






 本文介绍了一种基于深度学习的药品文本识别处方分类系统,旨在提高医疗工作的效率和准确性。系统利用CRNN模型进行文本识别,通过深度学习技术自动识别和分类处方,减少人工错误。此外,系统还能提供药品管理和监控、支持药品研究以及改善患者医疗服务。文章详细阐述了系统的技术背景、模型结构、核心代码和训练过程,展示了其在医疗领域的广泛应用潜力。
本文介绍了一种基于深度学习的药品文本识别处方分类系统,旨在提高医疗工作的效率和准确性。系统利用CRNN模型进行文本识别,通过深度学习技术自动识别和分类处方,减少人工错误。此外,系统还能提供药品管理和监控、支持药品研究以及改善患者医疗服务。文章详细阐述了系统的技术背景、模型结构、核心代码和训练过程,展示了其在医疗领域的广泛应用潜力。
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着医疗技术的不断发展和人们对健康的关注度提高,药品的使用和管理变得越来越重要。药品处方是医生为患者开具的一种医疗指导,它包含了药品的名称、剂量、用法等重要信息。然而,由于处方的数量庞大,传统的人工处理方式已经无法满足日益增长的需求。因此,开发一种基于深度学习的药品文本识别处方分类系统具有重要的现实意义。
首先,药品文本识别处方分类系统可以提高医疗工作的效率和准确性。传统的人工处理方式需要医生或药师手动阅读和理解处方,然后进行分类和处理。这种方式不仅耗时耗力,而且容易出现错误。而基于深度学习的药品文本识别处方分类系统可以自动识别和分类处方,大大减轻了医生和药师的工作负担,提高了工作效率和准确性。
其次,药品文本识别处方分类系统可以提供更好的药品管理和监控。药品的使用和管理是医疗工作中的重要环节,尤其是在大型医院或药店中。通过识别和分类处方,系统可以自动记录和管理药品的使用情况,包括药品的种类、剂量、用法等信息。这不仅可以帮助医生和药师更好地掌握药品的使用情况,还可以提供数据支持,帮助医疗机构进行药品管理和监控,防止药品滥用和浪费。
此外,药品文本识别处方分类系统还可以为药品研究和临床实践提供有价值的数据支持。通过对大量处方的识别和分类,系统可以收集和分析药品的使用情况和效果,为药品研究和临床实践提供有价值的数据支持。这有助于发现药品的潜在作用、副作用和相互作用,优化药品的使用和推广,提高医疗质量和效果。
最后,药品文本识别处方分类系统还可以为患者提供更好的医疗服务和健康管理。通过识别和分类处方,系统可以为患者提供个性化的用药建议和健康管理方案。患者可以通过系统了解药品的使用方法和注意事项,及时咨询医生和药师,提高用药的安全性和效果。此外,系统还可以提供健康管理的建议和指导,帮助患者更好地管理自己的健康,预防疾病的发生和发展。
综上所述,基于深度学习的药品文本识别处方分类系统具有重要的现实意义。它可以提高医疗工作的效率和准确性,提供更好的药品管理和监控,为药品研究和临床实践提供有价值的数据支持,以及为患者提供更好的医疗服务和健康管理。因此,开展相关研究对于推动医疗技术的发展和提升医疗服务的质量具有重要的意义。
2.图片演示



3.视频演示
基于深度学习的药品文本识别处方分类系统_哔哩哔哩_bilibili
4.传统文本检测技术与深度学习文本检测技术
(1)传统文本检测技术
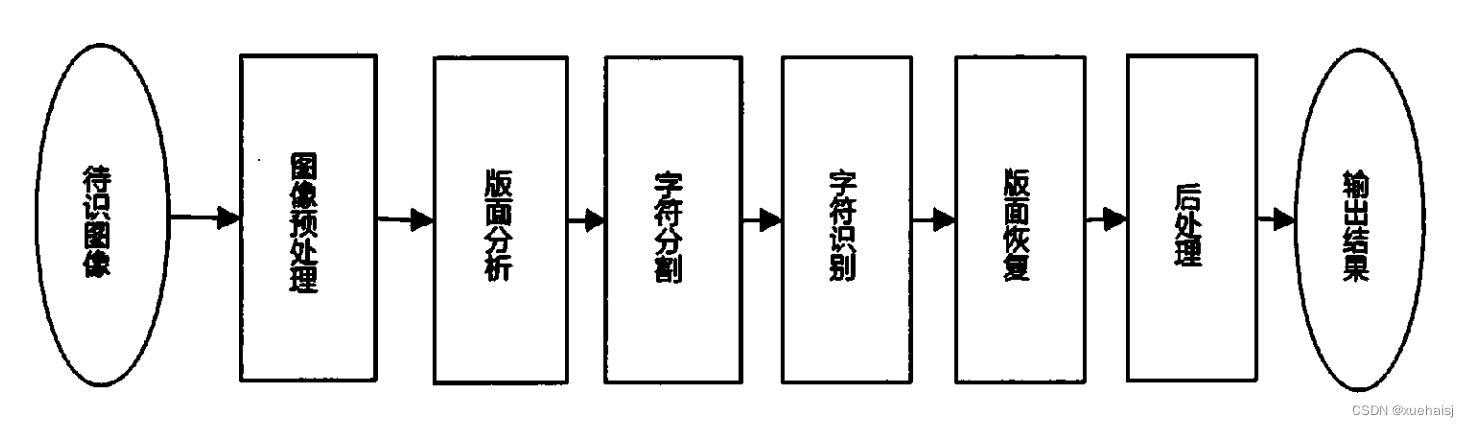
一般传统的文本检测系统从输入图像到输出最终识别结果通常会经历如下步骤:首先要对图像进行预处理(如彩色图像灰度化、二值化处理、图像变化角度检测、矫正处理等),再经过版面分析(直线检测、倾斜检测)、字符分割、字符识别、版面恢复和后处理等步骤。
(2)基于深度学习的文本检测技术
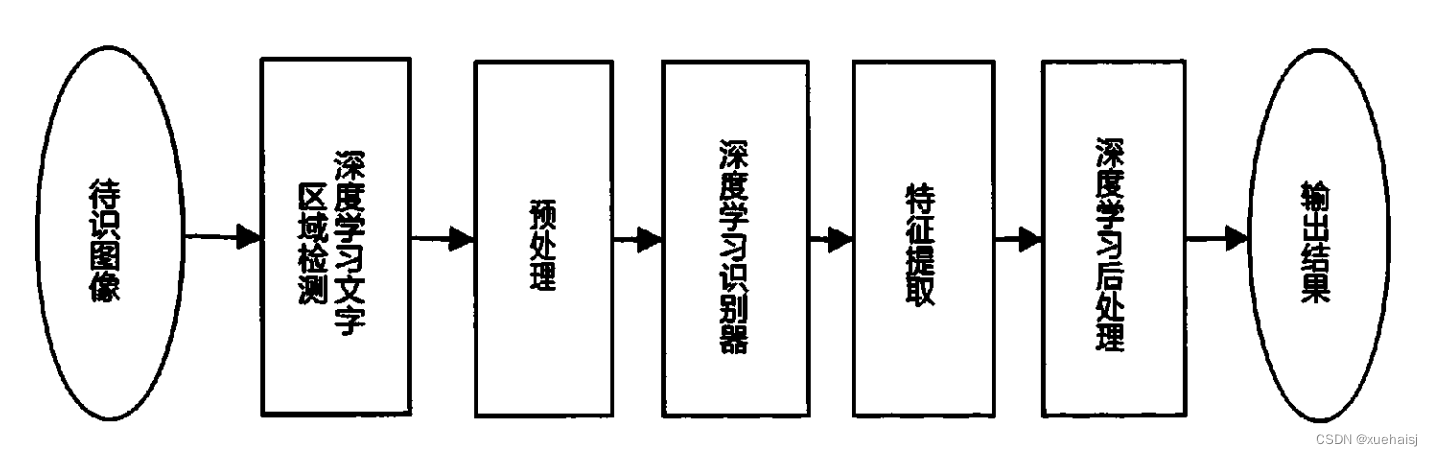
随着深度学习的大热,传统的文本检测识别框架已不复昔日的辉煌,在现在的研究领域,研究者一般更青睐于使用卷积神经网络做文本检测技术实验[3],一者不必再费劲心力去设计字符特征,二者基于深度学习的文本检测系统识别率很高。
5.核心代码讲解
5.1 config.py
class CRNNConfig:
def __init__(self):
self.train_infofile = 'data_set/infofile_train_10w.txt'
self.train_infofile_fullimg = ''
self.val_infofile = 'data_set/infofile_test.txt'
self.alphabet = keys.alphabet
self.alphabet_v2 = keys.alphabet_v2
self.workers = 4
self.batchSize = 50
self.imgH = 32
self.imgW = 280
self.nc = 1
self.nclass = len(self.alphabet)+1
self.nh = 256
self.niter = 100
self.lr = 0.0003
self.beta1 = 0.5
self.cuda = True
self.ngpu = 1
self.pretrained_model = ''
self.saved_model_dir = 'crnn_models'
self.saved_model_prefix = 'CRNN-'
self.use_log = False
self.remove_blank = False
self.experiment = None
self.displayInterval = 500
self.n_test_disp = 10
self.valInterval = 500
self.saveInterval = 500
self.adam = False
self.adadelta = False
self.keep_ratio = False
self.random_sample = True
这样封装为一个类,可以方便地通过实例化该类来获取配置信息。
这个程序文件名为config.py,主要用于配置一些参数和变量。具体内容如下:
- 导入了一个名为keys的模块。
- 定义了训练数据集的信息文件路径train_infofile,训练数据集的完整图像路径train_infofile_fullimg,验证数据集的信息文件路径val_infofile。
- 定义了字母表alphabet和alphabet_v2,用于表示字符集。
- 定义了workers,表示用于数据加载的线程数。
- 定义了batchSize,表示每个批次的样本数量。
