







记录一下DeepSeek大模型在我们公司业务场景应用落地的思考过程,以供同行者们参考。
笔者是上海XX科技公司的管理人员,事情的起因是源于我们的主营业务【基于医药行业的供应链金融服务】的需求,我们对接了许多资金方,每天有大几千笔的放款业务不断的实时发生,为了能实时便捷的得到任意年、月、日的放款数据,我们在DeepSeek出来之前就一直在探讨相应的实现方案。
我设想的理想方式,就是给我配备一个全能的助理,我只要口头发出指令,助理就能明白我的意图,并立即(秒级)从公司管理系统中获取到实时数据,形成文档、表格或图表给我,如下图所示。
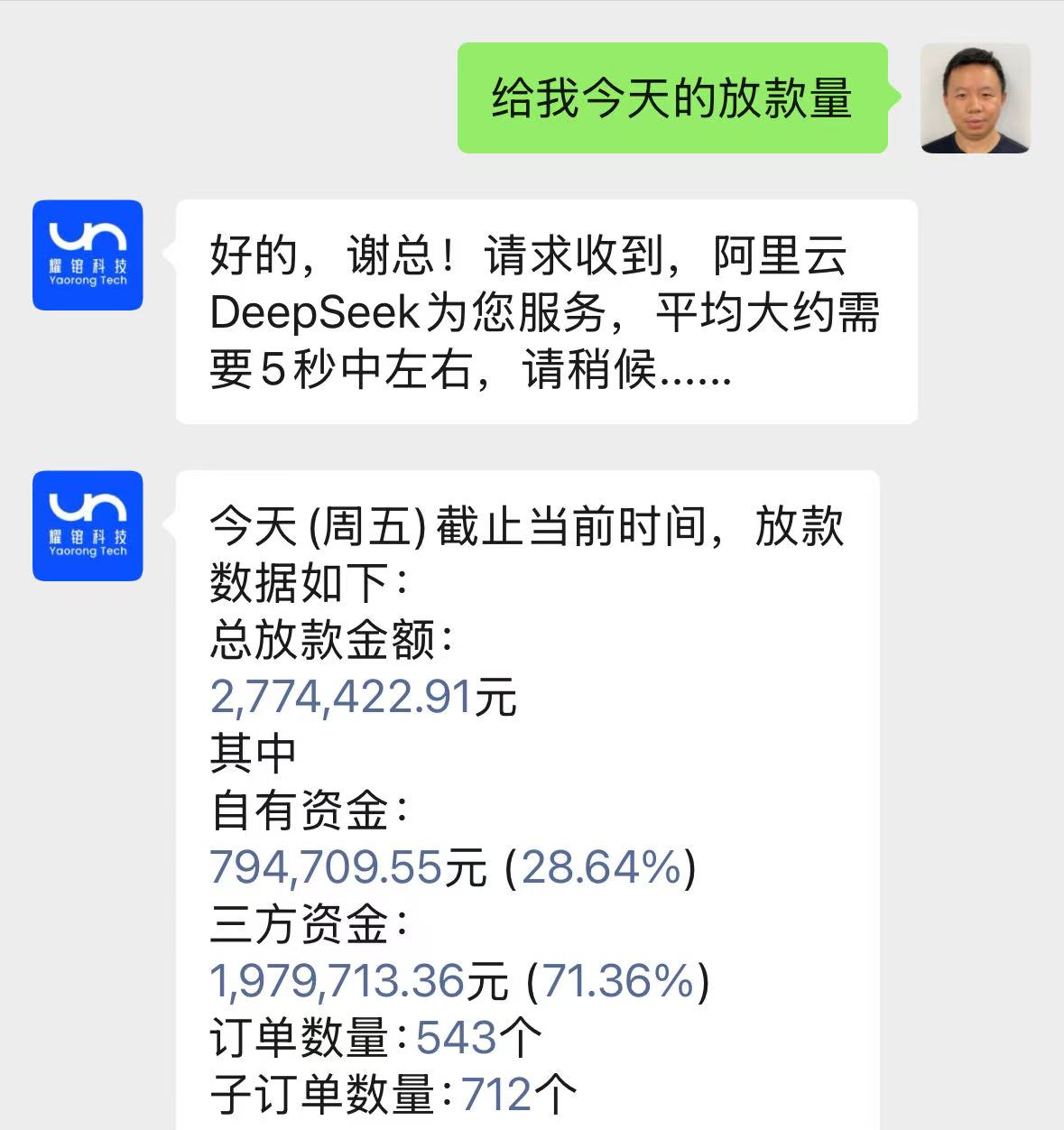
当然这样的助理现实中是不存在,没有人能这么快实现我的需求。但是DeepSeek的出现,给了我们希望,因为它足够聪明,能理解自然语言表达的的意图,也足够便宜,能让公司轻松承担大模型应用带来的成本增加。经过公司技术团队两个月的努力尝试,我们已经实现上述的需求。
基于企业的(ToB)大模型应用,与大家熟悉的豆包、Kimi、文心一言、通义千问等面向个人(ToC)是有很大的不同的。其中有几个主要的痛点如下:
