









目前已经有很多面部和唇形同步的数字人项目了,但大多只支持头像和上半身,前几天介绍的Hallo2音频驱动图像生成视频小伙伴们都非常关心,后台也有留言问有没有支持全身视频生成的方法
今天给大家介绍的是由东京大学和 CyberAgent AI Lab 共同研发的项目TANGO,它能根据目标语音音频生成同步全身手势的视频。只需提供一段肢体动作视频和目标语音音频,TANGO就能将两者合成制作出高保真度、动作同步的视频。



相关链接
项目地址:https://pantomatrix.github.io/TANGO/
使用地址:huggingface.co/spaces/H-Liu1997/TANGO
代码地址:https://github.com/CyberAgentAILab/TANGO
论文介绍


TANGO 是一个框架,旨在使用基于运动图的检索方法生成同步语音身体姿势视频。它首先利用隐式分层音频运动嵌入空间检索与目标语音音频匹配的大多数参考视频剪辑。然后,它采用基于扩散的插值网络来生成剩余的过渡帧并平滑剪辑边界处的不连续性。
方法
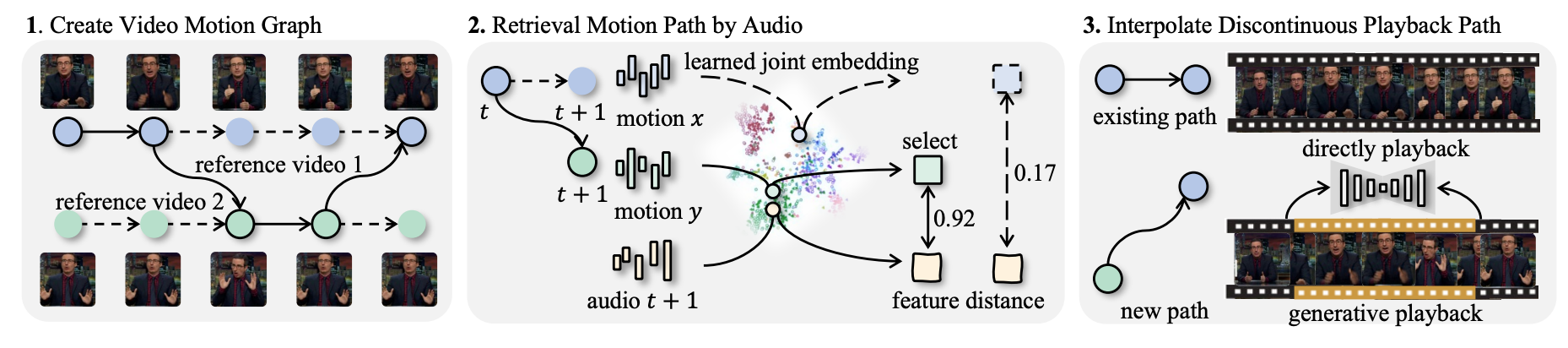
TANGO 的系统管道。 TANGO 通过三个步骤生成手势视频。首先,它创建一个有向运动图,将视频帧表示为节点,将有效过渡表示为边缘。每个采样路径(粗体)决定所选的播放顺序。其次,音频调节手势检索模块旨在最小化跨模态特征距离,以找到手势与目标音频最匹配的路径。最后,当原始参考视频中不存在过渡边缘时,基于扩散的插值模型会生成外观一致的连接帧。
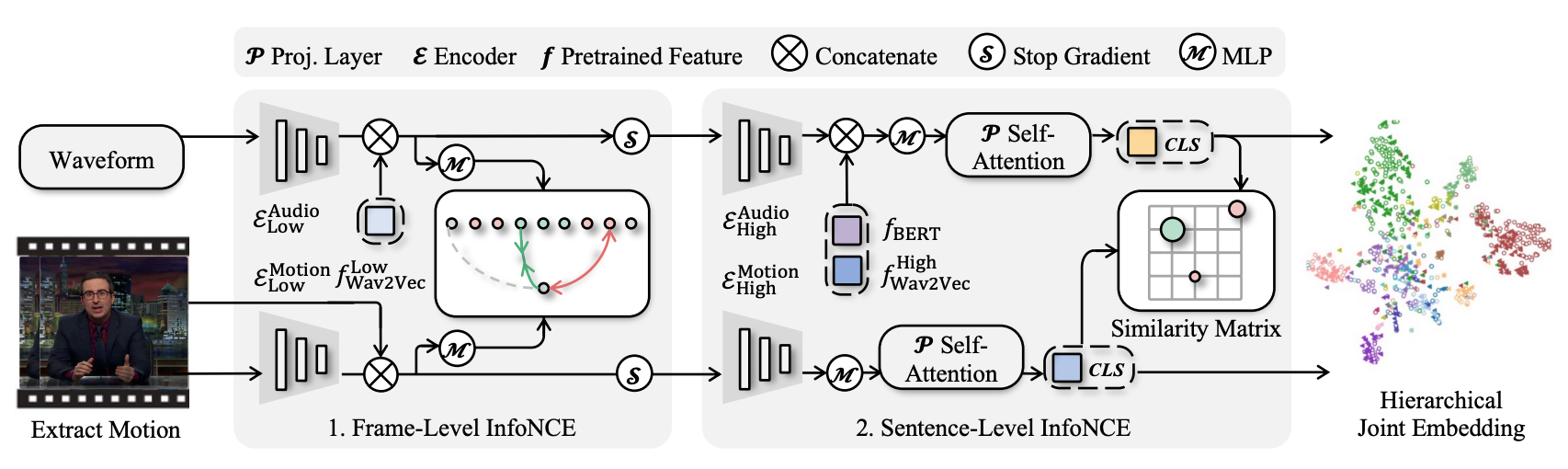
AuMoCLIP。 AuMoCLIP 是一种训练分层联合嵌入的管道。音频波形和提取的 3D 运动被编码在学习的嵌入空间中,其中成对的音频和运动比非成对的样本距离更近。它采用双塔编码器架构;每个编码器分为低级和高级子编码器。此外,它还包括预训练的 Wav2Vec2 和 BERT 功能以使其工作。嵌入分别使用逐帧和逐片段对比损失进行训练,以进行局部和全局跨模态对齐。我们设计了逐帧损失,即在近时间窗口 (i ± t) 内的帧为正,而远距离帧 (i − kt, i − t) 和 (i + t, i + kt) 为负。
效果

过渡帧生成比较。从上到下,我们展示了不同方法中同一帧的四个快照。我们的方法在手部区域显示较少的伪影,并与 GT 帧保持外观一致性。AnimateAnyone 可以恢复手部,但失去了外观一致性。基于流的方法 FiLM 和 VFIFormer 无法估计复杂运动的流,导致手部消失。姿势感知神经渲染显示更好的手部结果,但仍然受到模糊等伪影的影响。


结论
TANGO是一个用于生成高保真视频的框架,其中身体姿势与目标语音音频一致。TANGO 在 Show-Oliver 和 YouTube 视频数据集上进行了评估,以证明其能够制作逼真的视频,优于最先进的基于生成和检索的方法。此外,据我们所知,TANGO 是第一部在音频和运动模态上展示 CLIP 类对比学习的作品,它是第一个开源运动图和音频驱动的视频生成管道。未来,我们的目标是将手势视频图扩展到一般的人体运动视频,例如舞蹈、运动等。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











