







GPU 工作原理
前面的章节对 AI 计算体系和 AI 芯片基础进行讲解,在 AI 芯片基础中关于通用图形处理器 GPU 只是简单地讲解了主要概念,本章将从 GPU 硬件基础和英伟达 GPU 架构两个方面讲解 GPU 的工作原理。英伟达 GPU 有着很长的发展历史,整体架构从 Fermi 到 Blankwell 架构演变了非常多代,其中和 AI 特别相关的就有 Tensor Core 和 NVLink。
本节首先讲解 CPU 和 GPU 架构的区别,之后以 A X + Y AX+Y AX+Y这个例子来探究 GPU 是如何做并行计算的,为了更好地了解 GPU 并行计算,对并发和并行这两个概念进行了区分。此外会讲解 GPU 的缓存机制,因为这将涉及到 GPU 的缓存(Cache)和线程(Thread)。
GPU的工作原理是一个复杂但有趣的主题,涉及到硬件基础、架构设计和并行计算等多个方面。以下是对GPU工作原理的详细解释:
首先,我们来探讨CPU和GPU架构的主要区别。CPU设计的主要目的是运行少量复杂任务,处理大量离散且不相关的任务系统。而GPU则专门用于执行大量简单任务,特别是那些可以分解成许多独立运行的小块任务。这种架构差异使得GPU在图形渲染、科学计算和人工智能等领域具有显著优势。
接下来,我们以AX+Y这个简单的数学运算为例,来探究GPU是如何进行并行计算的。在CPU中,这种运算可能是按顺序逐个执行的。但在GPU中,可以将每个运算分配给一个独立的处理单元(例如CUDA核心),从而实现并行计算。这意味着多个AX+Y运算可以同时进行,大大提高了计算效率。
为了更好地理解GPU的并行计算,我们需要区分“并发”和“并行”这两个概念。并发是指多个任务在同一时间段内交替执行,而并行则是指多个任务在同一时刻同时执行。GPU通过其大量的处理单元,实现了真正的并行计算,使得多个任务可以同时进行,大大提高了计算速度。
此外,GPU的缓存机制也是其高效工作的重要组成部分。缓存是为了减少内存访问延迟而设计的,GPU通过多级缓存(如L1、L2缓存)来优化数据访问。当处理单元需要数据时,首先会尝试从缓存中获取,如果缓存中没有,才会去主存中读取。这种机制大大提高了数据访问效率,从而提升了GPU的整体性能。
最后,我们来看看英伟达的GPU架构。英伟达在其GPU架构中引入了许多创新技术,如Tensor Core和NVLink。Tensor Core是专门用于执行张量计算的单元,它支持并行执行FP32与INT32运算,这在人工智能领域尤为重要。而NVLink则是一种高速通信接口,用于连接多个GPU或CPU与GPU,实现更高效的数据传输和协同工作。
CPU 和 GPU 区别
在正式开始本章内容之前,首先明确什么是 GPU ,以及 GPU 和 CPU 的主要区别是什么?