- 定义了图像的高度imgH和宽度imgW。
- 定义了nc,表示图像的通道数。
- 定义了nclass,表示字符类别的数量,其中包括了一个特殊的类别。
- 定义了nh,表示LSTM隐藏层的大小。
- 定义了niter,表示训练的迭代次数。
- 定义了lr,表示学习率。
- 定义了beta1,表示Adam优化器的beta1参数。
- 定义了cuda,表示是否使用GPU进行训练。
- 定义了ngpu,表示使用的GPU数量。
- 定义了pretrained_model,表示预训练模型的路径。
- 定义了saved_model_dir,表示保存模型的目录。
- 定义了saved_model_prefix,表示保存模型的前缀。
- 定义了use_log,表示是否使用日志。
- 定义了remove_blank,表示是否移除空白字符。
- 定义了experiment,表示实验名称。
- 定义了displayInterval,表示每隔多少次迭代显示一次训练信息。
- 定义了n_test_disp,表示每次显示多少个测试样本的结果。
- 定义了valInterval,表示每隔多少次迭代进行一次验证。
- 定义了saveInterval,表示每隔多少次迭代保存一次模型。
- 定义了adam,表示是否使用Adam优化器。
- 定义了adadelta,表示是否使用Adadelta优化器。
- 定义了keep_ratio,表示是否保持图像宽高比。
- 定义了random_sample,表示是否随机采样数据。
这些参数和变量用于配置训练过程中的各种设置和选项。
5.2 crnn.py
class BidirectionalLSTM(nn.Module):
def __init__(self, nIn, nHidden, nOut):
super(BidirectionalLSTM, self).__init__()
self.rnn = nn.LSTM(nIn, nHidden, bidirectional=True)
self.embedding = nn.Linear(nHidden * 2, nOut)
def forward(self, input):
recurrent, _ = self.rnn(input)
T, b, h = recurrent.size()
t_rec = recurrent.view(T * b, h)
output = self.embedding(t_rec) # [T * b, nOut]
output = output.view(T, b, -1)
return output
class CRNN(nn.Module):
def __init__(self, imgH, nc, nclass, nh, leakyRelu=False):
super(CRNN, self).__init__()
assert imgH % 16 == 0, 'imgH has to be a multiple of 16'
# 1x32x128
self.conv1 = nn.Conv2d(nc, 64, 3, 1, 1)
self.relu1 = nn.ReLU(True)
self.pool1 = nn.MaxPool2d(2, 2)
# 64x16x64
self.conv2 = nn.Conv2d(64, 128, 3, 1, 1)
self.relu2 = nn.ReLU(True)
self.pool2 = nn.MaxPool2d(2, 2)
# 128x8x32
self.conv3_1 = nn.Conv2d(128, 256, 3, 1, 1)
self.bn3 = nn.BatchNorm2d(256)
self.relu3_1 = nn.ReLU(True)
self.conv3_2 = nn.Conv2d(256, 256, 3, 1, 1)
self.relu3_2 = nn.ReLU(True)
self.pool3 = nn.MaxPool2d((2, 2), (2, 1), (0, 1))
# 256x4x16
self.conv4_1 = nn.Conv2d(256, 512, 3, 1, 1)
self.bn4 = nn.BatchNorm2d(512)
self.relu4_1 = nn.ReLU(True)
self.conv4_2 = nn.Conv2d(512, 512, 3, 1, 1)
self.relu4_2 = nn.ReLU(True)
self.pool4 = nn.MaxPool2d((2, 2), (2, 1), (0, 1))
# 512x2x16
self.conv5 = nn.Conv2d(512, 512, 2, 1, 0)
self.bn5 = nn.BatchNorm2d(512)
self.relu5 = nn.ReLU(True)
# 512x1x16
self.rnn = nn.Sequential(
BidirectionalLSTM(512, nh, nh),
BidirectionalLSTM(nh, nh, nclass))
def forward(self, input):
# conv features
x = self.pool1(self.relu1(self.conv1(input)))
x = self.pool2(self.relu2(self.conv2(x)))
x = self.pool3(self.relu3_2(self.conv3_2(self.relu3_1(self.bn3(self.conv3_1(x))))))
x = self.pool4(self.relu4_2(self.conv4_2(self.relu4_1(self.bn4(self.conv4_1(x))))))
conv = self.relu5(self.bn5(self.conv5(x)))
b, c, h, w = conv.size()
assert h == 1, "the height of conv must be 1"
conv = conv.squeeze(2)
conv = conv.permute(2, 0, 1) # [w, b, c]
# rnn features
output = self.rnn(conv)
return output
class CRNN_v2(nn.Module):
def __init__(self, imgH, nc, nclass, nh, leakyRelu=False):
super(CRNN_v2, self).__init__()
