







大家在将统计学习方法用于实际应用时,不免会遇到各类间数据不太平衡的情况。比如垃圾邮件的识别、稀有病情的诊断、诈骗电话识别、情感分析等等情况。导致数据不平衡的原因有很多,有可能是因为不恰当的采样方法,也可能真实的数据分布就是如此;然而真实的数据分布在大多数情况下我们是无从得知的,于是我们只好认为我们所取得的样本是“真实”的,再从中进行学习。那么针对数据不平衡有很多研究点,最近稍微调研了一下,这也算是一个比较老的Topic了。2000 AAAI/2003 ICML先后有两次Workshop对此进行讨论,之后似乎研究的人就比较少了。
本文主要关注的是在类间数据不平衡的情况下,如何评价分类器的性能?至于这个问题本身的更详细分析,只要在google scholar中搜索“Learning from Imbalance data”就会看一堆资料了,我也看了一些,但是不细致,最近实在是很忙。
在AAAI(2000) Workshop上,有两个问题最受关注。
1:在类不平衡(class imbalances)的情况下,如何评价学习算法的性能?
2:类不平衡与代价敏感学习(cost-sensitive Learning)的关系。
今天稍微研究了一下第一个问题。既然要评价,那么也就默认了一个前提假设:类样本不平衡是符合实际数据分布的(训练集和测试集同分布)。要评价一个二元分类器的性能,人们自然而然地想到Accuracy。而对于不平衡数据,这是否合适?看一个简单的例子:假设这个世界上有99.9%的人不患癌症,0.01%的人身患癌症。于是我们想设计一个分类器,来判断一个病人是否身患癌症。那么在已有先验知识的情况下,我只需要认为所有病人都不患癌症,那么分类器至少能达到99.9%的分类准确率。显然,这个分类器一点儿价值也没有。同理,对于n:1(n比较大)的类样本分布,只需要认为所有样本都属于n那一类,准确率就可以达到非常高,可是没有任何意义和参考价值。所以,Accuracy的衡量标准在这里是不合适的。

