







1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着人工智能技术的不断发展,深度学习已经成为计算机视觉领域的重要研究方向之一。在图像识别领域,卷积神经网络(Convolutional Neural Networks,CNN)已经取得了显著的成果。然而,传统的卷积神经网络在花卉信息识别方面仍然存在一些挑战,如花卉种类较多、花卉外观差异较大等问题。因此,基于深度学习和改进卷积神经网络的花卉信息识别系统具有重要的研究意义。
首先,花卉是自然界中的重要组成部分,具有丰富的物种和品种。花卉的种类繁多,外观差异大,对于一般人来说,很难准确地识别花卉的种类和特征。而基于深度学习和改进卷积神经网络的花卉信息识别系统可以通过学习大量的花卉图像数据,自动识别花卉的种类和特征,为花卉爱好者、园艺师和植物学家提供准确的花卉信息。
其次,花卉信息识别系统对于花卉市场和花卉产业的发展具有重要的推动作用。随着人们对于生活品质的要求不断提高,花卉市场呈现出快速增长的趋势。然而,花卉市场的发展受到花卉信息的限制,人们往往需要依靠专业人士或者花卉书籍来识别花卉的种类和特征。基于深度学习和改进卷积神经网络的花卉信息识别系统可以提供快速、准确的花卉信息,帮助消费者更好地了解和选择花卉,促进花卉市场的发展。
此外,基于深度学习和改进卷积神经网络的花卉信息识别系统还可以为生态环境保护和植物研究提供支持。在生态环境保护方面,花卉是生态系统中的重要组成部分,通过识别花卉的种类和特征,可以更好地了解和保护生态环境。在植物研究方面,花卉是植物学研究的重要对象,通过识别花卉的种类和特征,可以更好地研究植物的生长、繁殖和适应环境的能力。
综上所述,基于深度学习和改进卷积神经网络的花卉信息识别系统具有重要的研究背景和意义。通过该系统,可以实现花卉种类和特征的自动识别,为花卉爱好者、园艺师和植物学家提供准确的花卉信息;促进花卉市场的发展,提高消费者对花卉的了解和选择能力;支持生态环境保护和植物研究,促进生态环境的保护和植物学研究的进展。因此,基于深度学习和改进卷积神经网络的花卉信息识别系统具有重要的研究价值和应用前景。
2.图片演示



3.视频演示
基于深度学习和改进卷积神经网络的花卉信息识别系统_哔哩哔哩_bilibili
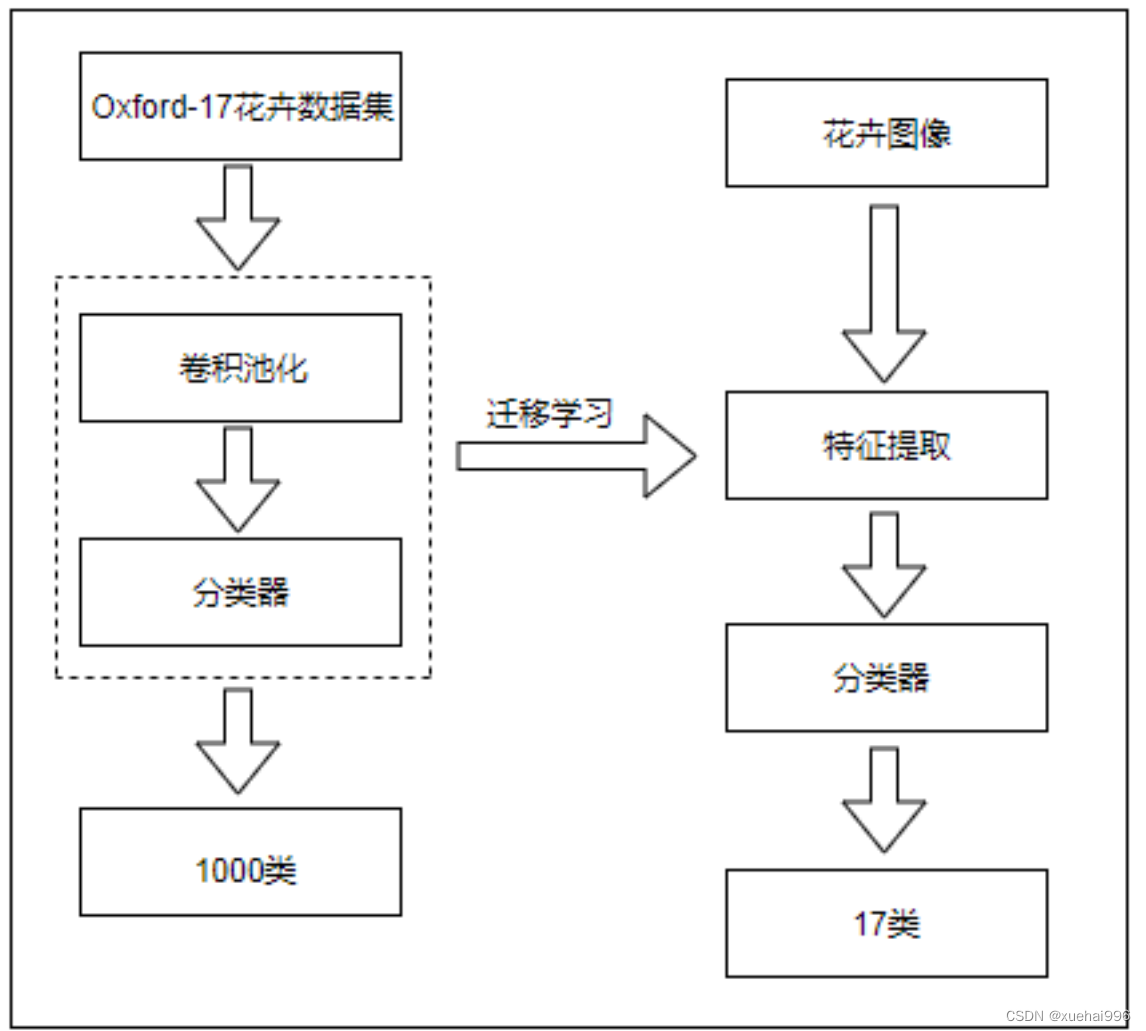
4.算法流程图
