









标注猿的第78篇原创
一个用数据视角看AI世界的标注猿
大家好,我是AI数据标注猿刘吉,一个用数据视角看AI世界的标注猿。
又停更了好长时间,不管是行业内还是AI圈发生了很多大事,虽然没有写文章或者是发视频和大家一起交流,但是还在做标注的业务也在持续关注行业动态。
由于今年自动驾驶相关标注业务价格的持续走低,大模型业务的不稳定,在整体标注业务上投入的精力就少了很多。因为去年12月份公司拿到了中残联首批残疾人大学生实习(见习)基地,更多的精力放到了助残的业务中了,但也没有停止研究“数据+标注”这个事情。
目前已经解决了40多人残疾人朋友的就业,也感谢合作伙伴可以把稳定适合残疾人做的项目放到基地,给更多的残疾人朋友实现自我价值的机会。在这里也呼吁更多有爱心的企业家、老板们如果有适合残疾人朋友的岗位可以放到基地来做,给更多就业的机会。
言归正传,最近看到一条新闻,5月24日在第七届数字中国建设峰会主论坛上国家数据局刘烈宏局长发布了承担数据标注基地建设任务的城市名单。名单共有7个城市,分别为四川省成都市,辽宁省沈阳市,安徽省合肥市,湖南省长沙市,海南省海口市,河北省保定市,山西省大同市。