现在探讨一下 CPU 和 GPU 在架构方面的主要区别, CPU 即中央处理单元(Central Processing Unit),负责处理操作系统和应用程序运行所需的各类计算任务,需要很强的通用性来处理各种不同的数据类型,同时逻辑判断又会引入大量的分支跳转和中断的处理,使得 CPU 的内部结构异常复杂。
GPU 即图形处理单元(Graphics Processing Unit),可以更高效地处理并行运行时复杂的数学运算,最初用于处理游戏和动画中的图形渲染任务,现在的用途已远超于此。两者具有相似的内部组件,包括
CPU和GPU在多个方面存在显著的区别。
首先,从功能上来看,CPU主要负责解释计算机指令以及处理计算机软件中的数据,控制计算机的所有硬件资源(如存储器、输入输出单元)进行运算和调配。而GPU则主要用于处理图形和图像相关的任务,如实时图形渲染、图像处理、视频解码和编码等,并在计算过程中减少了对CPU的依赖。
其次,两者的处理技术不同。CPU采用串行处理技术,可以赋予更多的指令来运行,从而更快地处理数据。而GPU则采用并行处理技术,可以运行多个线程同时处理数据,从而更快完成任务。
在存储方面,CPU采用高速缓存来存储数据,而GPU没有高速缓存,但GPU具有更大的内存容量,可以存储更多的数据。
此外,功耗方面也有所不同。一般来说,CPU的功耗比GPU要高。这是因为CPU需要处理更多的复杂任务和系统级操作,而GPU则专注于图形和并行计算。
从架构上来看,CPU的架构是为了区分不同类型CPU的重要标示,例如Intel和AMD的CPU采用X86架构,而IBM的CPU则采用PowerPC架构。而GPU的架构则包括CUDA核心、内存系统、高速缓存和缓存行、TPC/SM以及特定功能的核心(如Tensor Core和RT Core)等,这些组件共同协作以实现高效的图形处理和计算任务。
CPU和GPU在功能、处理技术、存储、功耗以及架构等方面存在显著的差异。CPU是计算机的核心处理器,负责整体运算和协调;而GPU则专注于图形处理和并行计算,为图形渲染、视频处理以及大规模计算任务提供强大的支持。
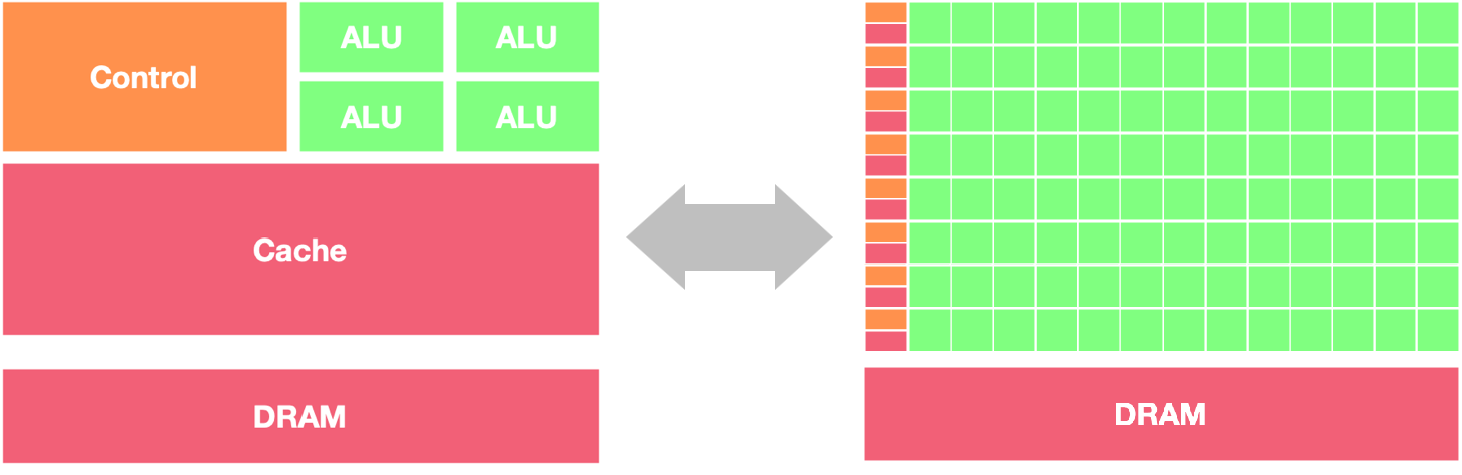
GPU 和 CPU 在架构方面的主要区别包括以下几点:
-
并行处理能力: CPU 拥有少量的强大计算单元(ALU),更适合处理顺序执行的任务,可以在很少的时钟周期内完成算术运算,时钟周期的频率很高,复杂的控制逻辑单元(Control)可以在程序有多个分支的情况下提供分支预测能力,因此 CPU 擅长逻辑控制和串行计算,流水线技术通过多个部件并行工作来缩短程序执行时间。GPU 控制单元可以把多个访问合并成,采用了数量众多的计算单元(ALU)和线程(Thread),大量的 ALU 可以实现非常大的计算吞吐量,超配的线程可以很好地平衡内存延时问题,因此可以同时处理多个任务,专注于大规模高度并行的计算任务。
-
内存架构: CPU 被缓存 Cache 占据了大量空间,大量缓存可以保存之后可能需要访问的数据,可以降低延时; GPU 缓存很少且为线程(Thread)服务,如果很多线程需要访问一个相同的数据,缓存会合并这些访问之后再去访问 DRMA,获取数据之后由 Cache 分发到数据对应的线程。 GPU 更多的寄存器可以支持大量 Thread。
-
指令集: CPU 的指令集更加通用,适合执行各种类型的任务; GPU 的指令集主要用于图形处理和通用计算,如 CUDA 和 OpenCL。
-
功耗和散热: CPU 的功耗相对较低,散热要求也相对较低;由于 GPU 的高度并行特性,其功耗通常较高,需要更好的散热系统来保持稳定运行。
