






花 30 秒用 5 行代码写个 RAG 应用
这个点子不是我想出来的,是 llamaindex 想出来的。llamaindex 是啥?
LlamaIndex 是一个框架,用于使用 llm(包括 agents 和 workflows)构建上下文增强的生成式人工智能应用程序。
当然也包括创建 RAG 应用,因为最流行的上下文增强示例就是 RAG(Retrieval-Augmented Generation, RAG),也就是在推理时将上下文与 llm 结合起来的检索增强。
简单来说:RAG(Retrieval-Augmented Generation)是一种结合检索和生成技术的人工智能方法,通过从外部知识源检索相关信息,增强语言模型的生成能力,提高输出的准确性和相关性。
LlamaIndex
在进入正题前,关于 LlamaIndex 我还是要再多说几句。
LlamaIndex 是一个开源框架:https://github.com/run-llama/llama_index
-
它是用
Python写的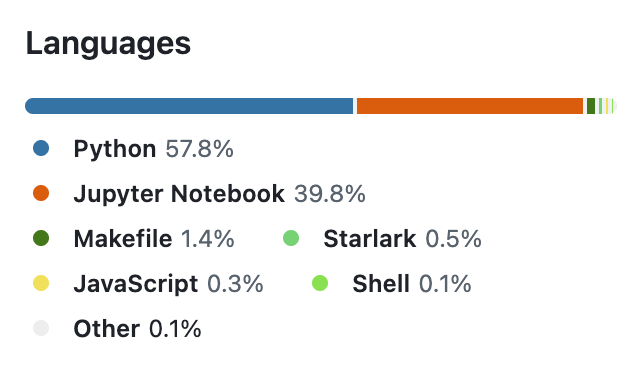
-
最新版本是:
0.11.14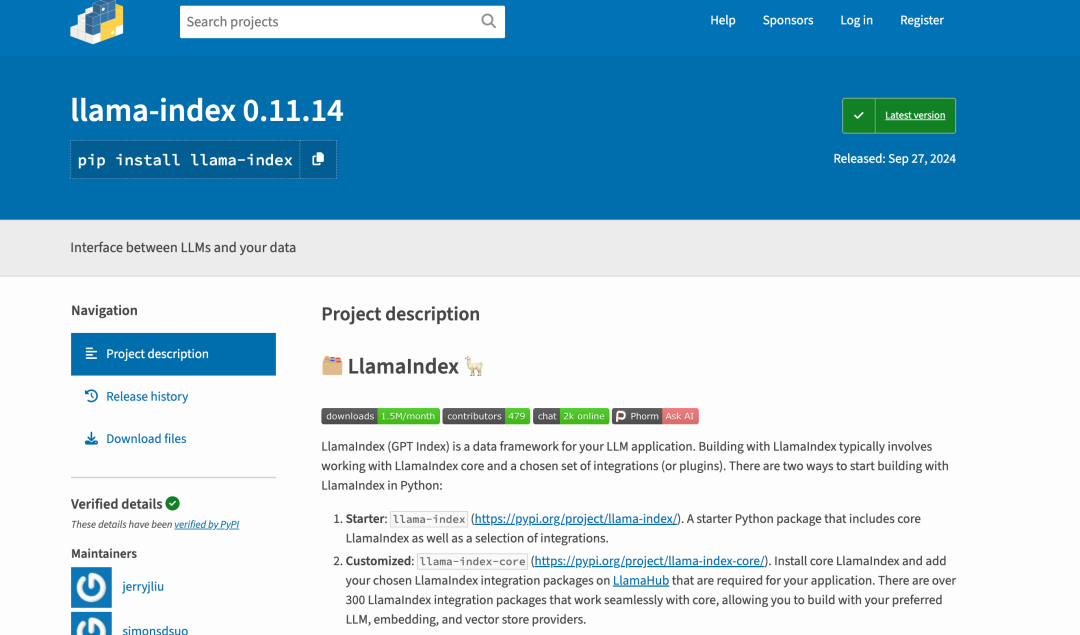
-
官网地址是:
https://www.llamaindex.ai/
在今年夏天的某个会议上,从 LlamaIndex 团队成员那儿得知,他们是一个规模很小的创业公司,当时团队成员大概 15 人左右。
30 秒 5 行代码
前文说了 30 秒 5 行代码的主意不是我想到的,而是来源于 LlamaIndex ,具体说是 LlamaIndex 的文档中写的:
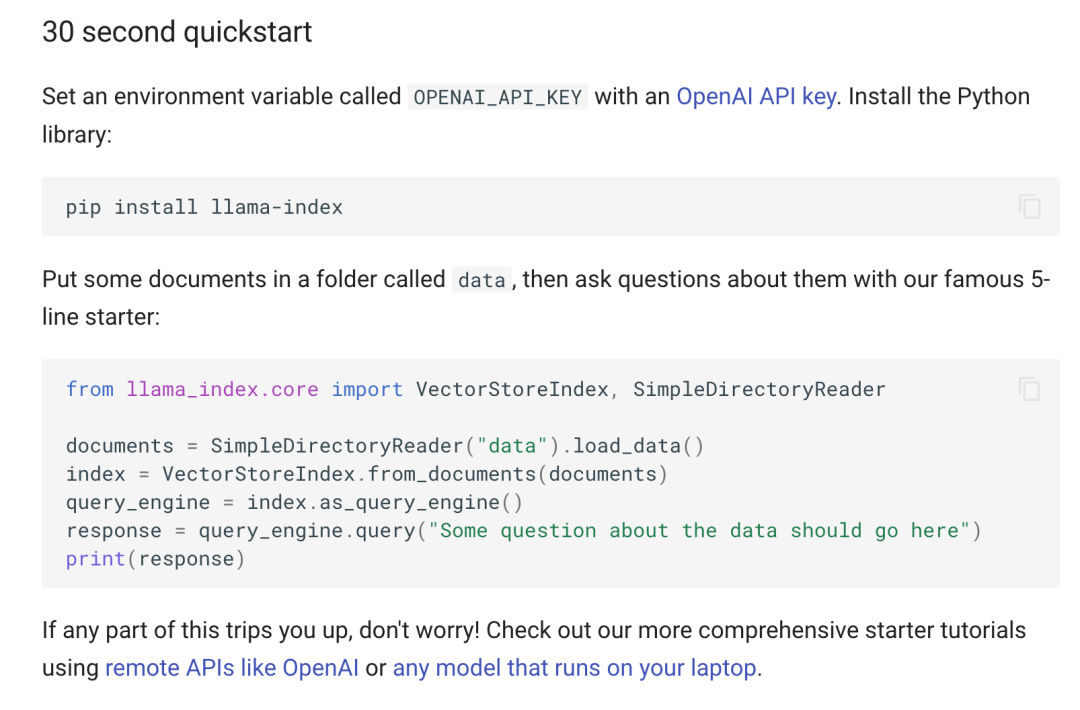
事实也的确如此,但是,这里有一些前提条件。
首先,从字面上你也能看出来,运行这 5 行代码需要 OpenAI 的 API key。
其次,无论你懂不懂编程,我告诉你这 5 行代码是 Python 语言写的。那么你要有一个 Python 语言的运行环境,以及你最好懂得如何用 Python 编程。关于这一点,对于不懂编程的朋友确实不太友好了。不过值得庆幸的是,Python 语言本身很强大,很好上手,容易学习。门槛并不算太高。虽然我们要开发的应用是跟人工智能(AI)相关的,但也不要被吓到了,以为会多么难。