







Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
摘要
多年来,anchor-based检测器一直主导着目标检测。最近,anchor-free检测器由于FPN和Focal Loss的引入而受到广泛关注。文章中,我们首先提出了anchor-based和anchor-free检测器的显著区别主要在于如何定义正、负训练样本,从而导致两者之间的性能差距。如果他们在训练中对正样本和负样本采取相同的定义,无论从一个anchor还是一个point回归,最终的表现都没有明显的差异。由此可见,如何选取正、负训练样本对当前目标检测具有重要意义。然后,我们提出了一种自适应训练样本选择(ATSS),根据目标的统计特征自动选择正样本和负样本。它显著地提高了anchor-based和anchor-free检测器的性能,并弥补了两者之间的差距。最后,我们讨论了在图像上每个位置平铺多个anchor点来检测目标的必要性。在COCO数据集上进行的大量实验支持了我们的上述分析和结论。随着新引入的ATSS,我们在不引入任何开销的情况下,将最先进的检测器大大提高到50.7%的AP。
引言
-
当前Anchor-free detectors可以分为两种类型:
• Keypoint-based:Cornernet、Centernet
• Center-based:FCOS、Foveabox


-
Anchor-free和Anchor-based方法如上图所示,可以看出来两种方法结构非常相似,Anchor-free是将点作为预设值的样本而不是anchor。它们之间有三个主要的区别:
(1) 每个位置的anchor的数量。RetinaNet每个位置设置几个anchor,而FCOS设置一个anchor每个位置;
(2) 正、负样本的定义。RetinaNet是根据IOU阈值设定,FCOS使用空间和尺度的限制来确定正负样本;
(3) 回归开始状态。RetinaNet将目标边界框从预置anchor框中回归,FCOS从点定位目标。 -
本文的创新点:
(1) 基于上述分析的区别,先指出了anchor-based检测与anchor-free检测的本质区别;
(2) 提出了一种自适应训练样本选择(ATSS),根据目标的统计特征自动选择正样本和负样本;
(3) 讨论了在图像上每个位置平铺多个anchor点来检测目标的必要性。
正文
一. Anchor-base和Center-base的区别?
有读过FCOS的朋友还记得, FCOS是先判定正负样本的中心点,然后以中心点来回归boundingbox的:

其实这种方式和RetinaNet这种anchor-base的方法本质上大同小异,只不过一个是在Anchor的基础上做回归,另一个把Anchor换成了中心点而已。文章中首先探究了FCOS相比RetinaNet有一些improvements,包括:
GroupNorm
GIoU
GT Box
Centerness
Scalar
把这些improvements用在RetinaNet上:

也能够使RetinaNet从AP32.5提升到37,这样二者之间的gap只有0.8了,而这0.8的gap可能来自于两点:
- Classification的方式不同,即正负样本的选取方式不同
- Regression的方式不同,一个基于anchor,一个基于point
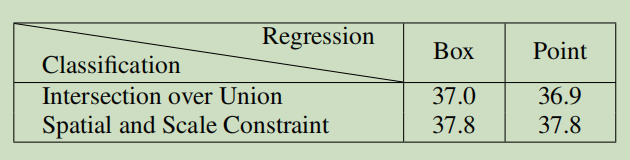
作者通过试验证明了,anchor-base和anchor-free的gap主要来自于第一点:classification,及核心区别在于二者正负样本的选取方式不同。具体有什么样的不同,如下图:

第一行是RetinaNet,第二行是FCOS。
对于RetinaNet,其回归的基点是anchor,首先要判定哪些anchor是正样本,哪些anchor是负样本,然后在正样本anchor的基础上再做位置的回归。而判定anchor是否是正样本,是通过计算anchor和groundtruth的IoU来完成的,这样做的缺陷很明显,anchor是正样本还是负样本非常受限于anchor的设计,比如第一行RetinaNet中可以看到,蓝色的groundtruth包含了6个anchors,但是受限于anchor的大小,他们的IoU没有达到阈值要求,因此这些anchor都被判定成了负样本,显然这样是不太合理的。
而对于FCOS,作为center-base的方式,是通过判定feature上的每个点是否落入到groundtruth中来判定正负样本的,很显然这样就摆脱了类似于anchor这种受限于hard-craft的缺陷, 这也是FCOS效果优于RetinaNet的原因:基于center的方式,能够更有效的选取更多的正样本(不过其实这个点在FCOS的论文中也有提到过)。
二. 一种“自适应”的训练样本选取方式ATSS
既然我们已经知道,Center-base和Anchor-base的区别在于正负样本的选取上,那怎样去弥补这种缺陷呢?作者提出了一种Anchor-base的基础上,自适应选取正负样本的方式,ATSS。
算法流程如下
- 对于每个groundtruth,计算每个anchor到groundtruth的L2 distance,保留距离较近的anchor作为备选正样本anchor集合 C g C_g Cg
- 对于备选正样本anchor C g C_g Cg中的每个anchor, 计算和其对应groudtruth的IoU D g D_g Dg,然后计算 D g D_g Dg的均值 m g m_g mg和标准差 v g v_g vg
- 选取 t g = m g + v g t_g=m_g+v_g tg=mg+vg作为IoU的阈值,只有 C g C_g Cg中与ground truth IoU大于阈值 t g t_g tg的anchor被选为正样本anchor
- 保持正负anchor的总数一定
作者还证明了算法对于ATSS中anchor的大小这个超参数设计不敏感,达到了自适应。
几点思考
- 在知乎中很多大佬都对这篇论文发表了看法,ATSS仍旧有硬伤,本质上还是有设计上的超参数存在,hard-craft的痕迹很重,实际上我也觉得离“adaptive”这个目标还有一定距离。
- 文章的实验和分析还是很清晰的,读完这篇文章我们应该能体会到,anchor的这种方式本质上还是存在着label-assign的问题,能解决这个问题,也许能使得performance显著的提升。
参考资料
- https://blog.csdn.net/watermelon1123/article/details/103592195
- https://blog.csdn.net/weixin_42096202/article/details/103732404
- https://www.zhihu.com/question/359595879
觉得有用可以关注我的公众号CV伴读社
















 173
173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









