







 AIGC(Artificial Intelligence Generated Content)技术利用生成对抗网络、大型预训练模型等AI方法,如GPT-4、Sora和ChatGPT,产生高质量内容。ChatGPT是大型语言模型的人工智能聊天机器人,而Sora是OpenAI的视频生成模型,能理解物理世界。微调技术如RLHF和LoRA用于改进模型性能。大模型的发展带来了AI在自然语言处理、视频生成等领域的突破,但也引发关于安全、隐私和认知能力的讨论。
AIGC(Artificial Intelligence Generated Content)技术利用生成对抗网络、大型预训练模型等AI方法,如GPT-4、Sora和ChatGPT,产生高质量内容。ChatGPT是大型语言模型的人工智能聊天机器人,而Sora是OpenAI的视频生成模型,能理解物理世界。微调技术如RLHF和LoRA用于改进模型性能。大模型的发展带来了AI在自然语言处理、视频生成等领域的突破,但也引发关于安全、隐私和认知能力的讨论。
AIGC
AIGC(Artificial Intelligence Generated Content)是指基于生成对抗网络、大型预训练模型等人工智能的技术方法,通过已有数据的学习和识别,以适当的泛化能力生成相关内容的技术。AIGC的爆发得益于GAN、CLIP、Transformer、Diffusion、预训练模型、多模态技术、生成算法等技术的累积融合。这种技术对于人类社会、人工智能的意义是里程碑式的,因为它为人类社会打开了认知智能的大门,推动了社会的数字化转型进程。
- Large Language Model(LLM):大型语言模型是指具有数千亿(甚至更多)参数的语言模型,它们是通过在大规模文本数据上进行训练而得到的。这些模型基于Transformer架构,能够更好地理解自然语言,并能根据给定的上下文生成高质量的文本。常见的LLM包括GPT-3、PaLM、Galactica和LLaMA等。
- ChatGPT:ChatGPT是一种基于大型语言模型的人工智能聊天机器人,它能够与人类进行自然而流畅的对话。ChatGPT通过大规模语料库的训练,具备了丰富的知识和对话能力,可以回答各种问题,提供有用的信息和建议。
- PaLM/Bard(Google):PaLM是Google发布的大型语言模型,它在高质量文本上训练了数十亿个参数,并在多个自然语言处理任务上取得了优异的表现。Bard是Google的聊天机器人,它基于PaLM模型,提供了更自然、更智能的对话体验。
- LLaMA(Meta):LLaMA是Meta(Facebook母公司)提出的大型语言模型,它同样基于Transformer架构,并通过大规模数据集训练,可以在多种任务中表现出色,包括文本分类、文本生成、问答等。
- Github Copilot:Github Copilot是一个基于大型语言模型的代码辅助工具,它可以为开发人员提供智能的代码补全和建议。通过学习大量的代码库和文档,Github Copilot可以理解开发人员的编程意图,并提供高质量的代码建议,帮助开发人员更高效地编写代码。
大模型的发展是一个持续的过程,随着技术的不断进步和计算能力的提升,大型语言模型的规模和能力也在不断提升。BERT预训练是一种常用的方法,它利用大量的无标注文本数据进行预训练,使得模型能够学习到丰富的语言知识和上下文信息,从而提高了模型的泛化能力和鲁棒性。这种预训练的方法已经成为大型语言模型训练的标准流程之一。
概要
- 术语
- Large Language Model(LLM)
- ChatGPT
- PaLM/Bard(Google)
- Llama(Meta)
- Github Copilot
- 大模型的发展
- https://arxiv.org/pdf/2304.13712
- BERT pretrain的概念
大模型简要介绍
大模型是指具有大规模参数和复杂计算结构的机器学习模型,通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。这些模型的设计目的是提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。
大模型的主要工作是通过训练海量数据来学习复杂的模式和特征,并据此生成预测或进行决策。在大模型的输入方面,数据通常以编码的形式呈现,如word embedding、one-hot编码、文字或整数等。这些编码方式帮助模型理解和处理输入数据。
大模型的关键要素包括数据、算力、训练技术和模型结构。其中,数据是大模型训练的基础,需要大量的高质量数据进行微调。算力是指训练大模型所需的计算资源,包括高性能计算机、GPU等。训练技术则包括各种优化算法和技巧,如RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)、prefix tuning、hard/soft prompt tuning、SFT(Supervised Fine-Tuning,有监督微调)和retrieval augment等,这些技术可以提高模型的训练效率和性能。模型结构则是指大模型的网络架构,它决定了模型如何处理输入数据和生成输出。
影响大模型的因素主要包括信任、安全、隐私和认知。由于大模型能够处理大量敏感数据,因此必须确保其安全性和隐私性。同时,大模型的预测结果必须可靠和准确,以建立用户的信任。此外,大模型还需要具备认知能力,能够理解和处理复杂的人类语言和图像数据。
-
表面上做什么事情:不断根据前文生成“下一个”词
-
大模型的输入
- 编码:word embedding、one-hot、文字、整数
-
关键要素
-
数据
- 微调数据如何大量获得
-
算力
-
训练技术:RLHF、prefix tuning、hard/soft prompt tuning、SFT、retrieval augment
-
模型结构
-
-
影响要素
- 信任
- 安全
- 隐私
- 认知
历史发展
- emergent ability
- How much bigger can/should LLMs become?