assert imgH % 16 == 0, 'imgH has to be a multiple of 16'
# 1x32x128
self.conv1_1 = nn.Conv2d(nc, 32, 3, 1, 1)
self.bn1_1 = nn.BatchNorm2d(32)
self.relu1_1 = nn.ReLU(True)
self.conv1_2 = nn.Conv2d(32, 64, 3, 1, 1)
self.bn1_2 = nn.BatchNorm2d(64)
self.relu1_2 = nn.ReLU(True)
self.pool1 = nn.MaxPool2d(2, 2)
# 64x16x64
self.conv2_1 = nn.Conv2d(64, 64, 3, 1, 1)
self.bn2_1 = nn.BatchNorm2d(64)
self.relu2_1 = nn.ReLU(True)
self.conv2_2 = nn.Conv2d(64, 128, 3, 1, 1)
self.bn2_2 = nn.BatchNorm2d(128)
self.relu2_2 = nn.ReLU(True)
self.pool2 = nn.MaxPool2d(2, 2)
# 128x8x32
self.conv3_1 = nn.Conv2d(128, 96, 3, 1, 1)
self.bn3_1 = nn.BatchNorm2d(96)
self.relu3_1 = nn.ReLU(True)
self.conv3_2 = nn.Conv2
该程序文件是一个用于文本识别的CRNN模型的实现。该模型包含了多个子模块,包括BidirectionalLSTM、CRNN、CRNN_v2、basic_res_block和CRNN_res。
BidirectionalLSTM是一个双向LSTM模块,用于将输入序列进行双向LSTM处理,并将结果进行线性映射得到输出。
CRNN是一个基于卷积神经网络和循环神经网络的文本识别模型。它包含了多个卷积层和池化层,用于提取图像特征,然后将特征输入到双向LSTM中进行序列建模,最后输出识别结果。
CRNN_v2是CRNN的另一个版本,它使用了不同的卷积层和池化层结构,但整体的网络结构和CRNN相似。
basic_res_block是一个基本的残差块,用于构建CRNN_res模型中的残差网络结构。
CRNN_res是一个基于残差网络的文本识别模型。它使用了多个残差块来提取图像特征,并将特征输入到双向LSTM中进行序列建模,最后输出识别结果。
该程序文件中的代码主要定义了各个模块的结构和前向传播方法,但没有具体的训练和测试代码。
5.3 crnn_recognizer.py
class resizeNormalize(object):
def __init__(self, size, interpolation=Image.LANCZOS, is_test=True):
self.size = size
self.interpolation = interpolation
self.toTensor = transforms.ToTensor()
self.is_test = is_test
def __call__(self, img):
w, h = self.size
w0 = img.size[0]
h0 = img.size[1]
if w <= (w0 / h0 * h):
img = img.resize(self.size, self.interpolation)
img = self.toTensor(img)
img.sub_(0.5).div_(0.5)
else:
w_real = int(w0 / h0 * h)
img = img.resize((w_real, h), self.interpolation)
img = self.toTensor(img)
img.sub_(0.5).div_(0.5)
tmp = torch.zeros([img.shape[0], h, w])
start = random.randint(0, w - w_real - 1)
if self.is_test:
start = 0
tmp[:, :, start:start + w_real] = img
img = tmp
return img
class strLabelConverter(object):
def __init__(self, alphabet, ignore_case=False):
self._ignore_case = ignore_case
if self._ignore_case:
alphabet = alphabet.lower()
self.alphabet = alphabet + '_' # for `-1` index
self.dict = {}
for i, char in enumerate(alphabet):
self.dict[char] = i + 1
def encode(self, text):
length = []
result = []
for item in text:
item = item.decode('utf-8', 'strict')
length.append(len(item))
for char in item:
if char not in self.dict.keys():
index = 0
else:
index = self.dict[char]
result.append(index)
text = result
return (torch.IntTensor(text), torch.IntTensor(length))
def decode(self, t, length, raw=False):
if length.numel() == 1:
length = length[0]
assert t.numel() == length, "text with length: {} does not match declared length: {}".format(t.numel(),
length)
if raw:
return ''.join([self.alphabet[i - 1] for i in t])
else:
char_list = []
for i in range(length):
if t[i] != 0 and (not (i > 0 and t[i - 1] == t[i])):