花卉种类识别功能实现的主要途径是利用计算机对样本进行分类。通过对样本的精准分类达到得出图像识别结果的目的。经典的花卉识别设计如图所示,这几个过程相互关联而又有明显区别。
卷积神经网络
卷积神经网络是受到生物学启发的深度学习经典的多层前馈神经网络结构。是一种在图像分类中广泛使用的机器学习算法。
CNN 的灵感来自我们人类实际看到并识别物体的方式。这是基于一种方法,即我们眼睛中的神经元细胞只接收到整个对象的一小部分,而这些小块(称为接受场)被组合在一起以形成整个对象。
与其他的人工视觉算法不一样的是CNN可以处理特定任务的多个阶段的不变特征。卷积神经网络使用的并不像经典的人工神经网络那样的全连接层,而是通过采取局部连接和权值共享的方法,来使训练的参数量减少,降低模型的训练复杂度。
CNN在图像分类和其他识别任务方面已经使传统技术的识别效果得到显著的改善。由于在过去的几年中卷积网络的快速发展,对象分类和目标检测能力取得喜人的成绩。
典型的CNN含有多个卷积层和池化层,并具有全连接层以产生任务的最终结果。在图像分类中,最后一层的每个单元表示分类概率。
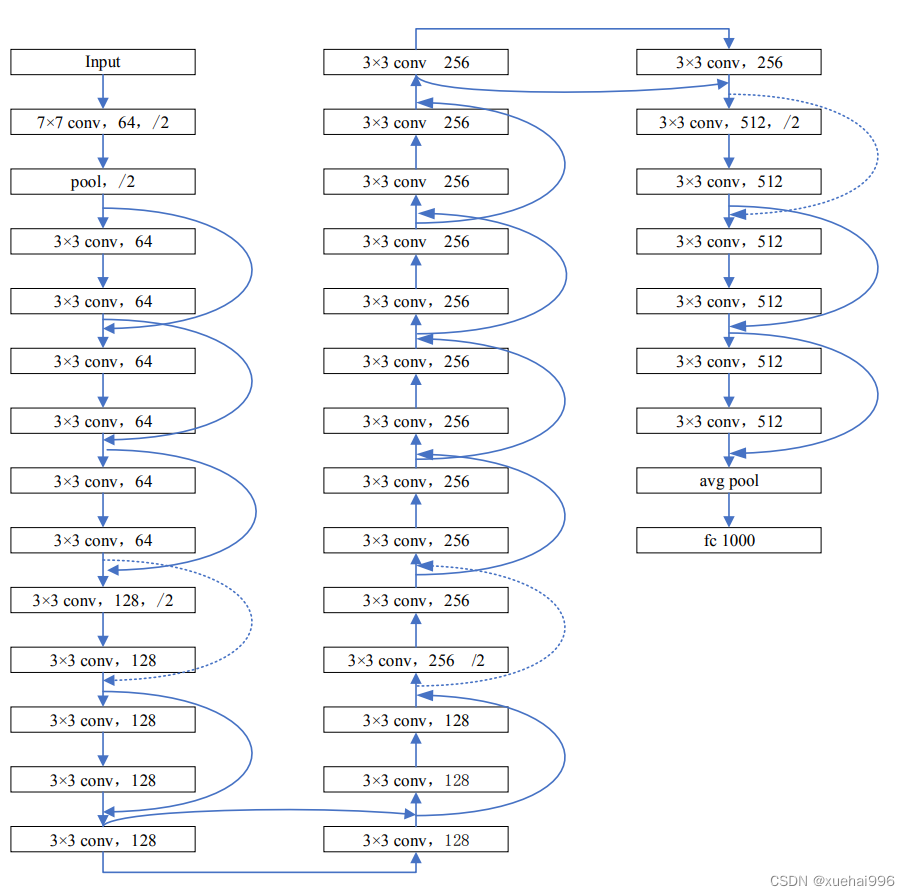
下图为一个经典卷积神经网络结构。
残差网络(ResNet)
ResNet是功能最强大的深度神经网络之一,在ILSVRC 2015分类挑战中获得了惊人的性能结果。ResNet在其他识别任务上取得了出色的泛化性能,并在ILSVRC和COCO 2015竞赛中获得了ImageNet检测,ImageNet定位,COCO检测和COCO分割方面的第一名。
ResNet 体系结构有很多变体,即相同的概念,但层数不同。有 ResNet-18,ResNet-34,ResNet-50 ,ResNet-101,ResNet-110,ResNet-152,ResNet-164,ResNet-1202。带有两个或多个数字的 ResNet名称仅表示具有一定数量的神经网络层的ResNet体系结构。
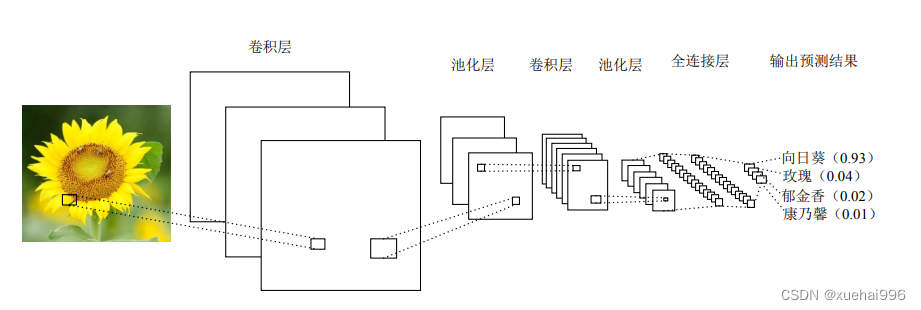
深度残差网络提出了捷径连接(shorcut connections,SR) ,利用跳过连接或快捷方式跳过某些层来实现此目的,在保证网络之间数据畅通的前提下,避免了由于梯度损失引起的拟合不足的问题,加深了网络层次,有效地改善了模型的表示性。典型的ResNet模型是通过包含非线性(ReLU)和介于两者之间的批量归一化的双层或三层跳过实现的。
