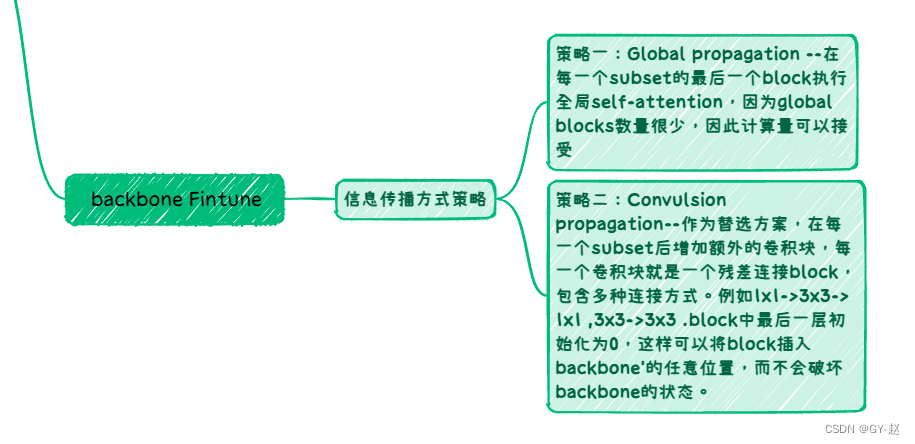
- 在很少的跨窗口传播blocks的帮助下,使用窗口注意(不移动)就足够了
原始的VIT不像CNN一样,是一个非层次的设计,从头到尾保持单一尺度的feature map。因此,在目标检测中遇到了挑战,例如多尺度的目标。一种解决方案是放弃VIT的极简主义设计,将backbone重新设计为层次性的结构,例如Swin Transformers、PvT、MVT、MVIT等工作,可以继承基于卷积网络的检测器的工作,表现出了不错的结果。
在这项工作中,作者追求一个不同的方向:只使用普通的、非层次主干的目标检测器如果这个方向成功,就可以使用原始的ViT backbone进行目标检测;这将把训练前的设计与微调需求分离开来,保持上游和下游任务的独立性,就像基于convnet的研究一样。这个方向也在一定程度上遵循了ViT“更少的归纳偏差”的哲学,以追求通用特性。由于非局部self-attention计算[可以学习平移等变特征,它们也可以从某些形式的监督或自监督前训练中学习到尺度等变特征。
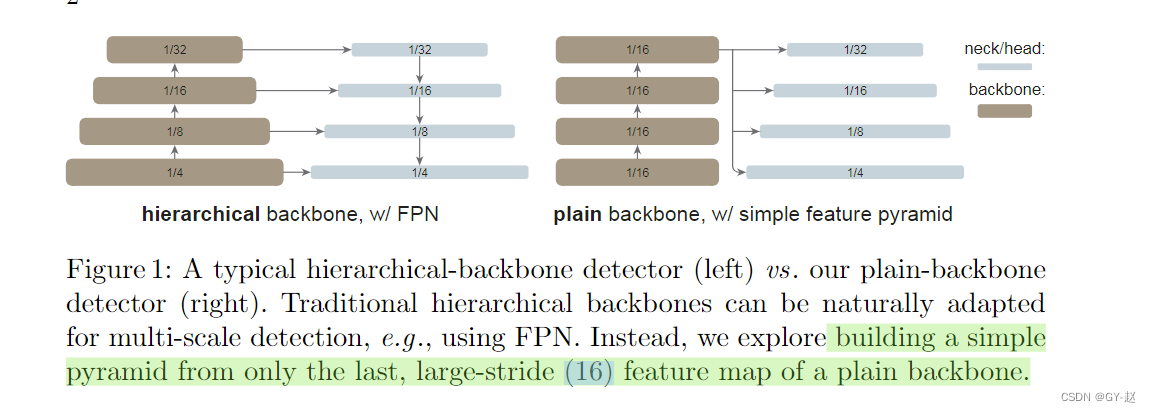
传统层次设计与作者设计对比,仅仅在VIT最后一层large-stride的特征映射上构建一个简单的金字塔。这种结构放弃了FPN设计,也不需要层次设计backbone,同时为了在高分辨率图像上更有效的提取特征,作者使用了非重叠的window attention,仅仅只有一小部分跨窗口blocks用来传递信息(可以是Global attention或卷积),重要的是这些改变只发生在微调阶段,不会影响预训练。