char_list.append(self.alphabet[t[i] - 1])
return ''.join(char_list)
else:
assert t.numel() == length.sum(), "texts with length: {} does not match declared length: {}".format(
t.numel(), length.sum())
texts = []
index = 0
for i in range(length.numel()):
l = length[i]
texts.append(
self.decode(
t[index:index + l], torch.IntTensor([l]), raw=raw))
index += l
return texts
class PytorchOcr():
def __init__(self, model_path):
alphabet_unicode = config.alphabet_v2
self.alphabet = ''.join([chr(uni) for uni in alphabet_unicode])
self.nclass = len(self.alphabet) + 1
self.model = CRNN(config.imgH, 1, self.nclass, 256)
self.cuda = False
if torch.cuda.is_available():
self.cuda = True
self.model.cuda()
self.model.load_state_dict({k.replace('module.', ''): v for k, v in torch.load(model_path).items()})
else:
self.model.load_state_dict(torch.load(model_path, map_location='cpu'))
self.model.eval()
self.converter = strLabelConverter(self.alphabet)
def recognize(self, img):
h,w = img.shape[:2]
if len(img.shape) == 3:
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
image = Image.fromarray(img)
transformer = resizeNormalize((int(w/h*32), 32))
image = transformer(image)
image = image.view(1, *image.size())
image = Variable(image)
if self.cuda:
image = image.cuda()
preds = self.model(image)
_, preds = preds.max(2)
preds = preds.transpose(1, 0).contiguous().view(-1)
preds_size = Variable(torch.IntTensor([preds.size(0)]))
txt = self.converter.decode(preds.data, preds_size.data, raw=False)
return txt
这个程序文件是一个使用CRNN模型进行文字识别的程序。它包含了一个名为crnn_recognizer.py的文件,其中定义了一个名为PytorchOcr的类,该类用于加载训练好的CRNN模型并进行文字识别。
在PytorchOcr类的构造函数中,首先定义了一个包含所有字符的字母表alphabet,然后根据字母表的大小和输入图片的高度,创建了一个CRNN模型。如果可用的话,模型会被加载到GPU上。接下来,定义了一个strLabelConverter类,用于将文字转换为标签。最后,定义了一个recognize方法,用于对输入的图片进行文字识别。
在__main__函数中,首先指定了训练好的模型的路径和要识别的图片的路径。然后,创建了一个PytorchOcr对象,并调用其recognize方法对图片进行文字识别。最后,将识别结果打印出来。
5.4 keys.py
import pickle as pkl
class AlphabetGenerator:
def __init__(self, infofiles):
self.infofiles = infofiles
def generate_alphabet(self):
alphabet_set = set()
for infofile in self.infofiles:
f = open(infofile)
content = f.readlines()
f.close()
for line in content:
if len(line.strip()) > 0:
if len(line.strip().split('\t')) != 2:
print(line)
else:
fname, label = line.strip().split('\t')
for ch in label:
alphabet_set.add(ch)
alphabet_list = sorted(list(alphabet_set))
pkl.dump(alphabet_list, open('alphabet.pkl', 'wb'))
这个程序文件名为keys.py,它的功能是生成一个字母表并保存到文件中。程序的主要步骤如下:
- 导入pickle模块并将其重命名为pkl。
- 注释掉了一段代码,该代码是通过标签生成字母表的步骤。
- 加载之前保存的字母表文件alphabet.pkl。
- 将字母表中的每个字符转换为对应的ASCII码,并存储在列表alphabet中。
- 将alphabet赋值给alphabet_v2。
- 注释掉了一行打印alphabet_v2的代码。
总体来说,这个程序文件的功能是加载之前保存的字母表文件,并将字母表中的每个字符转换为对应的ASCII码。
5.5 mydataset.py
class MyDataset(Dataset):
def __init__(self,info_filename,train=True, transform=data_tf,target_transform=None,remove_blank = False):
