






你好,我是郭震
当下就业市场,非常火热的一门技术当属:AI大模型开发,对应岗位就业薪资平均每月三四万。
学习大模型开发,绕不开的一个话题:如何在指定时间完成大模型训练。
今天这篇文章分析一波如何高效训练大模型,一种可靠的实践解决方案。
1 大模型训练和GPU
论文 “Scaling Laws for Neural Language Models”解释了 sclaing laws法则,这个法则告诉我们,随着模型参数量的增加、训练数据量的增加,模型的预测精度或表现会逐渐提升,直到达到某种瓶颈。
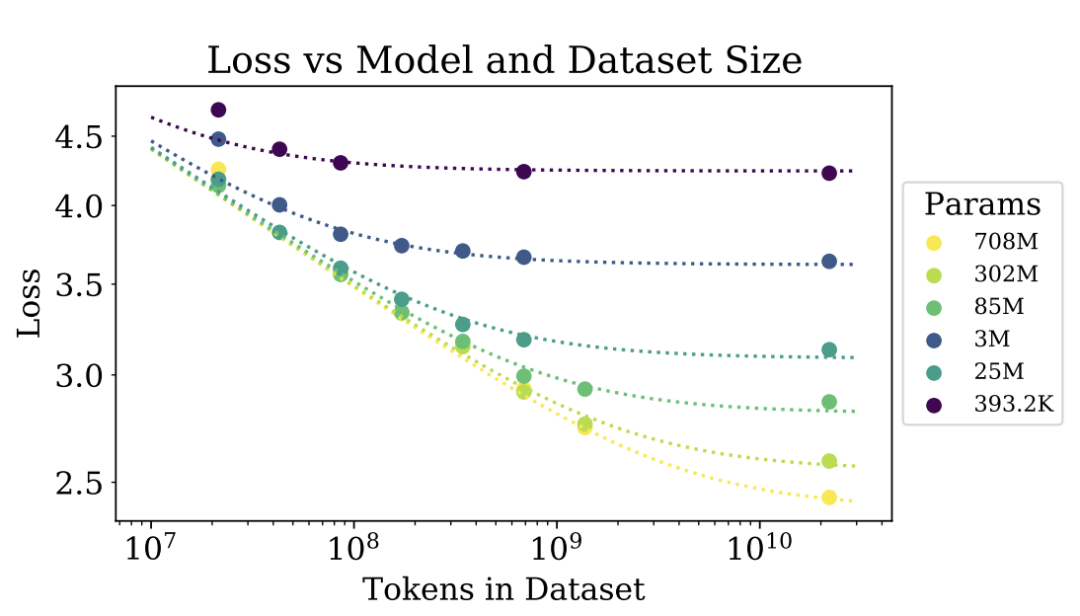
然后,更大规模的模型训练,必然意味着需要更多的计算资源,尤其是GPU等硬件加速,变为必然选项。
如下为高性能单卡A100:

在这里也顺便科普下,GPU显卡存在的价值。
GPU全称:Graphics processing unit,即图形处理单元。
图形本质是二维数组(两个维度相等时又被称为矩阵)。当进行大量的图形处理时,实际就是大量的矩阵间的运算。
从数学角度讲,矩阵运算,都可以并行处理,基于这个数学特性,GPU诞生,实现并行处理矩阵间的并行计算,让图形处理起来更加迅猛和流畅。
在大模型开发中,背后就是这种矩阵运算。为了加速大模型训练,早日让大模型app上线,使用GPU,多卡GPU,GPU集群,成为必然选项。
2 GPU方案之争
A100这种属于大卡,单卡来说,所向披靡,性能那是杠杠的。但是,价格那也是贵的一笔,就拿40G显存的A100,价格约6万8千元:
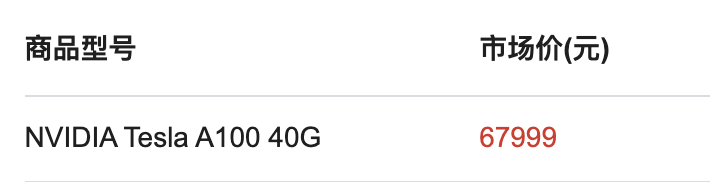
随便买个两三张,就得一二十万,这可是一笔不菲的投入。
有没有更好的解决方案嘞,经过我的调研,发现阿里云多卡GPU+搭配的免费DeepGPU工具核,是另一个很好的解决方案。
简单来说,这个方案做到了花小钱,办大事。
无论对于企业,还是个人开发者,只要想开发专属个人大模型的,阿里云多卡GPU+DeepGPU解决方案真香
多卡GPU,字面意思也能看出来,就是将多张GPU显卡组合起来,同时为我们干活。