其实有很大一部分所谓的 AI 产品也只是 AI、大模型的应用产品。开发那些产品的工程师甚至也只是能算是大模型应用开发工程师,还用不到多么艰深的技术呢。(这里并没有拉踩的意思,只是客观表述。能把技术应用的很好,做出满足用户需求的创新性产品也是非常有价值的,做出这样产品的人也当然值得尊重)
安装 Python
我们先解决 Python 的问题,对于已经熟练掌握 Python 开发的就可以跳过了。对于编程小白或其他语言开发者(如 Java) 可以看看。
我们得搭建一个 Python 的开发和运行环境。关于 Python 的安装网上教程一大堆,无论你的操作系统是 Windows、Mac 还是 Linux 都很容易。我就不罗嗦了。
我的操作系统是 MacOS, 后文的具体操作细节都是基于我本地的 Mac 电脑,所以请大家注意,下图是我的的电脑系统情况:
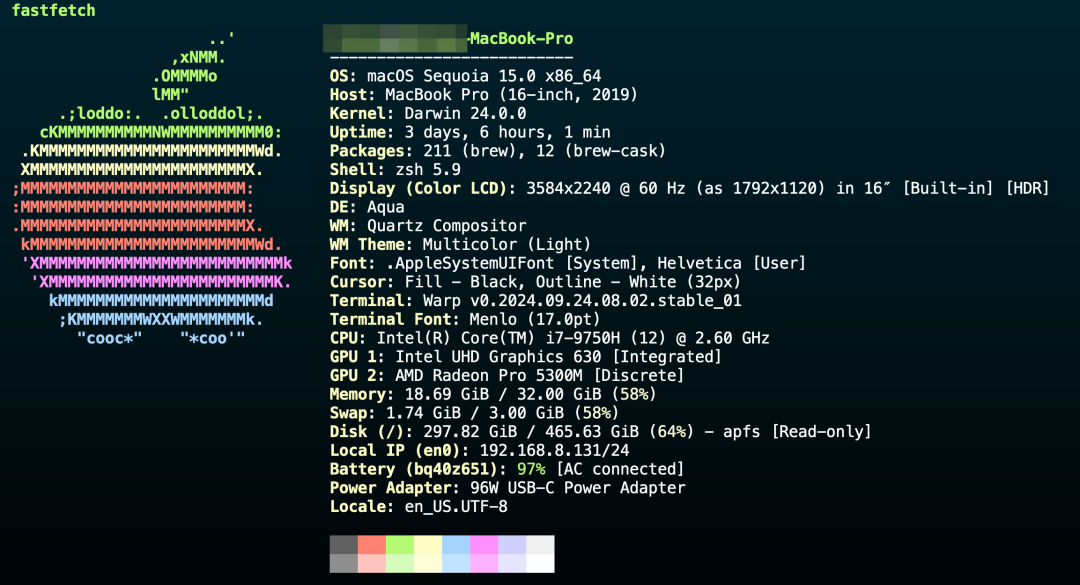
Python 比较常见的大版本有 Python2 和 Python3 , 我使用的版本是 Python3,具体来说是 3.12.4 算是个比较新的版本了