残差学习
残差在数理统计领域中是指实际观察值与估计值之间的差。如果回归模型正确的话,通常也可以将残差看作误差的观测值。
在神经网络中,假设H(x)代表输入样本x后多层神经网络的相应输出。根据神经网络理论,H(x)可以适合任何函数。假设输入输出维度相同。
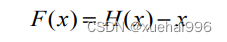
如图所示:
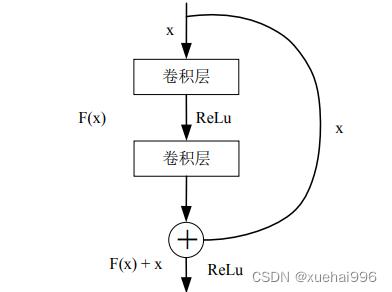
ResNet是一种由残差块组成的架构类型。它是一堆规则层的堆叠,例如卷积和批处理,其输入不仅流经权重层,还流过捷径连接。最后,将两条路径相加。Resnet使我们有机会添加更多的网络层,建议的标准层数为18、34、50、101 和152。
细粒度图像分类(Fine-Grained Categorization),是近年来深度学习里较热门的研究课题。它参考粗粒度的类别划分,在其基础上追求更加细致的子类划分,它类别精度更加细致,类间差异更加细微,往往只能以微小的局部差异才能进行类别区分[4。细粒度图像分类还受到一些因素的困扰,例如光照和背景干扰等。因此,它是一项非常具有挑战性的研究任务。近年来,随着深度学习的发展,专家们开始尝试将各种深度学习的相关技术应用于细粒度图像分类。由于从深度卷积神经网络中提取的特征拥有强大的描述力,更能代表代表物体的本质,他们将深度卷积神经网络应用于细粒度图像分类,再结合一些新型特征算法,这将会极大提高细粒度图像分类的准确度。
花卉图像分类属于细粒度图像分类,背景复杂,花卉部分是整个分类任务中重点关注区域,卷积神经网络对于花卉部分颜色、形状等重要因素的学习来实现花卉图像分类识别。可是现实情况中,有的图像花卉部分占据很大部分,有的图像花卉部分在整幅图像中只占据很小一部分,不相关部分背景的复杂干扰,还有茎和叶的干扰,这些都极大的增加了花卉图像分类任务的难度。为了解决这个困扰,可在卷积神经网络中添加注意力机制,抑制复杂背景的干扰。
添加注意力机制的花卉图像分类识别模型结构
由前一章可知,在众多卷积神经网络模型中,通过实验证明VGG-16对于花卉图像分类识别效果好,所以本节将在VGG-16上添加注意力机制,改善花卉图像背景干扰分类识别的问题。
首先花卉图像分类识别模型基于卷积神经网络,并在该网络上添加Saumya Jetley等人提出的用于图像分类的端到端可训练注意力模块,模型结构如图所示。