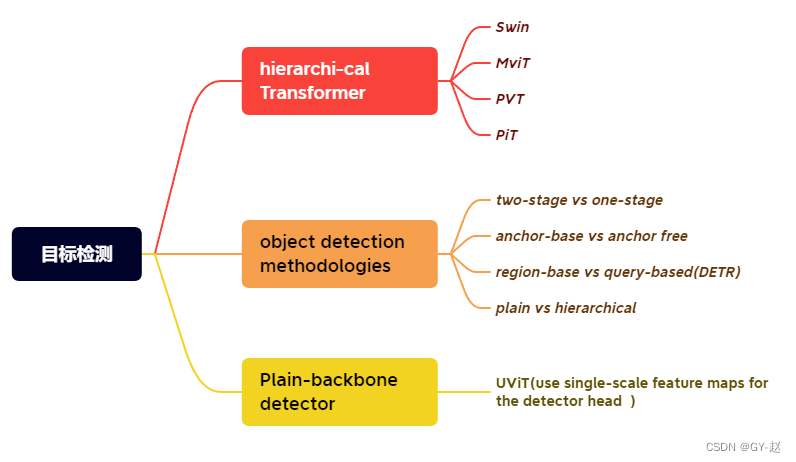
上图是根据论文制作的一个脑图,简要的分类了目标检测领域的方法或者方向。
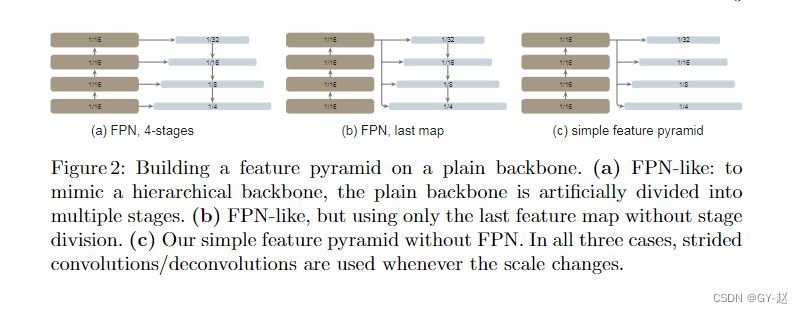
FPN是为目标检测任务构建网络内金字塔的常用解决方案,对于层次化结构的backbone来说,FPN能够通过自顶向下和横向连接结合一开始的高分辨率特征与最后阶段的强化特征。但对于VITs来说,它不是层次化结构,backbone的特征映射始终具有相同的分辨率,那么FPN构建的基础也就不存在了。
上图是simple feature pyramid 以及两个FPN变种的比较,图 a、b 是FPN变种,才有类似的操作,图a是人为将整个backbone划分四个stage 模仿层次化的backbone,图b只对最后的block进行人为划分。图c是作者采用的方式,只使用backbone最后一层特征映射,其应该具有最强特征。通过一系列卷积和反卷积操作,并行化产生多尺度的特征映射。也就是在VIT基础上通过卷积方式产生不同分辨率的feature map
对feature map的理解如下:根据stride的大小产生不同大小的feature map

在消融实验中,作者也验证了simple feature map的有效性。
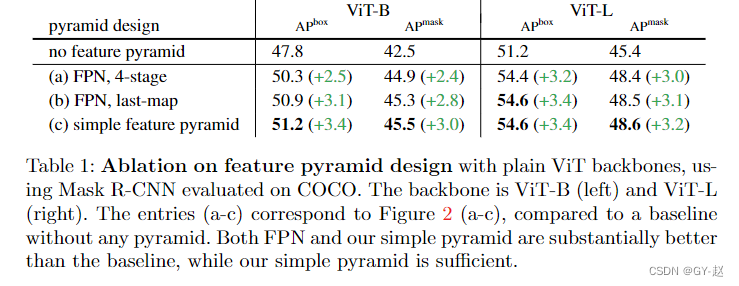
其他内容感觉不太重要 ,可以论文里浏览一下。















 2181
2181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









