






你好,我是郭震(zhenguo)
今天强化学习第10篇:强化学习Q-learning求解迷宫问题 代码实现
1 创建地图
创建迷宫地图
import numpy as np
# 创建迷宫地图
exit_coord = [3, 3]
row_n, col_n = 4, 4
maze = np.zeros((row_n, col_n))
maze[exit_coord] = 12 定义动作
定义动作集合
# 定义动作集合
action_n = 4
actions = [0, 1, 2, 3] # 上、下、左、右3 算法参数
定义参数
# 定义参数
alpha = 0.1 # 学习率
gamma = 0.9 # 折扣因子
epsilon = 0.1 # ε-greedy策略的ε值4 初始化Q表
初始化Q表
# 初始化Q表
Q = np.zeros((row_n * col_n, action_n))5 算法迭代
进行Q-learning算法迭代更新,包括步骤:
选择动作
执行动作,更新状态
更新Q值
# 进行Q-learning算法迭代更新
for episode in range(1000):
# 初始化起始位置
state = (0, 0)
while state != exit_coord: # 终止条件:到达终点位置
# 选择动作
if np.random.uniform() < epsilon:
action = np.random.choice(actions) # ε-greedy策略,以一定概率随机选择动作
else:
action = np.argmax(Q[state]) # 选择Q值最大的动作
# 执行动作,更新状态
next_state = state
if action == 0 and state[0] > 0: # 上
next_state = (state[0] - 1, state[1])
elif action == 1 and state[0] < 3: # 下
next_state = (state[0] + 1, state[1])
elif action == 2 and state[1] > 0: # 左
next_state = (state[0], state[1] - 1)
elif action == 3 and state[1] < 3: # 右
next_state = (state[0], state[1] + 1)
# 获取即时奖励
reward = maze[next_state]
# 更新Q值
state_id = state[0] * state[1] + state[1]
Q[state_id][action] = (1 - alpha) * Q[state_id][action] + alpha * (reward + gamma * np.max(Q[next_state]))
print(Q)
# 更新状态
state = next_state迭代完成,得到Q表:
# 输出最终的Q表
print("最终的Q表:")
print(Q)中间迭代,Q值快照(部分截图):
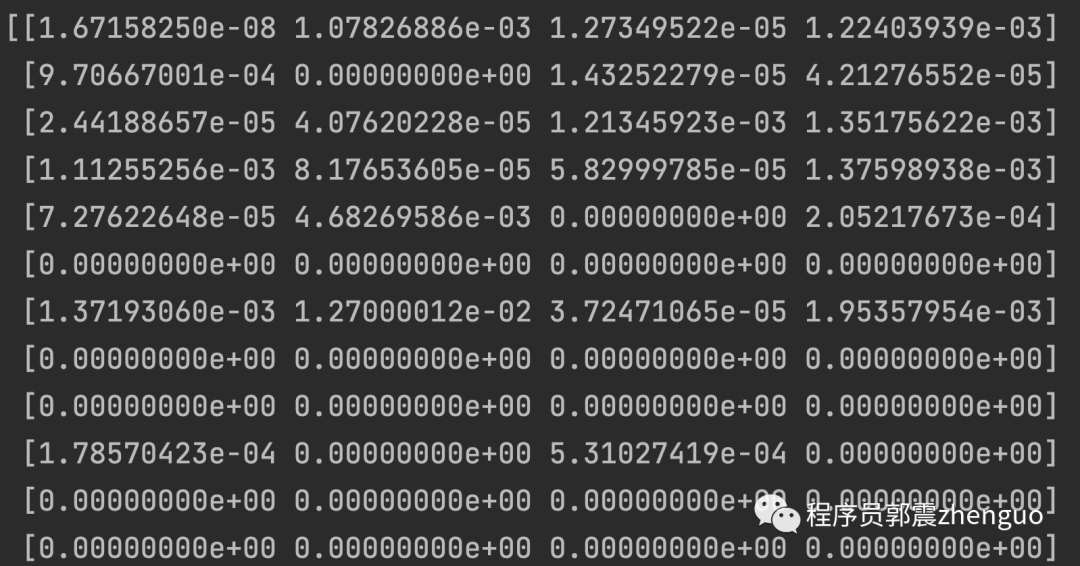
以上,Q-learning算法,代码实现。代码已在本地跑通,欢迎尝试。















 2215
2215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