其中列对应于样本实际的类别,行对应于样本被预测的类别。这四个基本指标可以衍生出多个分类器指标:
1:FP rate = FP / N;N为负样本数
2:TP rate = TP / P;P为正样本数
3:Accuracy = (TP + TN) / (P + N);//我们一般用的
4:Precision = TP / (TP + FP)
5:Recall = TP / P
6:F-score = Precision * Recall
其中Accuracy是我们最经常使用的,在某些领域,Precision/Recall也很频繁。
以上这些都属于静态的评价指标,如前所述,当正负样本不平衡时存在严重的问题。
于是,ROC曲线和AUC(曲线包围面积)应运而生。
ROC曲线描述的是混淆矩阵中FPR(FP rate)和TPR两个量之间的相对变化关系。如果二元分类器给出的是对正样本的一个分类概率,那么通过设定不同的阈值,可以得到不同的混淆矩阵,而每个混淆矩阵都对应于ROC曲线上的一个点。将这些点描绘出来可以得到一条平滑的曲线,这时,我们可以用曲线所包围的面积,即AUC,来评估该二元分类器的可信度。这就是ROC分析,说完啦。看一幅来自Wikipedia的图:
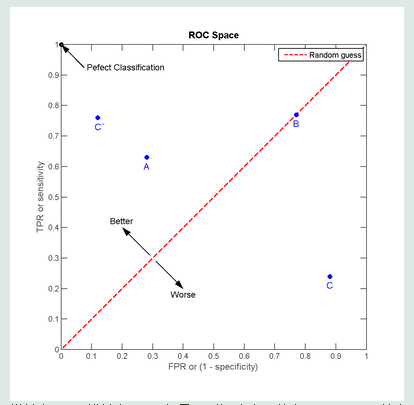
横轴为FPR,纵轴为TPR。如果混淆矩阵表示的点(FPR,TPR)处在中间那根红线上,则表示该分类器没有区分能力。以前面的n:1为例,如果分类器简单地把所有样本分至n这一类,则正好处在右上角,即(1, 1)。再试想一下数据平衡1:1的情况,当分类器处于红线上时,容易计算出Accuracy为50%,对于二元分类器而言,没有什么比准确率低于50%更丢人的事情了……
所以,点若处在左上角部分,则说明分类器性能不错,若不幸在右下角,那么这个分类器无疑是一坨。。
我们根据不同的阈值得到了ROC曲线之后:
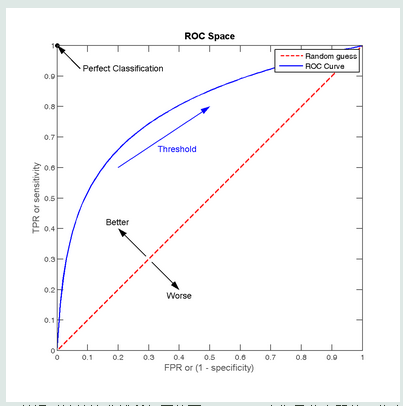
可以通过计算该曲线所包围的面积(AUC)来衡量分类器的可信度。面积越大,则可信度越高。不过面积可不好计算,因为我们得到的都是离散点。对此有兴趣的话,可以参考下这篇文章(ICML 2006)
The Relationship Between Precision-Recall and ROC Curves
这篇文章附着一个计算AUC的Java工具包:http://mark.goadrich.com/programs/AUC/
一般认为,对于一个诊断实验,AUC在0.5~0.7之间时,诊断价值较低;在0.7~0.9之间,诊断价值中等;在0.9以上时诊断价值较高。这是医学诊断上的经验了,对于其他领域的分类器如何,还需要在实践中摸索。
本文主要关注的是在类间数据不平衡的情况下,如何评价分类器的性能?至于这个问题本身的更详细分析,只要在google scholar中搜索“Learning from Imbalance data”就会看一堆资料了,我也看了一些,但是不细致,最近实在是很忙。
在AAAI(2000) Workshop上,有两个问题最受关注。
1:在类不平衡(class imbalances)的情况下,如何评价学习算法的性能?
2:类不平衡与代价敏感学习(cost-sensitive Learning)的关系。
今天稍微研究了一下第一个问题。既然要评价,那么也就默认了一个前提假设:类样本不平衡是符合实际数据分布的(训练集和测试集同分布)。要评价一个二元分类器的性能,人们自然而然地想到Accuracy。而对于不平衡数据,这是否合适?看一个简单的例子:假设这个世界上有99.9%的人不患癌症,0.01%的人身患癌症。于是我们想设计一个分类器,来判断一个病人是否身患癌症。那么在已有先验知识的情况下,我只需要认为所有病人都不患癌症,那么分类器至少能达到99.9%的分类准确率。显然,这个分类器一点儿价值也没有。同理,对于n:1(n比较大)的类样本分布,只需要认为所有样本都属于n那一类,准确率就可以达到非常高,可是没有任何意义和参考价值。所以,Accuracy的衡量标准在这里是不合适的。
ROC分析为这个问题提供了一个比Accuracy更为准确的度量方式:)
ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。
其中列对应于样本实际的类别,行对应于样本被预测的类别。这四个基本指标可以衍生出多个分类器指标:
1:FP rate = FP / N;N为负样本数
2:TP rate = TP / P;P为正样本数
3:Accuracy = (TP + TN) / (P + N);//我们一般用的
4:Precision = TP / (TP + FP)
5:Recall = TP / P
6:F-score = Precision * Recall
其中Accuracy是我们最经常使用的,在某些领域,Precision/Recall也很频繁。
以上这些都属于静态的评价指标,如前所述,当正负样本不平衡时存在严重的问题。
于是,ROC曲线和AUC(曲线包围面积)应运而生。
ROC曲线描述的是混淆矩阵中FPR(FP rate)和TPR两个量之间的相对变化关系。如果二元分类器给出的是对正样本的一个分类概率,那么通过设定不同的阈值,可以得到不同的混淆矩阵,而每个混淆矩阵都对应于ROC曲线上的一个点。将这些点描绘出来可以得到一条平滑的曲线,这时,我们可以用曲线所包围的面积,即AUC,来评估该二元分类器的可信度。这就是ROC分析,说完啦。看一幅来自Wikipedia的图:
横轴为FPR,纵轴为TPR。如果混淆矩阵表示的点(FPR,TPR)处在中间那根红线上,则表示该分类器没有区分能力。以前面的n:1为例,如果分类器简单地把所有样本分至n这一类,则正好处在右上角,即(1, 1)。再试想一下数据平衡1:1的情况,当分类器处于红线上时,容易计算出Accuracy为50%,对于二元分类器而言,没有什么比准确率低于50%更丢人的事情了……
所以,点若处在左上角部分,则说明分类器性能不错,若不幸在右下角,那么这个分类器无疑是一坨。。
我们根据不同的阈值得到了ROC曲线之后:
可以通过计算该曲线所包围的面积(AUC)来衡量分类器的可信度。面积越大,则可信度越高。不过面积可不好计算,因为我们得到的都是离散点。对此有兴趣的话,可以参考下这篇文章(ICML 2006)
The Relationship Between Precision-Recall and ROC Curves
这篇文章附着一个计算AUC的Java工具包:http://mark.goadrich.com/programs/AUC/
一般认为,对于一个诊断实验,AUC在0.5~0.7之间时,诊断价值较低;在0.7~0.9之间,诊断价值中等;在0.9以上时诊断价值较高。这是医学诊断上的经验了,对于其他领域的分类器如何,还需要在实践中摸索。

















 494
494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