super(Dataset, self).__init__()
self.transform = transform
self.target_transform = target_transform
self.info_filename = info_filename
if isinstance(self.info_filename,str):
self.info_filename = [self.info_filename]
self.train = train
self.files = list()
self.labels = list()
for info_name in self.info_filename:
with open(info_name) as f:
content = f.readlines()
for line in content:
if '\t' in line:
if len(line.split('\t'))!=2:
print(line)
fname, label = line.split('\t')
else:
fname,label = line.split('g:')
fname += 'g'
if remove_blank:
label = label.strip()
else:
label = ' '+label.strip()+' '
self.files.append(fname)
self.labels.append(label)
def name(self):
return 'MyDataset'
def __getitem__(self, index):
img = Image.open(self.files[index])
if self.transform is not None:
img = self.transform( img )
img = img.convert('L')
label = self.labels[index]
if self.target_transform is not None:
label = self.target_transform( label )
return (img,label)
def __len__(self):
return len(self.labels)
class MyDatasetPro(Dataset):
def __init__(self, info_filename_txtline=list(), info_filename_fullimg=list(), train=True, txtline_transform=data_tf,
fullimg_transform = data_tf_fullimg, target_transform=None):
super(Dataset, self).__init__()
self.txtline_transform = txtline_transform
self.fullimg_transform = fullimg_transform
self.target_transform = target_transform
self.info_filename_txtline = info_filename_txtline
self.info_filename_fullimg = info_filename_fullimg
if isinstance(self.info_filename_txtline,str):
self.info_filename_txtline = [self.info_filename_txtline]
if isinstance(self.info_filename_fullimg,str):
self.info_filename_fullimg = [self.info_filename_fullimg]
self.train = train
self.files = list()
self.labels = list()
self.locs = list()
for info_name in self.info_filename_txtline:
with open(info_name) as f:
content = f.readlines()
for line in content:
fname,label = line.split('g:')
fname += 'g'
label = label.replace('\r','').replace('\n','')
self.files.append(fname)
self.labels.append(label)
self.txtline_len = len(self.labels)
for info_name in self.info_filename_fullimg:
with open(info_name) as f:
content = f.readlines()
for line in content:
fname,label,left, top, right, bottom = line.strip().split('\t')
self.files.append(fname)
self.labels.append(label)
self.locs.append([int(left),int(top),int(right),int(bottom)])
print(len(self.labels),len(self.files))
def name(self):
return 'MyDatasetPro'
def __getitem__(self, index):
label = self.labels[index]
if self.target_transform is not None:
label = self.target_transform(label)
img = Image.open(self.files[index])
if index>=self.txtline_len:
img = self.fullimg_transform(img,self.locs[index-self.txtline_len])
if index%100 == 0:
img.save('test_imgs/debug-{}-{}.jpg'.format(index,label.strip())) #debug
else:
if self.txtline_transform is not None:
img = self.txtline_transform(img)
img = img.convert('L')
return (img,label)
def __len__(self):
return len(self.labels)
class resizeNormalize(object):
def __init__(self, size, interpolation=Image.LANCZOS,is_test=False):
self.size = size
self.interpolation = interpolation
self.toTensor = transforms.ToTensor()
self.is_test = is_test
def __call__(self, img):
w,h = self.size
w0 = img.size[0]
h0 = img.size[1]
if w<=(w0/h0*h):
img =
该程序文件名为mydataset.py,主要包含了一个名为MyDataset的类和一些辅助函数。该类继承自torch.utils.data.Dataset,用于加载和处理数据集。
程序中还定义了一些数据预处理的函数,如randomColor、randomGaussian、inverse_color等,用于对图像进行颜色抖动、高斯噪声处理和颜色反转等操作。
MyDataset类的构造函数接受一个info_filename参数,该参数指定了数据集的信息文件名。在构造函数中,程序会读取info_filename文件中的内容,并将文件名和标签分别存储在self.files和self.labels列表中。
MyDataset类实现了__getitem__和__len__方法,用于获取数据集中的样本和样本数量。在__getitem__方法中,程序会根据索引index读取对应的图像文件,并应用预处理函数data_tf对图像进行处理。最后,返回处理后的图像和对应的标签。
此外,程序还定义了一个名为resizeNormalize的类,用于将图像调整为指定大小并进行归一化处理。
在程序的最后,通过if name == 'main’判断是否为主程序入口,如果是,则会读取指定路径下的图像文件,并显示前5张图像。
5.6 online_test.py
class CRNNModel:
def __init__(self, model_path):
self.alphabet = keys.alphabet_v2
self.converter = utils.strLabelConverter(self.alphabet.copy())
self.gpu = torch.cuda.is_available()
self.model = crnn.CRNN(config.imgH, 1, len(self.alphabet) + 1, 256)
if self.gpu:
self.model = self.model.cuda()
print('loading pretrained model from %s' % model_path)
if self.gpu:
self.model.load_state_dict(torch.load(model_path))
else:
self.model.load_state_dict(torch.load(model_path, map_location=lambda storage, loc: storage))
def val_model(self, infofile, log_file='0625.log'):
h = open('log/{}'.format(log_file), 'w')
with open(infofile) as f:
content = f.readlines()
num_all = 0
num_correct = 0
for line in content:
if '\t' in line:
fname, label = line.split('\t')
else:
fname, label = line.split('g:')
fname += 'g'
label = label.replace('\r', '').replace('\n', '')
img = cv2.imread(fname)
res = self.val_on_image(img)
res = res.strip()
label = label.strip()
if res == label:
num_correct += 1
else:
print('filename:{}\npred :{}\ntarget:{}'.format(fname, res, label))
h.write('filename:{}\npred :{}\ntarget:{}\n'.format(fname, res, label))
num_all += 1
h.write('ocr_correct: {}/{}/{}\n'.format(num_correct, num_all, num_correct / num_all))
print(num_correct / num_all)
h.close()
return num_correct, num_all
def val_on_image(self, img):
imgH = config.imgH
h, w = img.shape[:2]
imgW = imgH * w // h
transformer = mydataset.resizeNormalize((imgW, imgH), is_test=True)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
image = Image.fromarray(np.uint8(img)).convert('L')
image = transformer(image)
if self.gpu:
image = image.cuda()
image = image.view(1, *image.size())
image = Variable(image)
self.model.eval()
preds = self.model(image)
preds = F.log_softmax(preds, 2)
conf, preds = preds.max(2)
preds = preds.transpose(1, 0).contiguous().view(-1)
