






摘要:本文先简单介绍一维卷积神经网络,随后通过代码和文字讲述如何通过一维卷积神经网络实现IMDB的情感分类问题。
前言
卷积神经网络在计算机视觉上表现出色,原因在于它能够进行卷积运算,从局部输入图块中提取特征,并能够将表示模块化,同时可以高效利用数据。这些性质让卷积神经网络在计算机视觉领域表现优异,同时也让它对序列处理特别高效。
对于一些序列问题,这种一维卷积神经网络的效果可以媲美RNN,而且计算代价要小得多,计算速度要快的多。
理解序列数据的一维卷积
一维卷积层可以识别序列中的局部模式,因为对每个序列段执行相同的输入变换,所以在句子中的某个位置学到的模式稍后可以在其他位置被识别,这使得一维卷积神经网络具有平移不变性。
举例:使用大小为5的卷积窗口处理字符序列的一维卷积神经网络,应该能够学习长度不大于5的单词或单词片段,并且能够在输入句子中的任何位置识别这些单词或单词段。
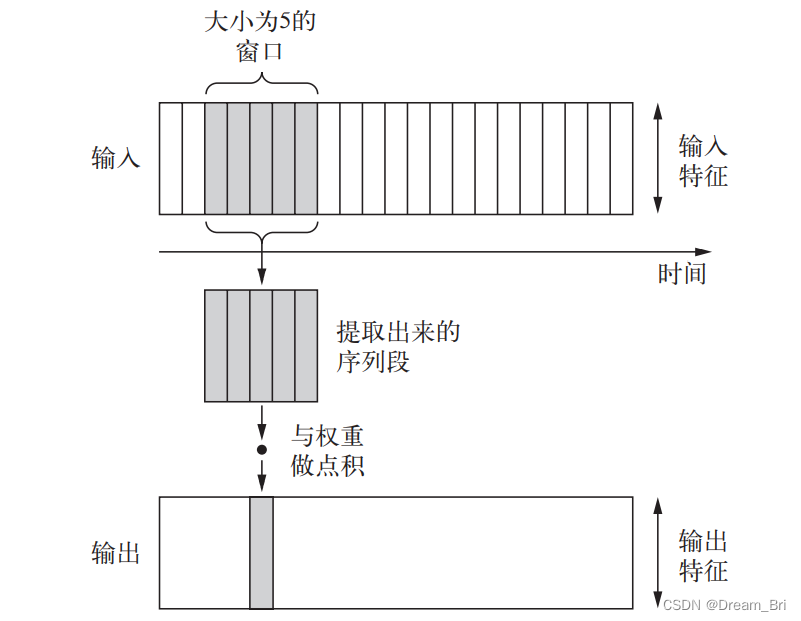
池化运算
池化运算在卷积神经网络中用于对图像张量或者序列张量进行空间下采样。一维池化运算是从输入中提取一维序列段(即子序列),然后输出其最大值(最大池化)或平均值(平均池化)。与二维卷积神经网络一样,该运算也是用于降低一维输入的长度(子采样)。
用一维卷积神经网络实现IMDB情感分析
在此使用的神经网络架构是基于Keras, 其中网络架构所使用的 Conv1D 层,其接口与二维图像处理中所使用的Conv2D类似。它接收的输入形状是
(samples, time, features) 的三维张量,并同样返回类似形状的三维张量。
我们来构建一个简单的两层一维卷积神经网络,并将其应用于我们熟悉的 IMDB 情感分类任务。
准备IMDB数据
from keras.datasets import imdb
from keras.preprocessing import sequence
max_features = 10000
max_len = 500
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=max_len)
x_test = sequence.pad_sequences(x_test, maxlen=max_len)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
通常一维卷积神经网络架构是由conv1D层和MaxPooling1D层堆叠而成,最后是一个全局池化层或Flatten层,将三维输出转换为二维输出,同时可以添加一个或多个Dense层,用于分类或回归。
一维卷积神经网络可以使用更大的卷积窗口,二维卷积层通常用3*3,对于一维卷积层可以轻松使用大小为7或者9的一维卷积窗口。
在IMDB上训练并评估网络
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.Embedding(max_features, 128, input_length=max_len))
model.add(layers.Conv1D(32, 7, activation='relu'))
model.add(layers.MaxPooling1D(5))
model.add(layers.Conv1D(32, 7, activation='relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(1))
model.summary()
model.compile(optimizer=RMSprop(lr=1e-4),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
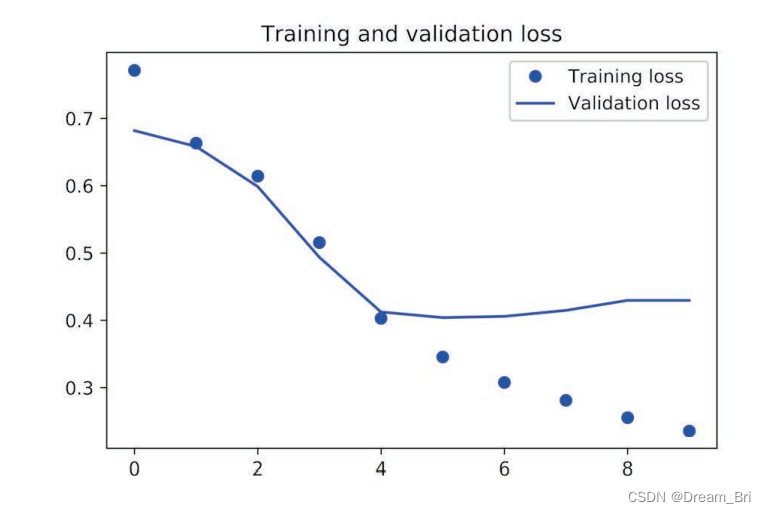
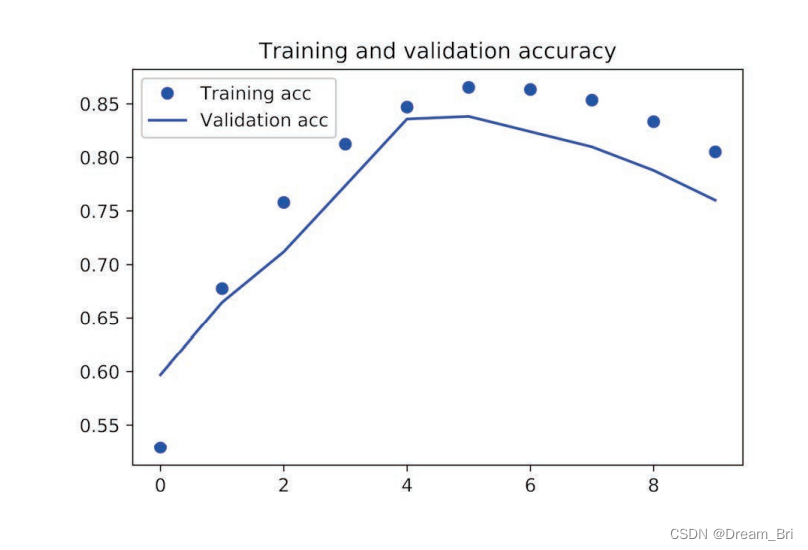
下面是绘制损失和绘制精度的代码
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
















 3065
3065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