1、ToB应用要有权限的控制。不同角色对同样的指令要有不一样的响应。例如:同样的是查询放款量,管理人员能查,运维人员就得提示用户没有授权,无法查询。同样的是查询客户额度,分配给你的客户能查,没有分配的客户,就不能返回相应的内容。
2、ToB应用更注意数据的安全。企业都不会愿意把自己的核心业务数据上传到公网,所以对于调用云端的API或服务,就会非常介意。对于大模型应用,企业的第一反应是要求本地化部署,但这必须带来成本的上升和更新升级的不便。
3、ToB场景决策和执行往往是分离的。管理员下发指令,然后由中层或基层人员去执行。这样在实时性方便就很难满足决策支持要需求。当执行人员整理好数据时,决策者可能已经在想新的问题了。
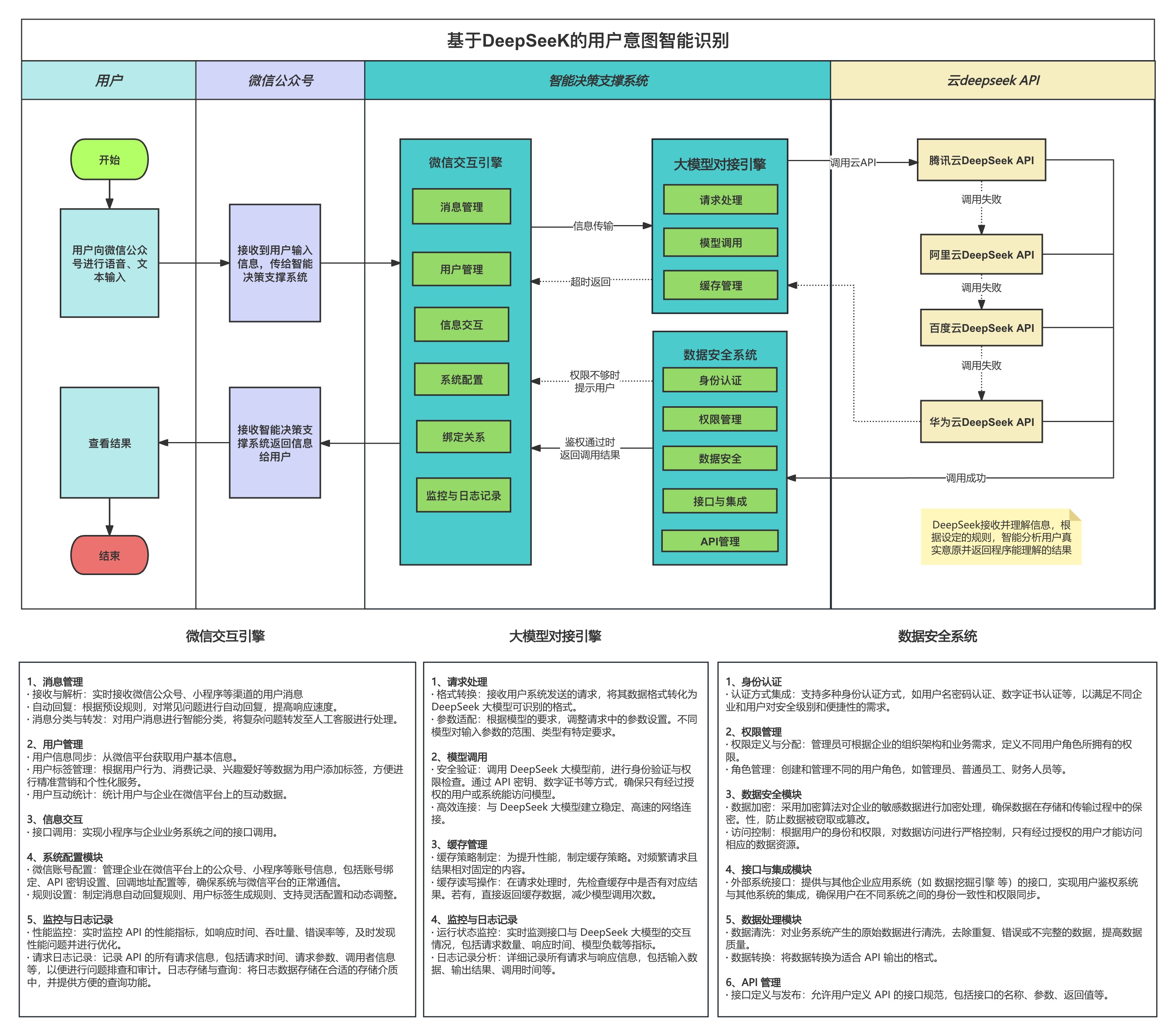
为了解决上述痛点,我们团队经过大量的尝试和实践,最终选择了微信公众号做为大模型应用的载体。首先,通过微信公众号的强大的语音转文字功能,解决了输入要便捷的问题。