所以今天就从以下几个方面聊聊这个事儿:
-
国家主导数据标注基地的必要性浅析
-
落地国家级的数据标注基地难点浅析
-
我们从中是否可以嗅到机遇?
一.国家主导数据标注基地的必要性浅析
在讨论国家主导数据标注基地的必要性在哪之前,我们先提几个问题?并逐个尝试去寻找答案。
-
为什么国家要主导数据标注基地的建设?
-
为什么又选择在今年去做这个事情,而不是在数据标注行业发展最快的前几年来做呢?
-
数据标注行业作为一个服务行业真正的价值在哪里?
-
国家主导数据标注基地的必要性在哪?
带着上面的几个问题,重新梳理一下行业的基本逻辑和发展脉络。
1.为什么国家要主导数据标注基地的建设?
最开始看到这条新闻的时候,其实挺诧异的,为什么要把数据标注基地建设作为一个建设任务分派到几个城市呢?作为服务产业,市场也相对成熟了,有必要么?
细细想来,还真的有必要!
-
作为国家战略发展的人工智能产业发展没有预期的好,泡沫远大真实应用。
-
数字经济中最重要的数据流没有完全打通。
-
现有的数据标注及数据服务流程发展没有符合预期,无法承担起数字经济数据加工的重要环节。
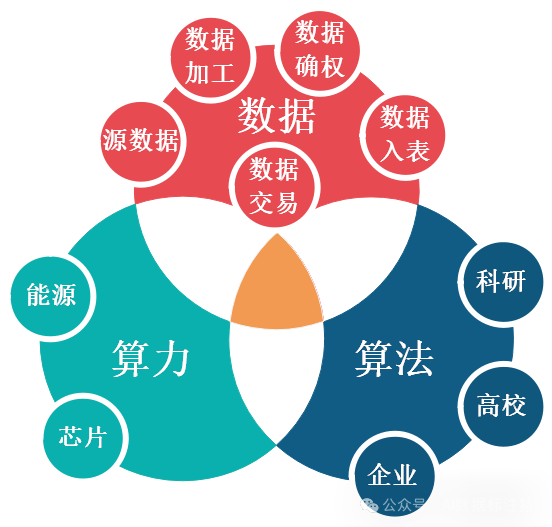
根据上面图来看算力的发展必然是需要国家主导,能源、芯片都无法商业主导,而对于全局来说算法也只能算是应用层,只要做监管就可以了,把算法交给市场来做就好了。
而对于源数据国家才是最大的拥有者,源数据直接交易呢,即不合规价值又低。国家把数据确权、入表、交易基本流程和相关规定都捋顺了,回头一看没有啥可以交易的有用数据。这还怎么完玩?
国内人工智能经过几年的发展,GPT没出来之前也是被吹上了天,结果没几个能打的。标注作为算法研发最重要的环节之一,也被玩成了纯人力的活了。重人力也没毛病,最起码的合规、安全要保证吧。最后发现现有的体系这个最后的底线也不能完全保证。
最可悲的事情或许是在去年今年都有国内的人工智能公司在花高价钱在行业内寻找了解ChatGPT标注方法的人或供应商,到头来在算法眼里最看不起的标注,成为了制约人工智能发展最大的瓶颈之一。
也可以理解,毕竟前几年的国内人工智能更多的是面向投资人开发的,既然可以花10块钱哄的投资人开开心心,为什么要投100元真真正正的把数据标注做好呢?况且投100元也未必看到结果。剩下来的钱做什么不好呢?
不管是从人工智能的发展还是从数字经济的角度来说,如果把这一步交给市场去做,从结果监管,目前来看很难达到预期。并且从源数据到可以确权的数据、可以交易的数据,中间最重要的环节加工如果不做好,后面都没法有效的进行。
与其如此,或许只能国家出手了。
2.为什么又选择在今年去做这个事情,而不是在数据标注行业发展最快的前几年来做呢?
既然国家做这件事儿,为什么选择今年呢?行业整体发展都放缓、需求不稳定,每家披露出来的放到数据上的费用看似很多,到最后实际使用好像也就那么回事吧。
为什么不选择在前几年呢?标注行业发展正旺盛的时候呢?
前几年什么最火、需求量最大,一定是CV相关的。而如今是AIGC,大模型、多模态的需求为主体。前几年国内的人工智能还是以场景化需求为主,无法进行通用。而AIGC打破了这壁垒,打破的不仅仅是算法的壁垒,也打破了数据价值的壁垒。
数据价值不再局限在场景化需求,不在只是定制化需求。数据价值会被继续放大,同时还能解决数据脱敏等问题。
当然这里面还有一直比较关心的数据安全等问题。但是数据安全都是老生常谈的问题,最核心的问题我认为还是数据价值被释放了。
3.数据标注行业作为一个服务行业真正的价值在哪里?
排除现有的标注行业模式不考虑,这里面思考一个问题,数据标注的结果是通用的么?数据标注结果是服务于特定算法的?还是服务于业务场景的?这两个所呈现的价值结果可是完全不同的。
CV的阶段很明显标注是服务于算法的,而到了AIGC的阶段,标注更多的服务于业务。只有跨越个性化的算法需求,才能发挥出数据更大的价值。
这个阶段把数据比作数据石油才能更准确。数据通过数据标注生产的“精炼数据”才更具有价值。
就好比石油可以提炼汽油,提炼出来的汽油产品不会特定一辆车或者一款车,但是不同的车加相同的油,跑出来的效果和作用又大不相同。
而这个事情如果想做,前提就是”数据+标注“的结合,商业化公司目前阶段很难做件事,重投入有风险,自身的商业数据更多的是应用到自身业务上。无法抽身来做这个事情。
这两年AIGC的发展,拉齐了算法。把”数据+标注“推到台前来了,如何使用数据、如何标注数据都成为了核心壁垒,也成了人工智能发展的一大阻碍。
很多公司的算法和标注业务的负责人,或许依然没有意识到这个问题,所谓的标注业务负责人更多的职责依然是传统标注所做的工作,上传下达,监督供应商完成工作,找到更便宜的供应商而已。
这个思路已经远远不够了,只是穿新鞋走老路,依然走不出新的突破。如果不把”数据+标注“提到和算法在统一层面上去思考,或许结果还是和之前一样的。
二.落地国家级的数据标注基地难点浅析
从目前公布的承担建设数据标注的任务名单中的城市,很巧妙的避开了现在已有市场上,数据标注行业发展比较成熟的城市,比如山西太原。有意避开的?还是只是巧合呢?
数据标注作为数据加工的一个重要环节,最终的展现形式一定是服务,而作为一个服务环节,对于国家级的数据标注基地的价值,则是要产生合规、合法、安全、可控的数据。那么国家级的数据标注基地重点是服务?还是科研呢?
如何进行数据标注基地功能的定位?
作为一个数据流程服务中的关键一环,这个基地是否仅仅是给政策导向引导市场开展业务呢?一定不仅仅是这样,如果仅仅是出政策,那应该选择市场相对更成熟的地区。而不是现有的地区。
选择目前地区的逻辑,更像是在布局而非商业服务为主。
那么就会分成两部分,一部分是政府数据加工,一部分是商业化服务。
一部分政府数据加工,很多政府数据会涉密,但是数据是最全的同时也是最大的市场,更多的可以尝试现有的数据进行脱敏脱密做成可用的数据集。比如政务数据、交通大数据等等。
二部分商业化数据服务、数据流程服务。数据确权、数据入表、数据交易的前提是数据合法合规、安全等。对数据加工环节的监管是对数据合法合规、安全最有效的保障。
不管是这样,数据价值释放是必然要做的事情,合规合法、安全、可控是底线。
三.我们从中是否可以嗅到机遇?
最大的机遇是什么?谁会成为数据标注行业的御林军?谁又会成为御林军冲锋陷阵的小弟?
至少在沈阳已经出现了大厂的身影,速度真的是快啊!
如果这个基地做好至少要有几个方面,看看哪几个方面有机会成为御林军?国家要做的也不仅仅是数据标注这一个事儿而已,一定要有别于现有的数据标注体系,发挥出数据的最大价值,而不是为了发挥数据标注价值。
所以“数据+标注”,才是挖掘数据价值的根本需求,如何把真正的数据石油资源转化成真正的数据产品从而发挥出数字经济的最大作用才是根本。
而从算法、工具到人员都会进行一次大洗牌,后面再单独写一篇文章专门讨论这块。面向数字经济的数据标注真的来了,你准备好了么?
以上就是关于国家级数据标注基地的讨论,欢迎大家批评指导,一起讨论。


















 1913
1913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