preds_size = Variable(torch.IntTensor([preds.size(0)]))
sim_pred = self.converter.decode(preds.data, preds_size.data, raw=False)
return sim_pred
这个程序文件是一个用于在线测试的Python脚本。它使用了PyTorch和CRNN模型来进行图像识别。主要功能是读取一个包含图像文件路径和标签的文本文件,然后对每个图像进行识别,并将识别结果与标签进行比较。如果识别结果与标签相同,则计数器num_correct加1,否则将错误信息写入日志文件。最后,输出正确率和总数。
具体流程如下:
- 导入所需的库和模块。
- 定义了一个用于验证模型的函数val_model,它接受一个包含图像路径和标签的文本文件,一个模型对象,一个布尔值表示是否使用GPU,以及一个日志文件名作为参数。
- 在val_model函数中,打开文本文件并逐行读取内容。
- 对于每一行,根据制表符或空格分割图像路径和标签。
- 读取图像文件并进行预处理。
- 将预处理后的图像输入模型进行识别。
- 对识别结果进行处理,去除空格和换行符。
- 将识别结果与标签进行比较,如果相同则num_correct加1,否则将错误信息写入日志文件。
- 统计总数num_all。
- 将正确率和总数写入日志文件,并输出正确率。
- 在主函数中,根据命令行参数选择要测试的数据集文件,并调用val_model函数进行测试。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于深度学习的药品文本识别处方分类系统。它使用了CRNN模型进行文字识别,并提供了训练、测试和在线识别的功能。整体构架包括了数据预处理、模型定义、训练、测试和在线识别等模块。
下表是每个文件的功能概述:
| 文件名 | 功能概述 |
|---|---|
| config.py | 配置文件,定义了训练和模型相关的参数和变量 |
| crnn.py | CRNN模型的定义和实现 |
| crnn_recognizer.py | 使用CRNN模型进行文字识别 |
| keys.py | 生成字母表并保存到文件中 |
| mydataset.py | 加载和处理数据集的类,包括数据预处理和数据集的读取 |
| online_test.py | 在线测试脚本,用于对图像进行识别并与标签进行比较 |
| recognizer.py | 文字识别器,用于加载训练好的模型并进行文字识别 |
| split_train_test.py | 将数据集划分为训练集和测试集 |
| train.py | 训练脚本,用于训练CRNN模型 |
| train_warp_ctc.py | 使用CTC损失函数训练CRNN模型 |
| train_warp_ctc_v2.py | 使用CTC损失函数训练CRNN模型的另一个版本 |
| trans.py | 数据转换脚本,用于将图像转换为特定格式 |
| trans_utils.py | 数据转换的辅助函数 |
| ui.py | 用户界面脚本,用于提供交互式界面 |
| utils.py | 工具函数,包括图像处理、文件操作等 |
以上是对每个文件功能的简要概述,具体的实现细节可能还包括其他辅助函数和类。
7.文本识别算法分析
场景文字识别的传统方法非常多,经历了多年的发展与历代学者的研究探索,目前主流的场景文字识别方法是两种:
一种是基于CTC6的方法。CTC是一种可以避开输入与输出手动对齐的一种方式,十分适合用于语音识别或者OCR应用。尤其是CTC和神经网络的结合,典型的代表为CRNN,CRNN是一种卷积循环神经网络,它的提出使得基于图像相关的序列识别问题得到有效的解决,后经常被研究者用来做场景文字识别。
另一种是Sequence2Sequence算法[7],两者的区别主要在解码阶段。
基于CTC 的算法是将编码产生的序列接入CTC进行解码;基于Sequence2Sequence 的方法会得到统一的语义向量,该向量是由编码器(Encoder)将输入序列编码而成,解码工作是由解码器(Decoder)完成。在解码过程中,需要不停地将前一个时刻的输出作为后一个时刻的输入,循环往复的做解码工作,当输出停止符时,即可停止。
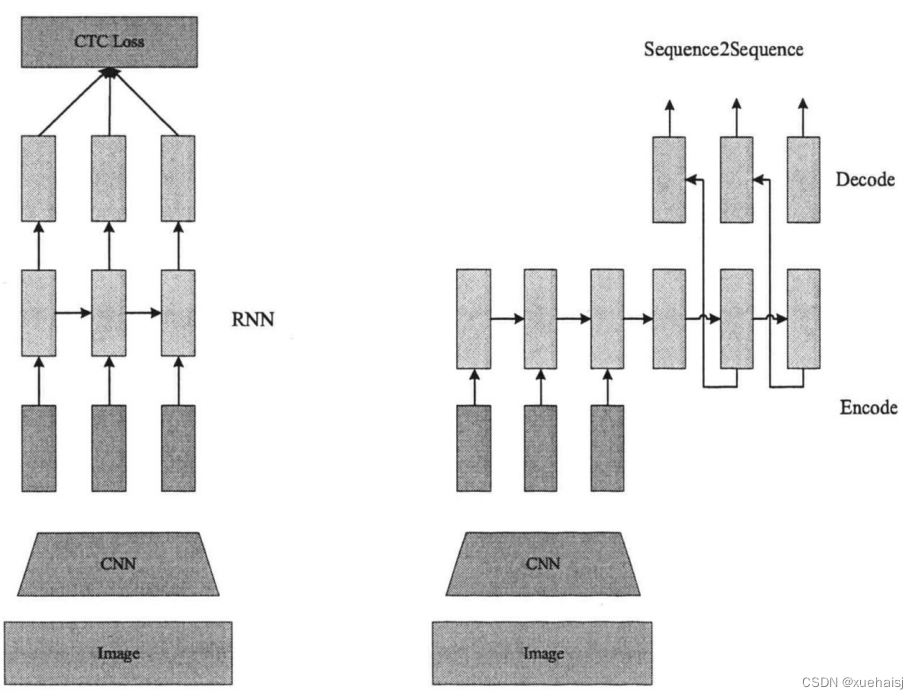
以上两个算法在规则文本上都有很不错的效果,本文采用的是CRNN+CTC的文本识别算法模型。
8.CRNN+CTC
CRNN模型结构
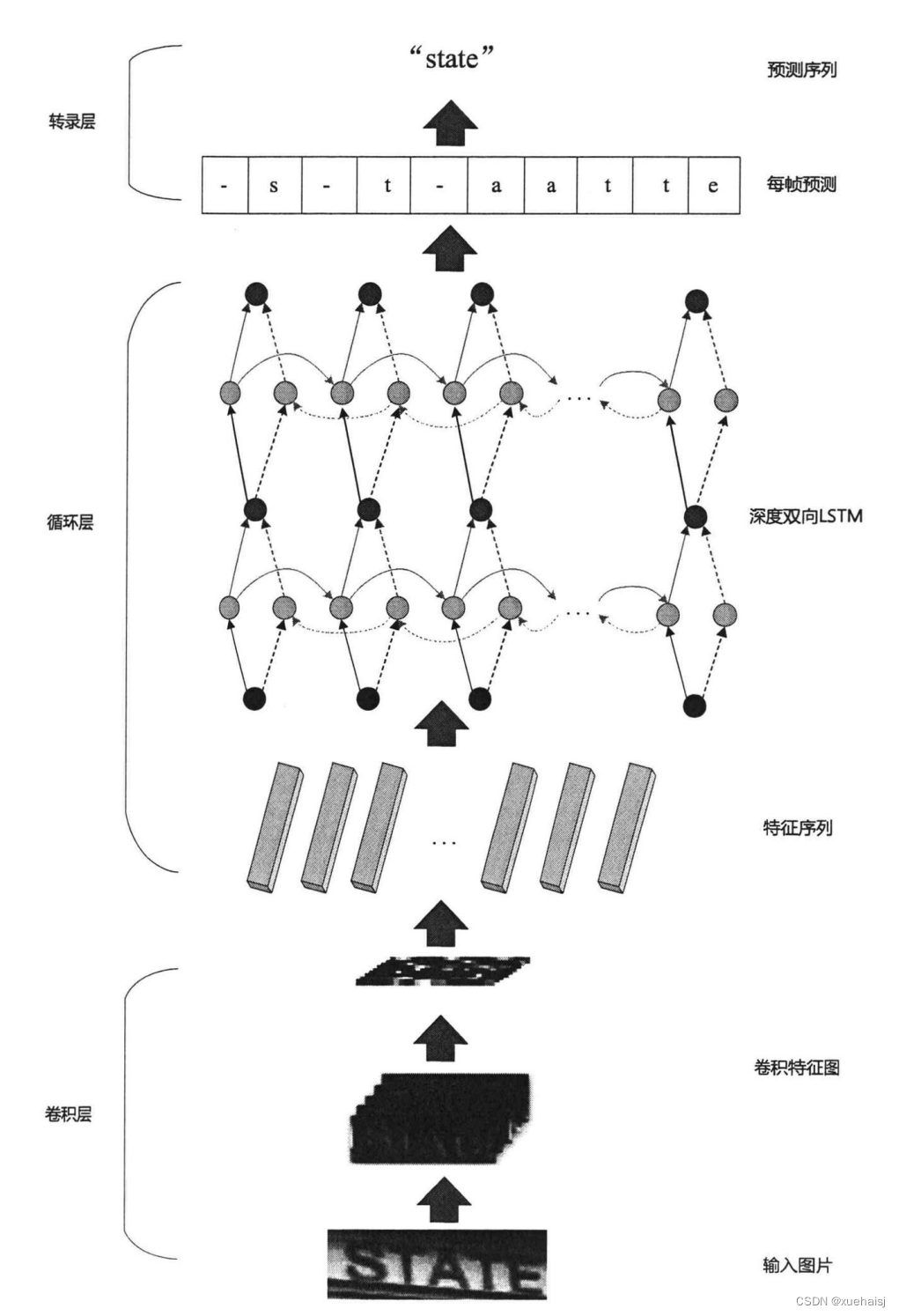
如图所示,它主要分为三步:第一步通过卷积层(CNN)对输入的实验图片进行特征提取,第二步在循环层(RNN)使用BLSTM(双向的RNN网络)对特征序列进行预测识别,第三步在转录层(CTC Loss)引入CTC解决训练时字符的不对齐问题,并可以使经历循环层之后得到的一系列标签转换成我们期望的标签序列。
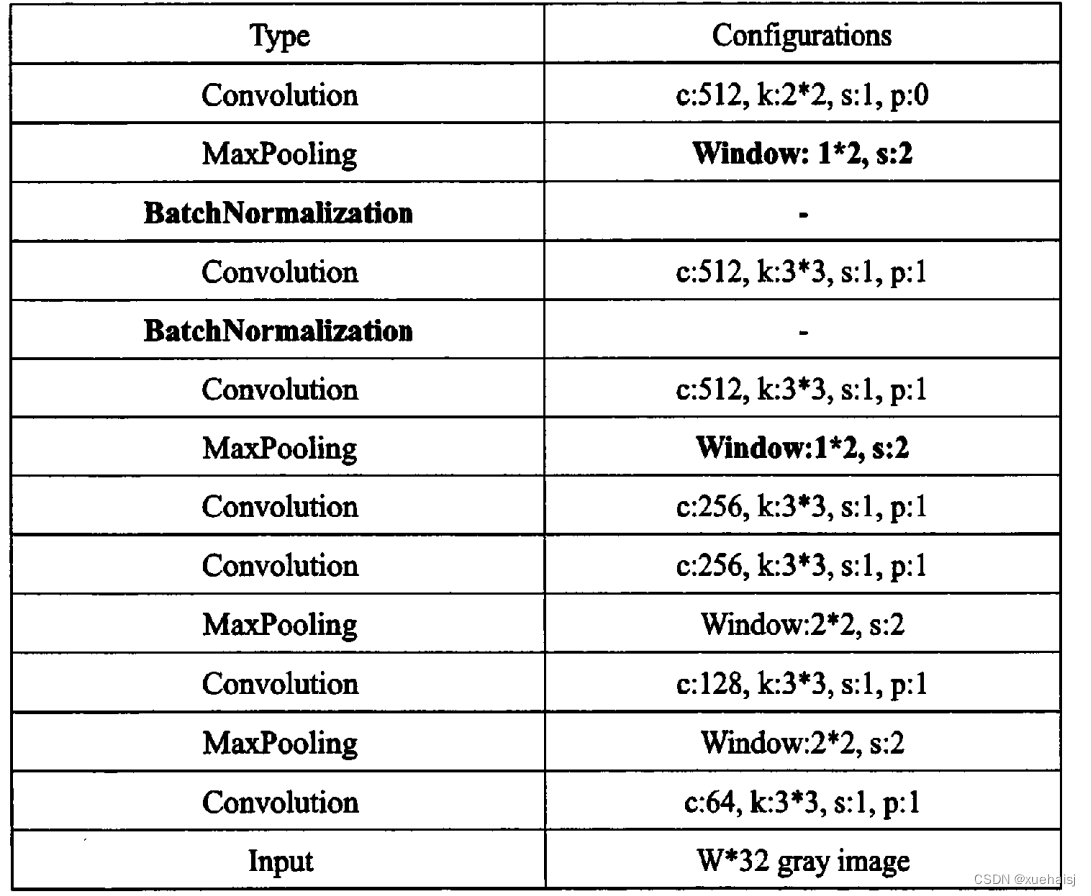
CNN网络结构参数如表4-1所示,其中卷积层(图中的Convolution),主要作用是提取图像特征。在整个流程中,输入的图像高度为32,这是固定的,宽度W可以是其他的值,但必须统一。
在特征提取的整个流程中,CRNN通过归一化处理模块,使得模型的收敛速度更快,以此让整个训练过程的时间大大缩短。同时,表中有一些地方的改动需要注意,如表4-1,一共有四个Max Pooling(最大池化层),但是需要注意的是最后两个池化层,它们的窗口尺寸有所不同,从原来的22尺寸改成了12尺寸,换句话说,图片的高度一共是减半了四次,但是宽度却并非一致,而只是减半了两次,这一选择主要是根据文本图像多数都是长宽短高的情况而定,所以特征图也呈长宽短高的矩形,使用12的池化窗口可以尽量保留在宽度方向的信息。最后CNN得到的特征图尺寸为5121*40。
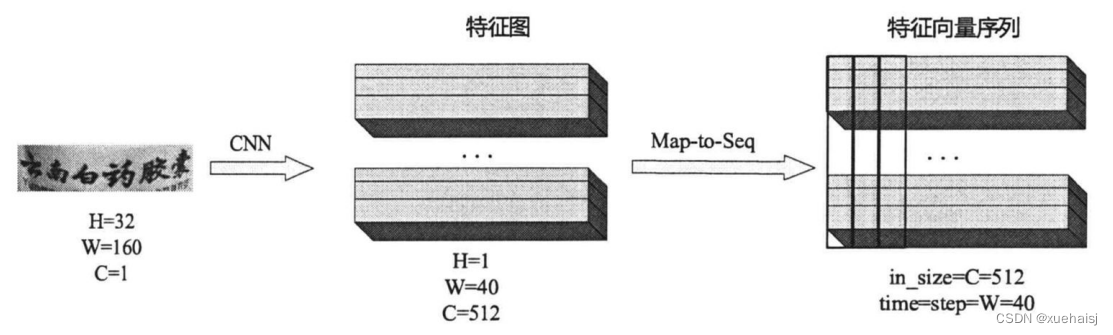
CNN最终得到的特征图,我们在送入RNN训练时需要做出一些调整,具体如图4-3,根据特征图提取RNN所需的特征向量序列。
首先,特征向量序列需要我们从特征图中提取,也就是由CNN模型产生的输出结果,图4-3中的每一个红色框即代表一个特征向量,在特征图上的顺序是从左到右,且按照一定顺序排布,其中的每列都有着512维特征,这些特征向量的集合就是一个序列。