因此,CPU 更适合处理顺序执行的任务,如操作系统、数据分析等;而 GPU 适合处理需要大规模并行计算的任务,如图形处理、深度学习等。在异构系统中, GPU 和 CPU 经常会结合使用,以发挥各自的优势。
GPU 起初用于处理图形图像和视频编解码相关的工作。 GPU 跟 CPU 最大的不同点在于, GPU 的设计目标是最大化吞吐量(Throughout),相比执行单个任务的快慢,更关心多个任务的并行度(Parallelism),即同时可以执行多少任务;CPU 则更关心延迟(Latency)和并发(Concurrency)。
CPU 优化的目标是尽可能快地在尽可能低的延迟下执行完成任务,同时保持在任务之间具体快速切换的能力。它的本质是以序列化的方式处理任务。 GPU 的优化则全部都是用于增大吞吐量的,它允许一次将尽可能多的任务推送到 GPU 内部。然后 GPU 通过大数量的 Core 并行处理任务。
处理器带宽(Bandwidth)、延时(Lantency)和吞吐(Throughput)
带宽:处理器能够处理的最大的数据量或指令数量,单位是 Kb、Mb、Gb;
延时:处理器执行指令或处理数据所需的时间,传送一个数据单元所需要的时间,单位是 ms、s、min、h 等;
吞吐:处理器在一定时间内从一个位置移动到另一个位置的数据量,单位是 bps(每秒比特数)、Mbps(每秒兆比特数)、Gbps(每秒千比特数),比如在第 10s 传输了 20 bit 数据,因此在 t=10 时刻的吞吐量为 20 bps。
解决带宽相比较解决延时更容易,线程的数量与吞吐量成正比,吞吐量几乎等于带宽时说明信道使用率很高,处理器系统设计所追求的目标是提高带宽的前提下,尽可能掩盖传送延时,组成一个可实现的处理器系统。
GPU 工作原理
GPU的工作原理可以概括为以下步骤:
并行处理:GPU内部包含大量的处理单元(如CUDA核心),这些处理单元能够同时执行指令和计算操作。它们特别适合处理可以并行执行的任务,这意味着多个任务可以同时进行,从而大大提高了计算效率。
数据并行:GPU能够处理大量的数据并行任务。它将需要计算的数据分成小块,然后对每个小块进行并行计算。这种数据并行的方式使得图形渲染、图像处理等任务能够在GPU上快速完成。
图形渲染管线:GPU包含一个图形渲染管线,这是一个由多个阶段组成的流水线。每个阶段负责不同的计算或处理任务,如顶点处理、几何处理、光栅化等。通过流水线的方式,GPU能够并行执行不同阶段的计算,从而加速图形渲染的过程。
内存管理:GPU拥有自己的专用内存,用于存储和处理图形和图像数据。与CPU的内存相比,GPU的内存带宽更高,能够更快地读写数据,这有助于加速计算和处理任务。
特定功能核心:现代GPU还引入了特定的功能核心,如Tensor Core和RT Core。Tensor Core用于执行张量计算,支持并行执行各种数学运算,这在深度学习和人工智能领域尤为重要。RT Core则负责光线追踪加速,用于更真实地模拟光影效果。
GPU的工作原理是通过并行处理、数据并行、图形渲染管线、高效的内存管理以及特定功能核心等技术手段,实现高效的图形渲染和大规模计算任务。这使得GPU在图形处理、科学计算、人工智能等领域发挥着重要作用。
首先通过 A X + Y AX+Y AX+Y这个加法运算的示例了解 GPU 的工作原理, A X + Y AX+Y AX
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3026
3026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











