






聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。主要介绍的是K-Means和bisecting K-means算法以及凝聚层次聚类算法。

K均值算法:优点:容易理解,聚类效果不错,算法复杂度低。缺点:K值需要人为设定,不同K值得到的结果不一样;为了克服K-Means算法收敛于局部最小值的问题,提出了一种二分K-均值。

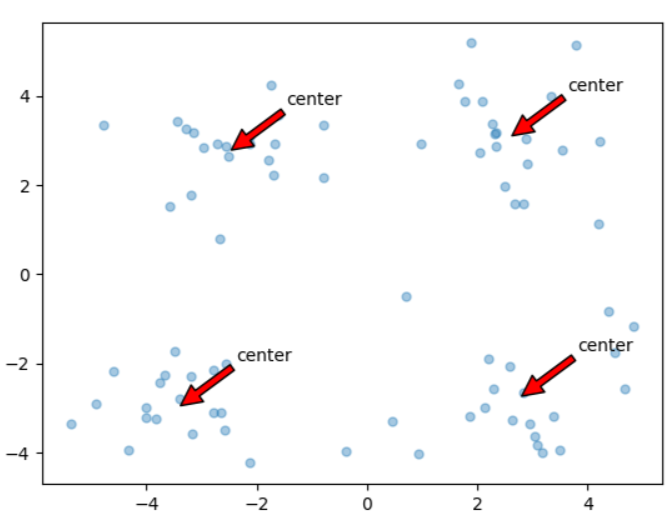
K-MEANS


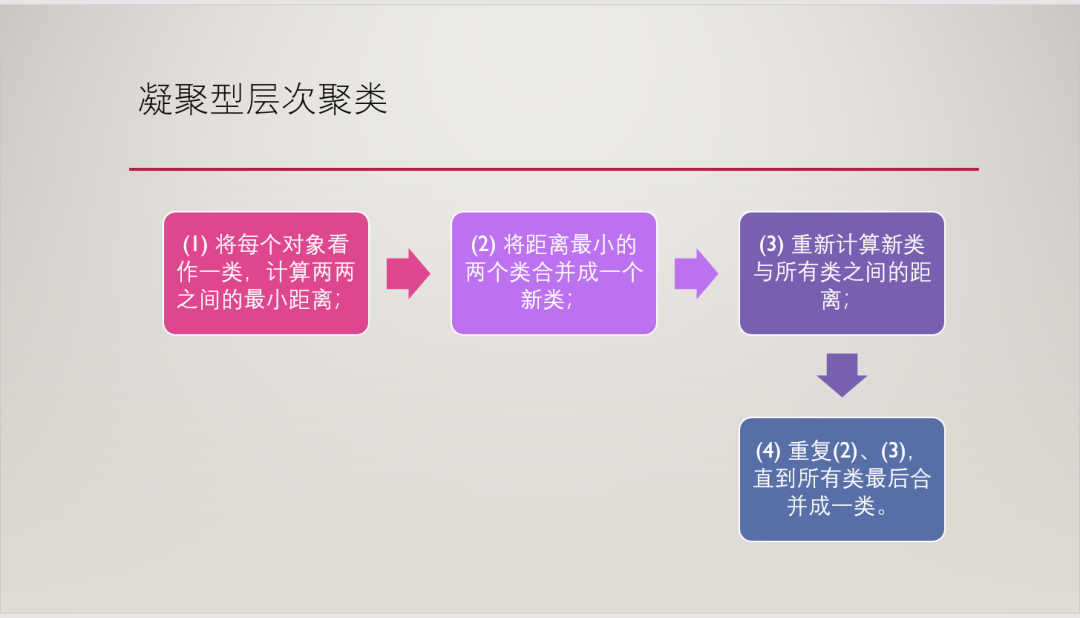
凝聚层次聚类算法又叫自下而上算法。
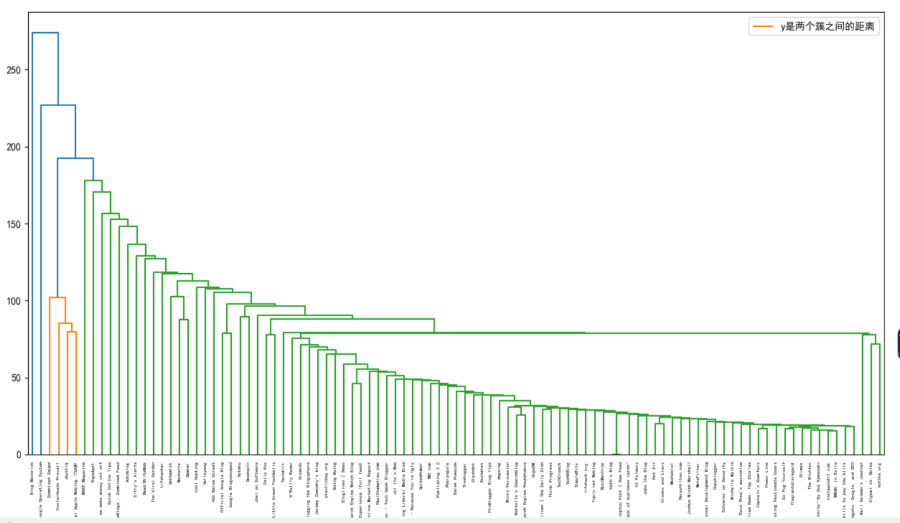
层次聚类算法的实现。

 本文介绍了聚类分析的基本概念,重点讲解了K-Means算法(包括其优点如易懂和低复杂度,以及缺点如K值设定和局部最小值问题),并提到了为改进K-Means而设计的二分K-均值算法,以及凝聚层次聚类(自下而上)算法的实现。
本文介绍了聚类分析的基本概念,重点讲解了K-Means算法(包括其优点如易懂和低复杂度,以及缺点如K值设定和局部最小值问题),并提到了为改进K-Means而设计的二分K-均值算法,以及凝聚层次聚类(自下而上)算法的实现。
聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。主要介绍的是K-Means和bisecting K-means算法以及凝聚层次聚类算法。
K均值算法:优点:容易理解,聚类效果不错,算法复杂度低。缺点:K值需要人为设定,不同K值得到的结果不一样;为了克服K-Means算法收敛于局部最小值的问题,提出了一种二分K-均值。
K-MEANS
凝聚层次聚类算法又叫自下而上算法。
层次聚类算法的实现。











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




















 860
860







