









阿里联合浙大提出3DV-TON,可生成高保真度和时间一致的视频试穿结果,3DV-TON是一种基于几何和纹理 3D 引导的新型扩散框架。 可处理各种类型的服装和身体姿势,同时准确还原服装细节并保持一致的纹理运动。
通过利用 SMPL 作为参数化人体几何结构,并使用单幅图像重建的 3D 人体作为可动画化的纹理 3D 引导,提供特定帧的外观条件,3DV-TON 缓解了现有方法过度关注外观保真度而导致的结果不一致这一关键限制。该框架能够在不同的姿势和视角下学习几何上合理的人体,同时保持服装纹理运动的时间一致性。

3DV-TON 生成的试穿视频。该方法可以处理各种类型的服装和身体姿势,同时准确还原服装细节并保持一致的纹理运动。
视频试穿效果对比

同一个人+不同的衣服

不同的人+不同的衣服

相关链接
-
论文:https://arxiv.org/pdf/2504.17414
-
主页:https://2y7c3.github.io/3DV-TON
-
代码:(Coming soon...)
论文介绍

视频试穿将视频中的服装替换为目标服装。现有方法在处理复杂的服装图案和多样的身体姿势时难以生成高质量且时间一致的结果。论文提出了3DV-TON,这是一个基于扩散的新型框架,用于生成高保真度和时间一致的视频试穿结果。提出的方法采用生成的可动画的纹理 3D 网格作为明确的帧级指导,从而缓解模型在运动连贯性扩展时过分关注外观保真度的问题。这是通过在整个视频序列中直接参考一致的服装纹理运动来实现的。所提出的方法具有用于生成动态 3D 指导的自适应流程:
-
选择初始 2D 图像试穿的关键帧,
-
重建和制作与原始视频姿势同步的纹理 3D 网格的动画。
然后论文介绍了一种矩形蒙版策略,该策略成功地减轻了动态人体和服装运动过程中服装信息泄露造成的伪影传播。为了推进视频试穿研究,推出了 HR-VVT,这是一个高分辨率基准数据集,包含 130 个涵盖多种服装类型和场景的视频。定量和定性结果均表明,论文提出的方法性能优于现有方法。
概述
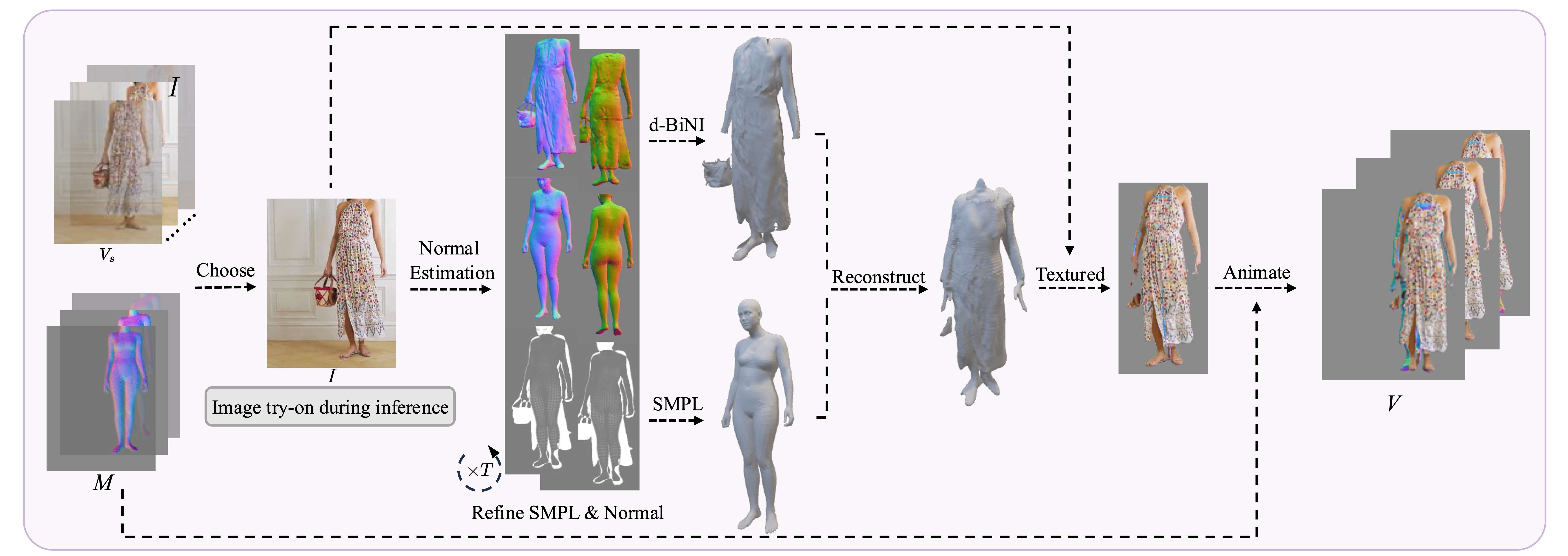
3DV-TON 的整体流程。 给定一段视频,首先使用 3D 引导流程自适应地选择帧I,然后重建带纹理的 3D 引导,并使其与原始视频(即 V)对齐,从而进行动画制作。对服装图像C和试穿图像Ct使用引导特征提取器,并使用去噪 UNet 中的自注意力机制进行特征融合。

纹理 3D 引导。根据图像试穿结果构建纹理 3D 引导,并在粘贴纹理后为网格添加动画效果,从而在外观层面提供一致的纹理运动参考。
实验结果




结论
3DV-TON是一种基于几何和纹理 3D 引导的新型扩散框架。通过利用 SMPL 作为参数化人体几何结构,并使用单幅图像重建的 3D 人体作为可动画化的纹理 3D 引导,提供特定帧的外观条件,3DV-TON 缓解了现有方法过度关注外观保真度而导致的结果不一致这一关键限制。该框架能够在不同的姿势和视角下学习几何上合理的人体,同时保持服装纹理运动的时间一致性。对现有数据集以及论文新引入的 HR-VVT 进行的定量和定性评估,证明了其在视频试穿任务中的最佳性能。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