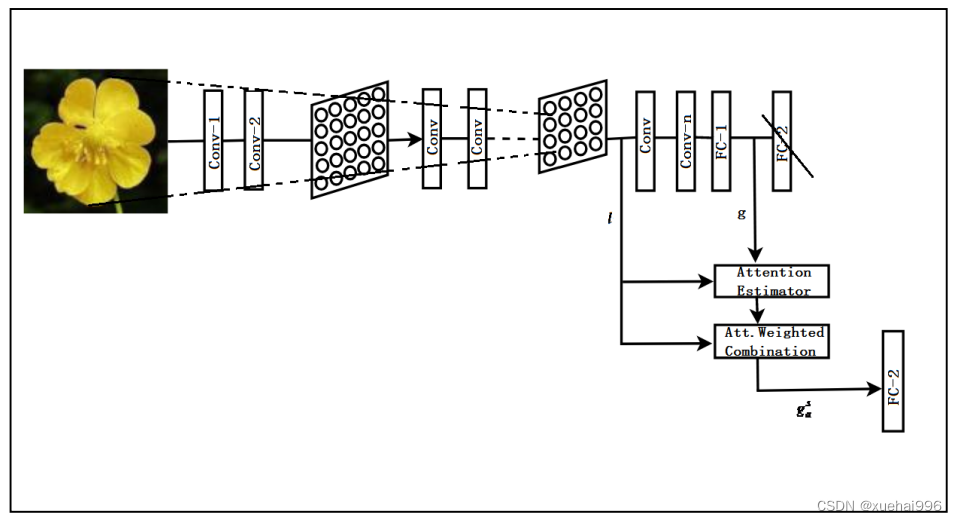
添加注意力机制的花卉图像分类识别结果
由于Oxford-17 flower花卉数据集样本不多,花卉之间的细小差异难以体现,所以选用数据集Oxford-102 flower进行注意力机制在细粒度图像分类的性能实验。实验采用pycharm平台,以Tensorflow为框架,语言为python3.7,硬件平台采用配置为至强E5八核处理器3.6GHZ和16GB内存的工作站。
基于残差网络并添加注意力机制的花卉图像分类识别具体模型结构如图所示。
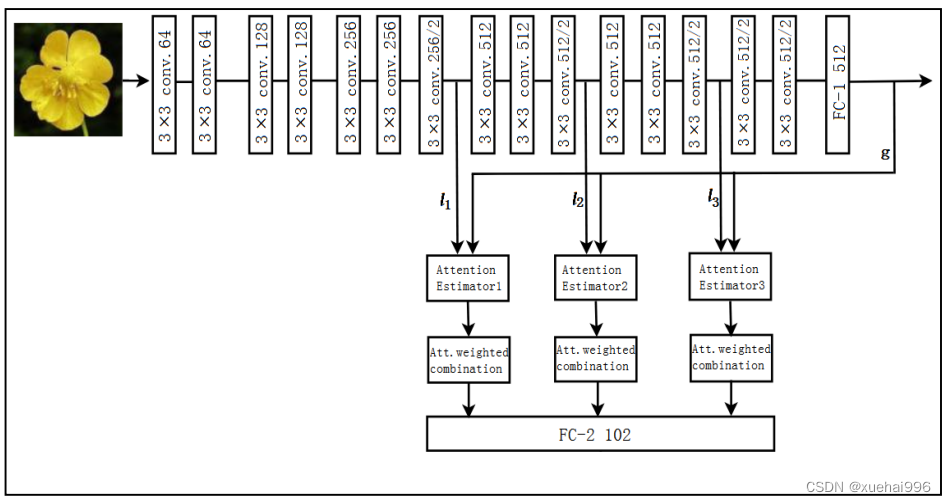
实验中,在残差网络的基础上添加注意力机制,选用调取部分中间卷积层Conv3_3、Conv4_3和Conv5_3的局部特征和全连接层FC-1的全局特征进行特征融合,构建注意力特征作为最后的分类特征,并与全连接层FC-2进行级联,实现对花卉图像的分类识别。
基于VGG-16网络并引用注意力机制得到的注意力模型效果如图所示。
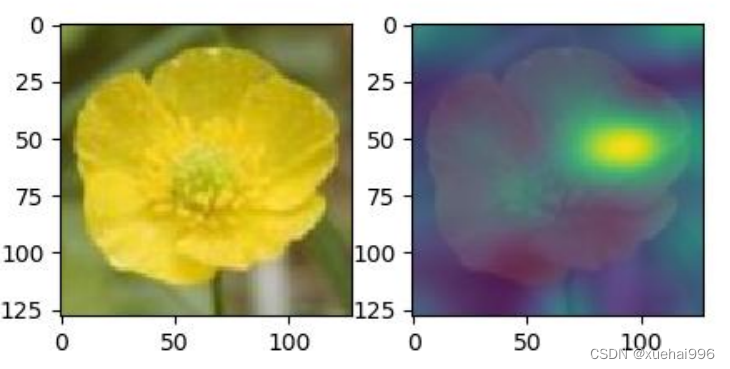
从上图中可以发现注意力机制抑制背景等无用相关信息,选择花卉作为感兴趣点,能提取更多有用的信息,有助于实现花卉的准确分类。
5.核心代码讲解
5.1 fit.py
封装为类的代码如下:
class ModelTrainer:
def __init__(self, model, loss_fn, optimizer, train_dl, test_dl, exp_lr_scheduler):
self.model = model
self.loss_fn = loss_fn
self.optimizer = optimizer
self.train_dl = train_dl
self.test_dl = test_dl
self.exp_lr_scheduler = exp_lr_scheduler
def fit(self, epoch):
correct = 0
total = 0
running_loss = 0
self.model.train()
for x, y in tqdm(self.train_dl):
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = self.model(x)