- https://arxiv.org/abs/2206.07682
- 100TB=50000Billion
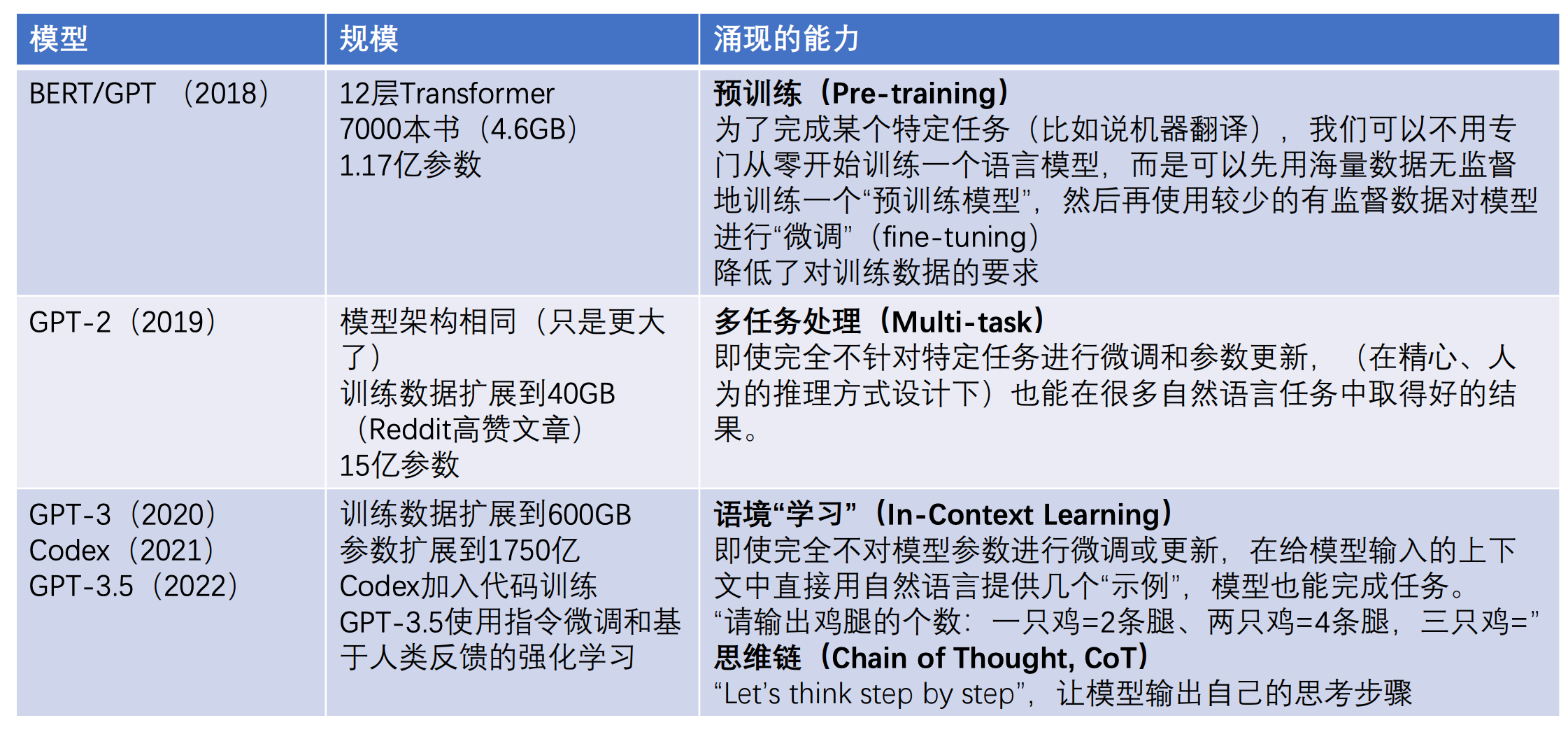
- Note
- GPT-3.5相比于GPT-3,参数量变化不大,效果差距很大,这是由于微调技术
算法
Attention Is All You Need
-
The best performing models also connect the encoder and decoder through an attention mechanism.
- Encoder: 映射到另一个语义空间
-
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.
-
模型结构是什么?
- 过N个注意力层,再过一个full connection
- Attention(Q,K, V) = softmax(QK^T/sqrt(d_k))V
-
模型参数是什么?
- 词嵌入向量
- learnable?
- 将词嵌入向量转化为q、k、v向量的三个矩阵和bias
- 词嵌入向量
-
模型输出是什么?
- 全连接层的结果,一个长度为全部词汇数量的向量
- 如何增强随机性:
- top-k采样
-
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1
- 左边encoder,右边decoder
- Encoder: 自注意力
- Decoder:Q用outputs embedding做masked attention后的结果,K、V用encoder结果
- 表征向量512维
- masked multi-head attention保证输出对输入的感知序列不会超出长度
- 自注意力机制:Q(输入矩阵)、K(字典)、V
- 用1/(dk)^(1/2) scale了一下QK的乘法,可能是为了防止gradient太小
- Dot product的结果方差比additive attention的方差大
- 左边encoder,右边decoder
-
Multi-head attention
Implementation
https://tensorflow.org/text/tutorials/transformer
GPT-2
https://jalammar.github.io/illustrated-gpt2/
ChatGPT
-
对话式大型语言模型:https://openai.com/blog/chatgpt/
-
自回归语言模型:帮助背下来事件知识
-
大语言模型:百亿参数以上
- 不好做finetune,成本高
- 用prompt作为输入,generated text作为输出
- 语言知识 + 事件知识,事件知识更需要大模型
-
未来:AGI(Artificial General Intelligence);教会它使用工具
-
-
三个关键技术:
- In-Context Learning 情景学习
- 在前向中学习
- 涌现能力:百亿参数规模之后,能力突然提升,改变传统学习范式
- 大幅降低下游任务开发成本
- 《Rethinking the Role of Demonstrations: What Ma
- In-Context Learning 情景学习
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