DeepGPU,又名神行工具包。它是GPU计算服务增强能力的免费工具集,里面有各种好用的工具包。其中包括:业务快速部署工具、GPU资源拆分工具、AI训练和推理计算优化工具以及针对热门AI模型的专门加速工具等。
我重点研究了DeepGPU里有的1个模块,DeepGPU-LLm。DeepGPU-LLm是一个大模型推理的加速引擎,能加速训练多种大模型,如通义千问Qwen,ChatGLM,Llama等:
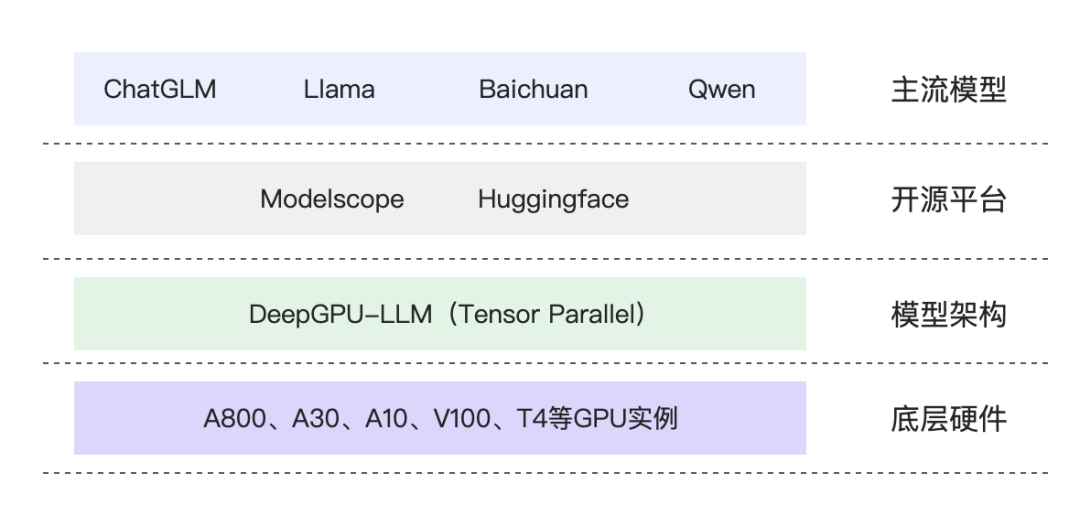
常规多卡GPU搭配,经常会有其中多个GPU显卡被闲置,利用率低,妥妥造成资源和金钱浪费,造成1+1 < 2。但,阿里云多卡GPU,显著提升显卡利用率,真正发挥多卡功效。
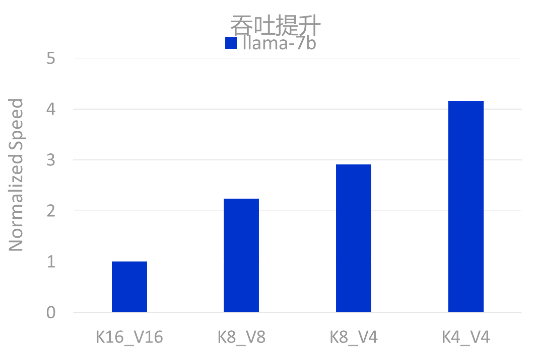
就拿微调Llama-7b来说,K4_V4搭配显著提速4倍,这是什么概念?普通多卡方案训练4个月,阿里云多卡GPU只需1个月:
3 方案性价比分析
两三张A100,一二十万。
而在阿里云多卡GPU+DeepGPU加持下,可以以一个远低于此的成本,便能微调并部署一个专属企业或个人的大模型了。
所以,你不必再去购买实体大卡A100,完全可以按需使用阿里云多卡DeepGPU方案。
计费主要两类:包月包年,按量购买。现在很多款型都有很大的优惠折扣,很多直接五折,四折。比如 gn5 规格族(P100-16G):新客专享,限新购,限1个实例,购买时长1~11个月 5折,购买时长 1~2年 4折:
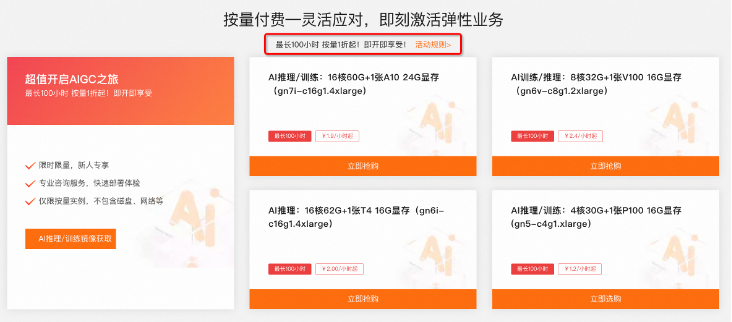
想要微调并部署一个专属企业或个人大模型的,阿里云多卡DeepGPU方案一定是更好的选择,成本可能只需A100成本的5%,甚至更少。
这就是我的调研与方案分析总结,与各位老铁分享。最后希望老铁们点赞,转发支持一下。
想申请GPU显卡的老铁,还有更多隐藏优惠,点击下方阅读原文,填写表单领取。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









