









由新加坡国立大学、上海交通大学、北京邮电大学、字节跳动联合提出 新图像编辑框架PhotoDoodle,可以从少数几个例子中学习艺术图像编辑,可直接将装饰元素叠加到照片上来促进照片涂鸦,涂鸦后的效果十分逼真。

相关链接
-
论文:https://arxiv.org/pdf/2502.14397
-
代码:https://github.com/showlab/PhotoDoodle
-
ComfyUI:https://github.com/smthemex/ComfyUI_PhotoDoodle
-
Huggingface:https://huggingface.co/spaces/ameerazam08/PhotoDoodle-Image-Edit-GPU
论文介绍

PhotoDoodle:从少数几个例子中学习艺术图像编辑
PhotoDoodle是一种新颖的图像编辑框架,旨在通过让艺术家将装饰元素叠加到照片上来促进照片涂鸦。照片涂鸦具有挑战性,因为插入的元素必须与背景无缝集成,需要逼真的混合、透视对齐和上下文连贯性。此外,必须保留背景而不失真,并且必须从有限的训练数据中有效捕捉艺术家的独特风格。以前的方法主要侧重于全局风格转移或区域修复,无法满足这些要求。
PhotoDoodle 采用两阶段训练策略。首先使用大规模数据训练通用图像编辑模型 OmniEditor。随后使用 EditLoRA 对该模型进行微调,使用艺术家策划的小型前后图像对数据集来捕捉不同的编辑风格和技巧。为了增强生成结果的一致性,引入了位置编码重用机制。此外还发布了包含六种高质量风格的 PhotoDoodle 数据集。大量实验证明了提出的方法在定制图像编辑方面的先进性能和稳健性,为艺术创作开辟了新的可能性。
方法
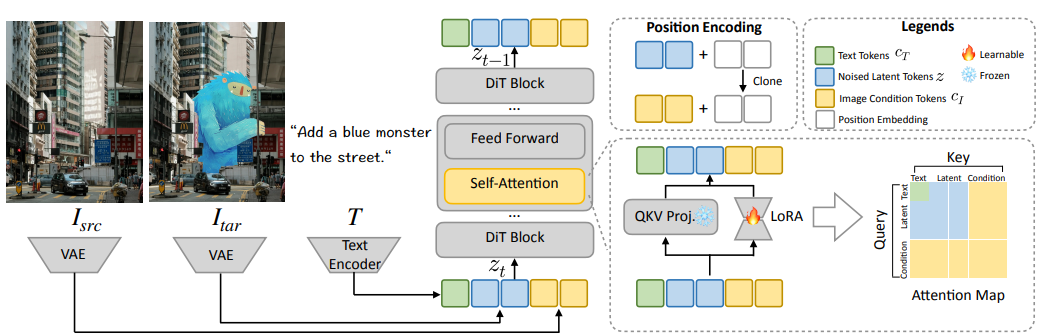
photodoodle 架构和训练方案。 ominiEditor 和 EditLora 都遵循 lora 训练方案。使用高等级 lora 在大型数据集上对 OmniEditor 进行预训练,以实现通用编辑和文本跟踪功能,并使用低等级 lora 在一小组成对的风格化图像上对 EditLoRA 进行微调,以捕捉个别艺术家的特定风格和策略,实现高效定制。将源图像编码为条件标记并将其与噪声潜在标记连接起来,通过 MMAttention 控制生成结果。
结果

PhotoDoodle 生成的结果。PhotoDoodle 可以模仿艺术家创作照片涂鸦的方式和风格,实现指令驱动的高质量图像编辑。

与基线相比,PhotoDoodle 表现出卓越的指令遵循性、图像一致性和编辑有效性。
结论
PhotoDoodle是一个基于扩散的艺术图像编辑框架,可以从最少的配对示例中学习独特的艺术风格。通过将 OmniEditor 的大规模预训练与高效的 EditLoRA 微调相结合,PhotoDoodle 能够实现精确的装饰生成,同时通过位置编码克隆保持背景完整性。关键创新包括无噪声条件范式和仅需要 50 个训练对的参数高效风格自适应,大大降低了计算障碍。论文还贡献了一个包含六种艺术风格和 300 多个精选样本的新数据集,为可重复的研究建立了基准。大量实验表明,在风格复制和背景和谐方面表现出色,在通用和定制编辑场景中均优于现有方法。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