loss = self.loss_fn(y_pred, y)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred, dim=1)
correct += (y_pred == y).sum().item()
total += y.size(0)
running_loss += loss.item()
self.exp_lr_scheduler.step()
epoch_loss = running_loss / len(self.train_dl.dataset)
epoch_acc = correct / total
test_correct = 0
test_total = 0
test_running_loss = 0
self.model.eval()
with torch.no_grad():
for x, y in tqdm(self.test_dl):
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = self.model(x)
loss = self.loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct += (y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_loss = test_running_loss / len(self.test_dl.dataset)
epoch_test_acc = test_correct / test_total
print('epoch: ', epoch,
'loss: ', round(epoch_loss, 3),
'accuracy:', round(epoch_acc, 3),
'test_loss: ', round(epoch_test_loss, 3),
'test_accuracy:', round(epoch_test_acc, 3)
)
return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
该程序文件名为fit.py,主要功能是定义了一个fit函数,用于训练模型并返回损失和准确率的变化。
fit函数的输入参数包括epoch(当前训练的轮数)、model(模型)、loss_fn(损失函数)、optim(优化器)、train_dl(训练数据集)、test_dl(测试数据集)和exp_lr_scheduler(学习率调整器)。
在fit函数中,首先初始化了一些变量,包括正确预测的数量correct、总样本数量total和累计损失running_loss。
然后,将模型设置为训练模式,通过迭代训练数据集train_dl,将输入数据x传入模型得到预测结果y_pred,计算预测结果与真实标签之间的损失loss,将优化器的梯度清零,进行反向传播和参数更新。同时,使用torch.no_grad()上下文管理器计算训练集的准确率和累计损失。
接下来,使用学习率调整器exp_lr_scheduler调整学习率,并计算训练集的平均损失epoch_loss和准确率epoch_acc。
然后,初始化测试集的正确预测数量test_correct、总样本数量test_total和累计损失test_running_loss。
将模型设置为评估模式,通过迭代测试数据集test_dl,将输入数据x传入模型得到预测结果y_pred,计算预测结果与真实标签之间的损失loss,并计算测试集的准确率和累计损失。
最后,打印出当前轮数epoch、训练集的平均损失epoch_loss和准确率epoch_acc,以及测试集的平均损失epoch_test_loss和准确率epoch_test_acc。
最后,返回训练集的平均损失、准确率和测试集的平均损失、准确率。
5.2 test.py
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = nn.Sequential(RestNetBasicBlock(64, 64, 1),
RestNetBasicBlock(64, 64, 1))
self.ca = ChannelAttention(64)
self.sa = SpatialAttention()
self.layer2 = nn.Sequential(RestNetDownBlock(64, 128, [2,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2601
2601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