关于 Python 的安装,我更建议用 Conda ,它可以创建多个不同 Python 版本的环境,相当于一个 Python 环境和版本管理工具。这样你就可以创建多个不同 Python 版本的环境,相互之间隔离,互不影响。因为有时候不同的项目用到不同的 Python 版本,混在一起比较麻烦,有了 Conda 就方便多了。
Conda 可以到这里下载安装:https://docs.anaconda.com/free/miniconda/
安装好以后记得设置一下镜像源,不然下载比较慢:

以下是一些基础命令:

Python 安装好以后,我们还需要一个开发工具,即 IDE,你可以选择 VSCode,PyCharm,Cursor,Zed 等等。这里我推荐 Cursor,因为借用 claude 及 gpt 等大模型的能力,你可以一边快速开发一边快速学习,高效产出的同时高效吸收,简直太爽啦。
学习 Python
关于 Python 的学习,我这里对于特别小白的,尤其是从来没有接触过编程的朋友没有什么具体的建议,因为我从未指导过类似情况的朋友,所以没有经验,不能乱说,怕误人子弟。因为我既不知道用什么样的方式也不知道用什么样的资料指导有用。不过我觉得对于小白,能持续学习下去是最重要的,不要找太难的资料,可以找一些你容易上手,容易看懂的资料来学习,有持续的正反馈,计算机相关的知识很多,有些确实难懂,有持续的正反馈你才不至于半途而废。
而对于其他语言的开发者,其实已经具备了基础的计算机知识,甚至也已经是某些编程语言的专家了。那么学习 Python 对于你来说就比较容易了,一理通百理明。都大差不差的。
认认真真把其中一个资料看完。一般来说,用 2 个星期,每天 1-2 个小时左右,快的话甚至一个星期你就能基本掌握这门语言了。
我知道很多朋友不满足只是基本掌握,想更精进,那么就需要再加码了,这里我推荐系统地看一些书,因为书籍会相对系统地讲解知识,这样你对 Python 以及 Python 相关的技术就会有一个全面而深入的了解了。
编程
现在我们假设你已经有了一个 Python 的运行环境及开发工具。那么接下来我们就要正式开始编写这 5 行代码了(铺垫这么多终于要写代码了~)
首先我们要建一个工程,这很简单,不多说。
然后根据文档所示,我们要安装 llama-index 的依赖包,在项目根路径下执行
pip install llama-index
当然,如果你使用的是 Python3 ,可以这样安装:
pip3 install llama-index
安装好依赖包以后我们创建 main.py 文件,并编写程序:

别看这段只有几行代码,却有好几个问题,我们一个一个地说。
第一个问题是:如果你直接运行 main.py 这个文件会报错,错误总结来说就是你没有 OpenAI 的 Api Key 。是啊,我们压根就没有设置,其实我也不想设置,因为这个 key 是要花钱的,我不想花钱,那怎么办?
用 OPENAI_API_KEY 的目的就是要通过 OpenAI 的 API 调用 OpenAI 的大语言模型。我们知道那是收费的,所以我们要用开源免费的模型,将模型安装到本地使用,这样就不用花钱了。所以我们要用 Ollama 安装开源模型到本地进行调用。关于 Ollama 以及模型的安装我在之前的文章中有详细说明,这里就不赘述了。大家可以参考。
我这里下载使用的是 Qwen2:7b 的模型

第二个问题是:代码中的 data 在哪里
documents = SimpleDirectoryReader("data").load_data()
data 是一个文件夹,需要我们在项目的根路径下创建,名字就叫 data。而在 data 文件夹中我们是要下载测试文本的,通过这个地址下载测试文本:
- https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt
文件类型当然就是 .txt 文件。原文是英文的,但因为我想做中文的测试,所以,我把内容全部翻译成了中文并保存。(如果你看过《黑客与画家》 这本书,你一定会对文本内容感兴趣的!) 这个文件的文件名你可以随意取。
第三个问题是:用哪个 embedding 模型?
前面我们说了,我们不用 OpenAI 的 API 了,这样的话,其实整个代码结构会发生变化 ,就不是原始的那 5 行代码了,而会变成下面这样(别担心,只多了一行)

