







网上很多关于Faster RCNN的介绍,不过这一片算是比较全的了,不仅包括整体流程、思想的介绍,也包括各个实现较为深入的介绍。大概内容记录如下(仅记录目前我感兴趣的部分):
1 各种CNN模型以及数据库
自从接触基于深度学习的目标检测这一领域以来,经常遇到各种CNN模型,比如ZF模型、VGG模型等等。同时也接触到各种数据集如PASCAL VOC、MNIST、ImageNet等等,博文深度学习常用的Data Set数据集和CNN Model总结 进行了总结。
2 RCNN系列方法的介绍
RCNN算法
RCNN算法分为4个步骤
- 一张图像生成1K~2K个候选区域(采用SS方法)
- 对每个候选区域,使用深度网络提取特征
- 特征送入每一类的SVM 分类器,判别是否属于该类
- 使用回归器精细修正候选框位置
位置精修
目标检测问题的衡量标准是重叠面积:许多看似准确的检测结果,往往因为候选框不够准确,重叠面积很小。故需要一个位置精修步骤。
回归器
对每一类目标,使用一个线性脊回归器进行精修。正则项λ=10000。 输入为深度网络pool5层的4096维特征,输出为xy方向的缩放和平移。
训练样本
判定为本类的候选框中,和真值重叠面积大于0.6的候选框。 可以看出该网络重复计算量很大,2K个候选框单独用CNN提取特征,再分类!
Fast RCNN
Fast RCNN方法解决了RCNN方法三个问题:
问题一:测试时速度慢
RCNN一张图像内候选框之间大量重叠,提取特征操作冗余。
本文将整张图像归一化后直接送入深度网络。在邻接时,才加入候选框信息,在末尾的少数几层处理每个候选框。
问题二:训练时速度慢
原因同上。
在训练时,本文先将一张图像送入网络,紧接着送入从这幅图像上提取出的候选区域。这些候选区域的前几层特征不需要再重复计算。
问题三:训练所需空间大
RCNN中独立的分类器和回归器需要大量特征作为训练样本。
本文把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
Faster RCNN
从RCNN到fast RCNN,再到本文的faster RCNN,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。所有计算没有重复,完全在GPU中完成,大大提高了运行速度。
faster RCNN可以简单地看做“区域生成网络+fast RCNN“的系统,用区域生成网络代替fast RCNN中的Selective Search方法。本篇论文着重解决了这个系统中的三个问题:
1. 如何设计区域生成网络
2. 如何训练区域生成网络
3. 如何让区域生成网络和fast RCNN网络共享特征提取网络
R-CNN中的boundingbox回归
下面先介绍R-CNN和Fast R-CNN中所用到的边框回归方法。
- 什么是IOU
-
为什么要做Bounding-box regression?
如上图所示,绿色的框为飞机的Ground Truth,红色的框是提取的Region Proposal。那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准(IoU<0.5),那么这张图相当于没有正确的检测出飞机。如果我们能对红色的框进行微调,使得经过微调后的窗口跟Ground Truth更接近,这样岂不是定位会更准确。确实,Bounding-box regression 就是用来微调这个窗口的。 -
回归/微调的对象是什么?
- Bounding-box regression(边框回归)
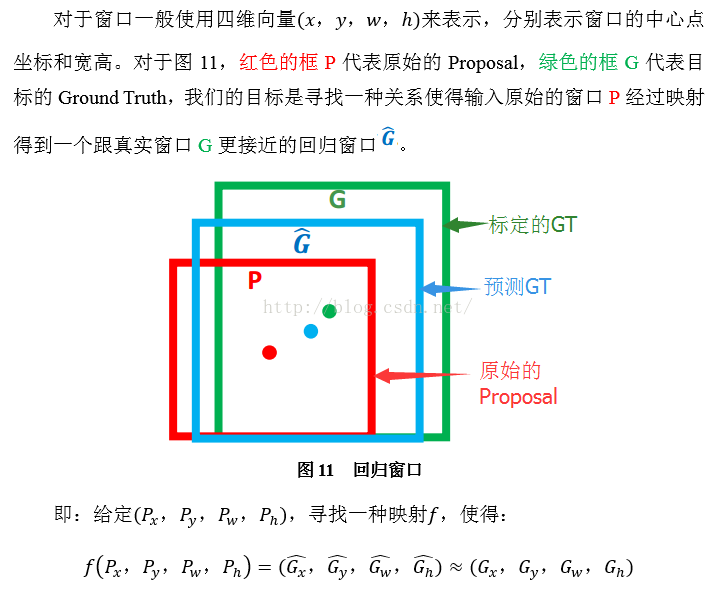
那么经过何种变换才能从图11中的窗口P变为窗口呢?比较简单的思路就是:
注意:只有当Proposal和Ground Truth比较接近时(线性问题),我们才能将其作为训练样本训练我们的线性回归模型,否则会导致训练的回归模型不work(当Proposal跟GT离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理)。这个也是G-CNN: an Iterative Grid Based Object Detector多次迭代实现目标准确定位的关键。
线性回归就是给定输入的特征向量X,学习一组参数W,使得经过线性回归后的值跟真实值Y(Ground Truth)非常接近。即。那么Bounding-box中我们的输入以及输出分别是什么呢?
输入:这个是什么?输入就是这四个数值吗?其实真正的输入是这个窗口对应的CNN特征,也就是R-CNN中的Pool5feature(特征向量)。(注:训练阶段输入还包括 Ground Truth,也就是下边提到的)
输出:需要进行的平移变换和尺度缩放,或者说是
。我们的最终输出不应该是Ground Truth吗?是的,但是有了这四个变换我们就可以直接得到Ground Truth,这里还有个问题,根据上面4个公式我们可以知道,P经过
。
的确,这四个值应该是经过 Ground Truth 和Proposal计算得到的真正需要的平移量和尺度缩放。
这也就是R-CNN中的:
那么目标函数可以表示为是输入Proposal的特征向量,
是要学习的参数(*表示
,也就是每一个变换对应一个目标函数),是得到的预测值。我们要让预测值跟真实值差距最小,得到损失函数为:
函数优化目标为:
利用梯度下降法或者最小二乘法就可以得到 。
。


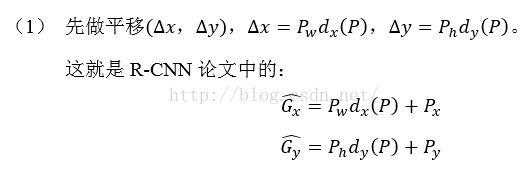

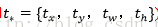
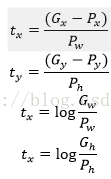
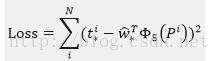
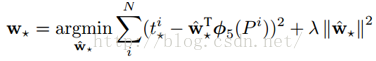















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