其次,卷积层、池化层(这里是最大池化层)以及激活函数的执行过程都是在局部区域上完成,因此它们往往保持平移不变。在原始图像上,每一个矩形区域,都有相对应的特征向量,这个矩形区域也被称为感受野,因此,特征序列中每个向量都关联者一个感受野。特征图上从左到右的依次排序,这些矩形区域相应列亦是如此。
这些特征向量序列最终都会输入到循环层中,每个特征向量作为循环神经网络在一个时间步的输入。
循环层-序列预测识别
在提取图像特征后,通过循环神经网络(RNN)对该特征中的序列进行预测,由于识别的文字长度并不固定,且RNN有梯度消失的问题,CRNN一般使用双向LSTM网络[4]l来解决该问题。
LSTM 可以捕获长距离依赖皆因其特殊的设计。

LSTM 只会使用过去的信息。但是在基于图像的序列中,有很多时候两个方向上下文不仅是互相有着用处而且很可能是互补关系。因此需要将两个LSTM组合到一个双向LSTM[49]中来应对该种情况,位置摆放可以采用一个向前一个向后的方式。此外双向LSTM还可以进行多层堆叠,深层结构自然会比浅层提供更高层次的抽象。
转录层-输出结果矫正处理
转录就是将RNN对每个特征向量所做的预测转换成标釜序列的过程。仕取后阶段,循环层会逐一将每帧的预测结果概率值输出,通过连接时序分类(CTC)将其转换成标签序列,最终使得输入序列与输出序列相对齐。
CTC可以简单的理解成一种Loss计算方法[50,在Tensorflow和Pytorch中都有对CTC的实现,,常用于解决OCR或者语音识别中的序列对齐问题。CTC 的特点:
(1)引入 blank机制,主要目的是为了解伏部分地刀土子付,问的心以儿理冗余问题。
(2)条件独立,在对路径进行概率计算时,CTC是将各个时间片对应概率值相乘,即CTC将时间片看做是一个个独立的数据。在艾本识别中,显然疋而要上下文联系的,因此模型中需添加了RNN层。
CTC 采用的并不是对齐的方式,它的最终输出是该标签序列中整体概率取大的。可以实现去除冗余的目的,比如字符序列为“MAAN",最终可以映别得到“MAN”,但这样可能会出现预料之外的情况,如“LOOOK”去除冗余z,错误的“LOK",为此,CTC 引入的blank机制起了很大作用,使用“-”代表blank,可以将“LOOK”看做是“-L-O-OO-K-”,这时候去除冗余以及去除blank 会得到想要的“LOOK”序列。
9.模型训练及参数设置
实验环境依旧是基于GPU 4090,使用Pytorch框架,数据集共包含525条文本实例。其中根据8:2的比例划分训练集与测试集,也就是420张作为训练集,105张作为测试集。
在构造实验需要的字典时,我们不仅要构建常规的字符,还需注意要对添加的“-”构建字典,用来预测部分帧没有文本信息。训练中的Encoder和 Decoder会进行编解码操作,主要是依据字典中字符与编号的对应关系。Encoder可以帮助我们根据词典将字符编码成数字,而Decoder可以帮助我们得到去空格和去除重复字符后的预测标签序列。
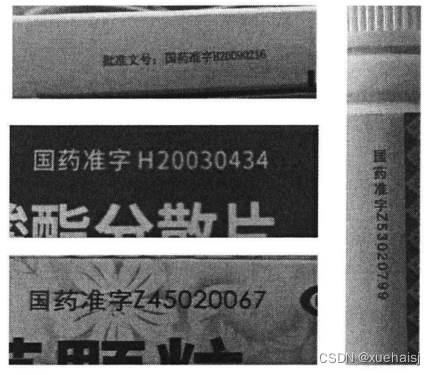
测试过程相较于训练过程,会额外多做一步操作,也就是基于词典的转录操作,主要目的是用于转录的矫正。常规的药品包装盒上会有固定的文本行,同时部分药名较为常见,因此可以对这些文本进行词典转录,剩余的文字行采用无词典转录。但需要注意的是,并不是所有的文字都是固定的,比如每个药品都有自己的国药准字但后面的编号各不相同:
所以在构建词典时,我们需要保留固定信息,去除其他项,同时较重要的一点是,在词典转录使用CTCloss前,需设置好一个阈值,当大于该阈值时,使用非词典转录的结果,反之则采用词典转录后的结果。

10.训练结果分析
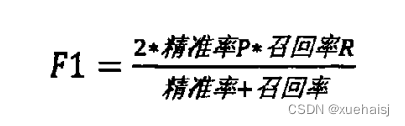
由于本次实验采集到的废弃药品数据集有限,药品种类也并不是很多,因此根据药名建立起词典的工作也相对较轻松,表直观展示了基于词典转录相较于非词典转录在识别精准率和召回率上的优势。其中精准率Р较好理解,是指在该实验中预测正确的数据样本占总样本的比例,召回率R是指实际识别到的文字占总文本字数的百分比。F表示的是F1值,用于评价方法的有效性,F1的计算公式如下:

与此同时,还应着重关注字段的识别准确度,尤其是药品领域,需要保证检测到的文本行都能够准确识别出来,避免错识别或漏识别。在实验中,若出现漏识别如“盐酸二氧丙嗪片”识别为“盐酸二氧丙",则识别精准率就是0。从表可以看出,在文本字段识别率上,基于词典转录的识别精准率也会有一定的提高。

11.系统整合

12.参考文献
[1]吕浩田,马志强,王洪彬,等.基于CNN-CTC的蒙古语层迁移语音识别模型[J].中文信息学报.2022,36(6).DOI:10.3969/j.issn.1003-0077.2022.06.005 .
[2]黄庆浩,吕学强,何健,等.BHS-CTPN:一种自然场景下的化验单文字检测方法[J].计算机应用与软件.2022,39(9).DOI:10.3969/j.issn.1000-386x.2022.09.031 .
[3]高弘杨.美国药房废弃处方药的处理之道[J].中国药店.2021,(10).58-60.
[4]李益红,陈袁宇.深度学习场景文本检测方法综述[J].计算机工程与应用.2021,(6).DOI:10.3778/j.issn.1002-8331.2010-0468 .
[5]吴潇颖,李锐,吴胜昔.基于CNN与双向LSTM的行为识别算法[J].计算机工程与设计.2020,(2).DOI:10.16208/j.issn1000-7024.2020.02.010 .
[6]白培瑞,王金博,丁国梅.一种通用的基于图像分割的验证码识别方法[J].山东科技大学学报(自然科学版).2018,(3).DOI:10.16452/j.cnki.sdkjzk.2018.03.014 .
[7]颜宏文,周雅梅,潘楚.基于宽度优先搜索的K-medoids聚类算法[J].计算机应用.2015,(5).DOI:10.11772/j.issn.1001-9081.2015.05.1302 .
[8]朱大奇.人工神经网络研究现状及其展望[J].江南大学学报(自然科学版).2004,(1).DOI:10.3969/j.issn.1671-7147.2004.01.027 .
[9]张冲,黄影平,郭志阳,等.基于语义分割的实时车道线检测方法[J].光电工程.2022,49(5).DOI:10.12086/oee.2022.210378 .
[10]肖子晗.基于深度学习的医疗票据检测与识别[D].2021.

















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