可以看到代码中写的 embedding 模型是 BAAI/bge-base-en-v1.5
接触过 RAG 的朋友对 embedding 模型比较熟悉,这里简单地为不了解的朋友解释一下:
Embedding 模型是将离散的输入(如单词或文档)转换为连续向量表示的模型,在 RAG 中用于将查询和检索到的文档片段映射到同一向量空间,以便计算相似度和生成相关响应。
它和 RAG 的关系,可以参考下图:
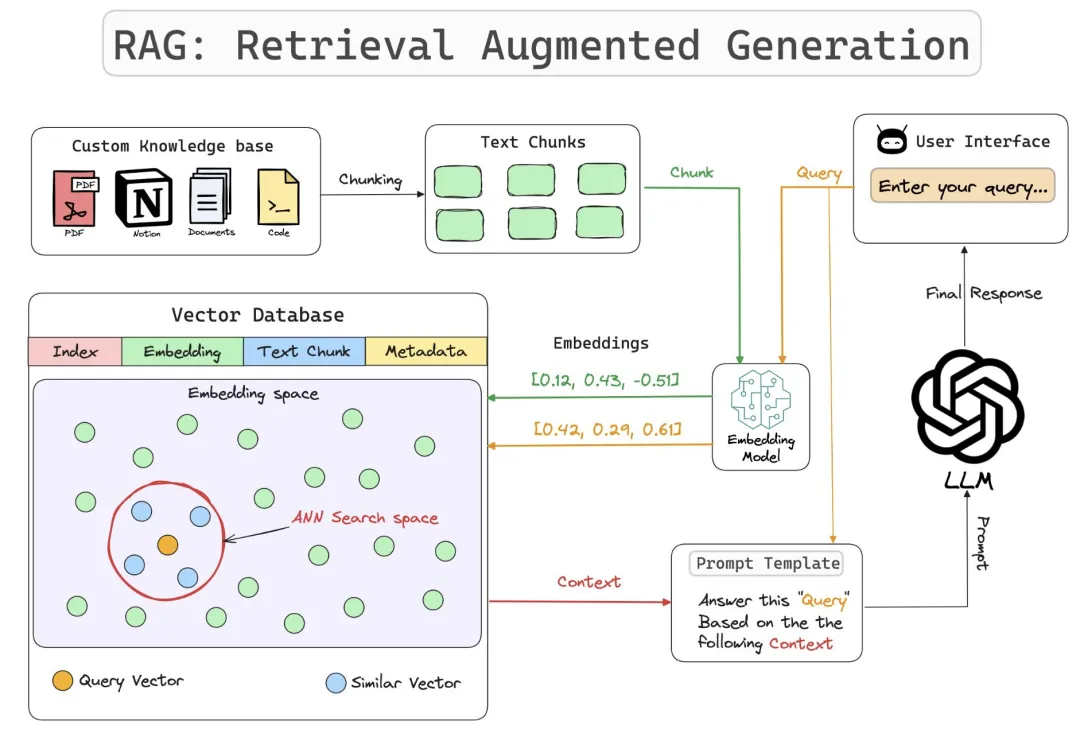
我们这 5 行代码想实现的就是 RAG,所以一定少不了 embedding 模型。embedding 模型也分收费的和开源免费的,另外上文中提到的 BAAI/bge-base-en-v1.5 是一个处理英文的模型,我想处理的是中文,所以不适用。我们要找一个免费开源且支持中文的 embedding 模型。到哪里找呢?Hugging Face!(Hugging Face 你可以把它理解成大模型领域的 GitHub)
从 Hugging Face 上可以找到大量的开源免费的 embedding 模型,数量很多,选哪一个呢?我们可以从 https://huggingface.co/spaces/mteb/leaderboard 这个大规模文本嵌入基准(MTEB)排行榜中,根据你的需求来挑选。
比如我选择的是支持中文的,模型大小不是特别大的
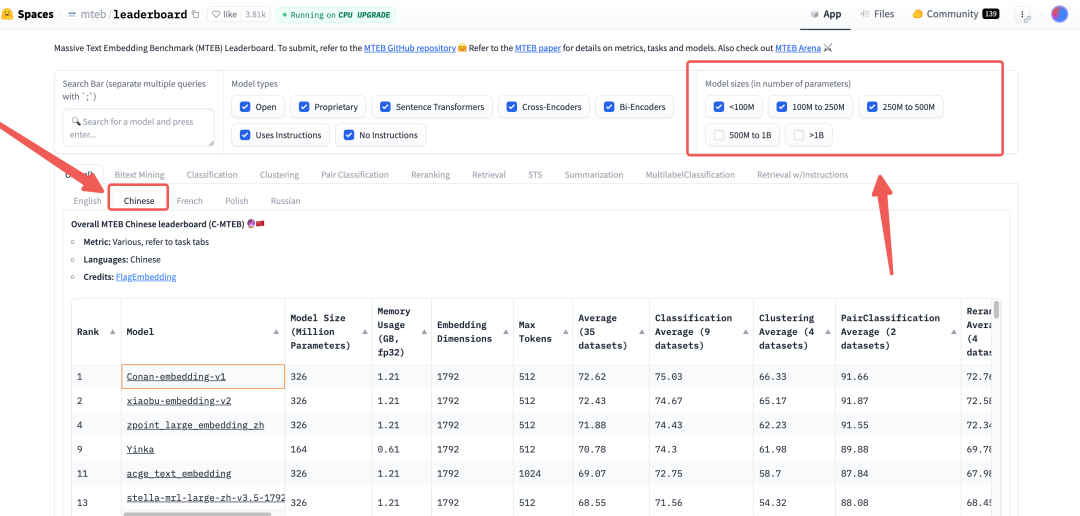
最终我选择的模型是 :BAAI/bge-base-zh-v1.5
以上三个问题都解决了以后,我们看一下最终的代码成品:

实话实说,是比 5 行多了 2 行。但也已经很精练了,因为这是 LlamaIndex 做过高级别封装以后的 API,如果想做具体而细致的编程控制,可以使用低级别封装的 API。
代码我没有写注释,因为是想让读者看看它有多精练。用 LlamaIndex 就这么简单,几行代码就可以实现 RAG 了。
以下是我加入注释以后的,方便你理解它:

运行这段代码会自动下载 embedding 模型,你可能会关心模型下载到哪里了,在我电脑上是这个路径 :~/Library/Caches/llama_index
代码 第一次执行时间比较长,大概有个几十秒。

但再次执行应该是有缓存了,就会比较快了,下图就只执行了 10 秒左右。

当然,你还可以基于测试文本进行其他查询,看看它分析的是否准确。
以上图片中的输出每一步都有时间,是因为我对程序做了重构,用装饰器加上了每一步执行时间的打印输出,代码如下:



由于后续除了 LlamaIndex 又安装了几个依赖库,所以在项目根路径下创建了 requirements.txt 文件,文件内容如下:

执行以下命令一次性安装所有依赖:pip3 install -r requirements.txt 这样方便一些。
RAG 应用创建完成
有了以上的代码基础,其实一个小型的 RAG 应用的核心就完成了,我可以基于本地知识库结合大语言模型进行自然语言的查询了。
比如我问:“作者跟 Sam 的关系是怎样的?”
回答是:“作者与 Sam Altman 的关系是在 2013 年决定让他成为 YC(Y Combinator)的总裁。在那之前,他们可能有某种工作或业务上的联系,因为他们讨论了重组 YC 并让 Sam 接任总裁职位的事情。通过这个决策,可以看出作者认为 Sam 适合领导 YC,并且在 Sam 最初拒绝后,作者坚持不懈地说服他接受这一角色。最终,在 2013 年 10 月,Sam 同意从 2014 年冬季开始接管 YC。这表明两人之间有某种程度的合作和信任关系。”
你看,基于本地知识库的回答比单纯用 LLM 靠谱多了吧。
然后呢? 是的,我们只有一个内核还远远不够,我们还需要漂亮的 UI,更加易用和丰富的功能,程序性能还要强,把它做成一个产品。然后产品还要宣传、推广、积累用户、产品迭代。我们还要赚钱,还要考虑如何盈利。…
差不多了,真的。想到这里,你再看看市面上那些 AI 产品是不是相似的配方?
最后
行文至此,关于这 5 行代码的事情我觉得已经说清楚了。最后感慨一下:AI 赛道真是越来越卷了,但无论无何,感谢 Python , 感谢 LlamaIndex ,感谢开源和为开源做出贡献的人们。有了他们我们才能够如此享受技术带来的红利。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