即使年龄偏大的管理者也能够像与身边人交流一样,通过语音向大模型应用发出指令。其次,通过对接各个大厂部署DeepSeek的满血版API,解决用户意图智能识别的问题,实测下来,识别的准确率还是很高的。再次,通过DeepSeek的意图智能识别,再让公众号后台服务去调用我们预定义的API,查得数据,生成图文消息,返回到公众号对话框。这样既利用了云端DeepSeek的满血版API的能力,又能避免企业业务数据暴露在公网。具体架构如下图所示。
最后,展示一下成果。识别用户意图后,剩下的就是传统的手艺了。通过预定义API查得的企业业务数据,可以生成文字消息、图片、PDF、EXCEL等形式,实时返回到公众号的对话框。以即时满足老板们的决策需求。如下所示:
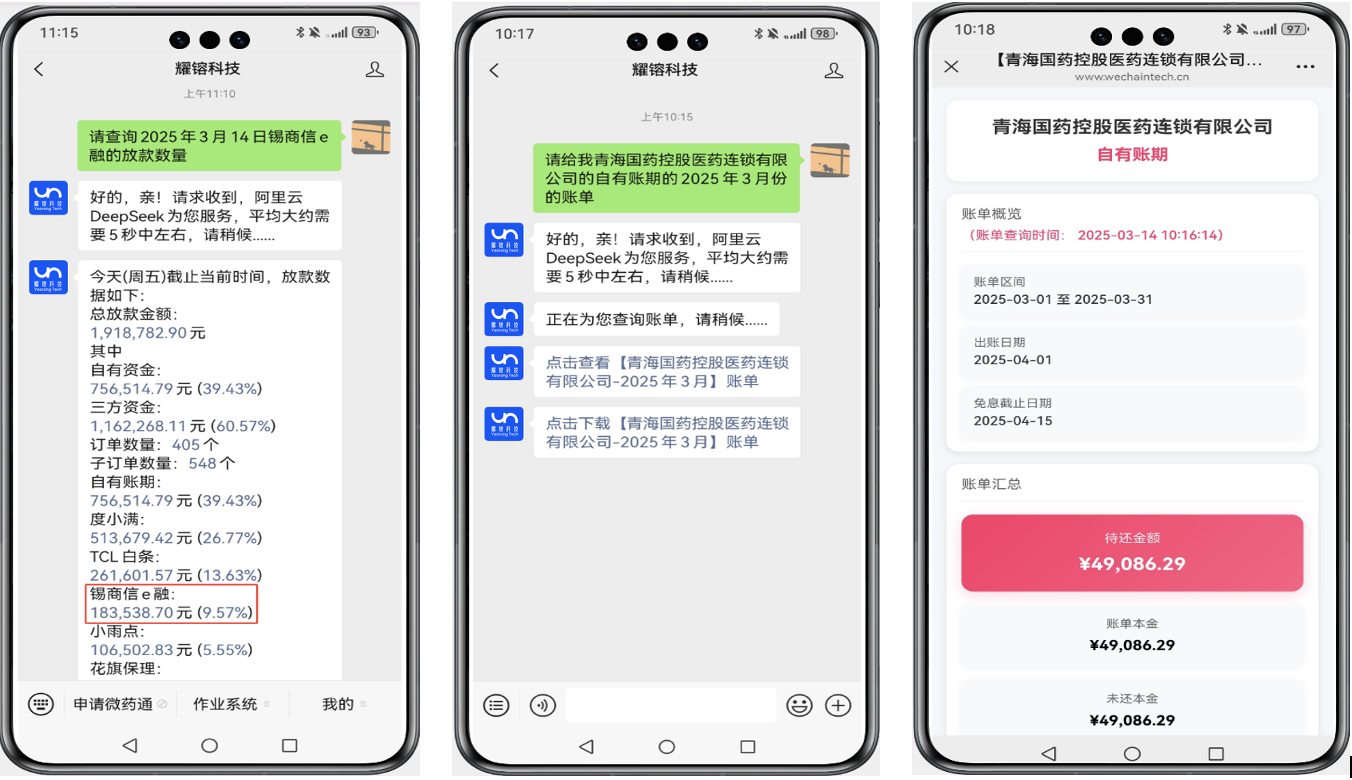
后记,大模型确实能实实在在的提升我们企业的生产力,怎么利用大模型能力为我所用,还待诸君努力。简单记录,共勉之。

















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









