




从一个包含食品评论的 CSV 文件中,筛选出最新且长度合规的 1000 条英文评论,调用智谱 AI(ZhipuAI)的 Embedding 模型为每条评论生成语义向量(embedding),并将结果保存为新的 CSV 文件。
ps:我的博客资源里面有对面的初始数据资源excel,还有运行后得到的excel
import os
import pandas as pd
import tiktoken
from openai import api_key
from zhipuai import ZhipuAI
ZHIPU_API_KEY = "XXXX"
#数据预处理
df=pd.read_csv('datas/fine_food_reviews_1k.csv',index_col=0)
df=df[['Time','ProductId','UserId','Score','Summary','Text']]
df=df.dropna()
df['combined']='Title:'+df.Summary.str.strip()+';Content:'+df.Text.str.strip()
#Token控制的配置
tokenizer_name='cl100k_base' #定义将要用到的分词器
max_tokens=8191#过滤掉所有 token 数 > 8191 的评论
top_n=1000#最终只想处理最近的 1000 条有效评论
df.drop('Time',axis=1,inplace=True)
#从 tiktoken 库中加载对应的分词器(Tokenizer)对象,用于将文本转换为模型可理解的 token 序列。
tokenizer=tiktoken.get_encoding(encoding_name=tokenizer_name)
#对每条评论(combined 字段),用这个 tokenizer 精确计算它包含多少 tokens。
#然后过滤掉超过 max_tokens=8191 的评论,避免调用 embedding API 时出错。
df['count_token']=df.combined.apply(lambda x:len(tokenizer.encode(x)))
df=df[df.count_token <= max_tokens].tail(top_n)
client=ZhipuAI(api_key=ZHIPU_API_KEY)
def embedding_text(text,model="embedding-3"):
resp=client.embeddings.create(model=model,input=text)
return resp.data[0].embedding
df['embedding']=df['combined'].apply(embedding_text)
df.to_csv('datas/embedding_output_1k_zhipu_1.csv',index=False)
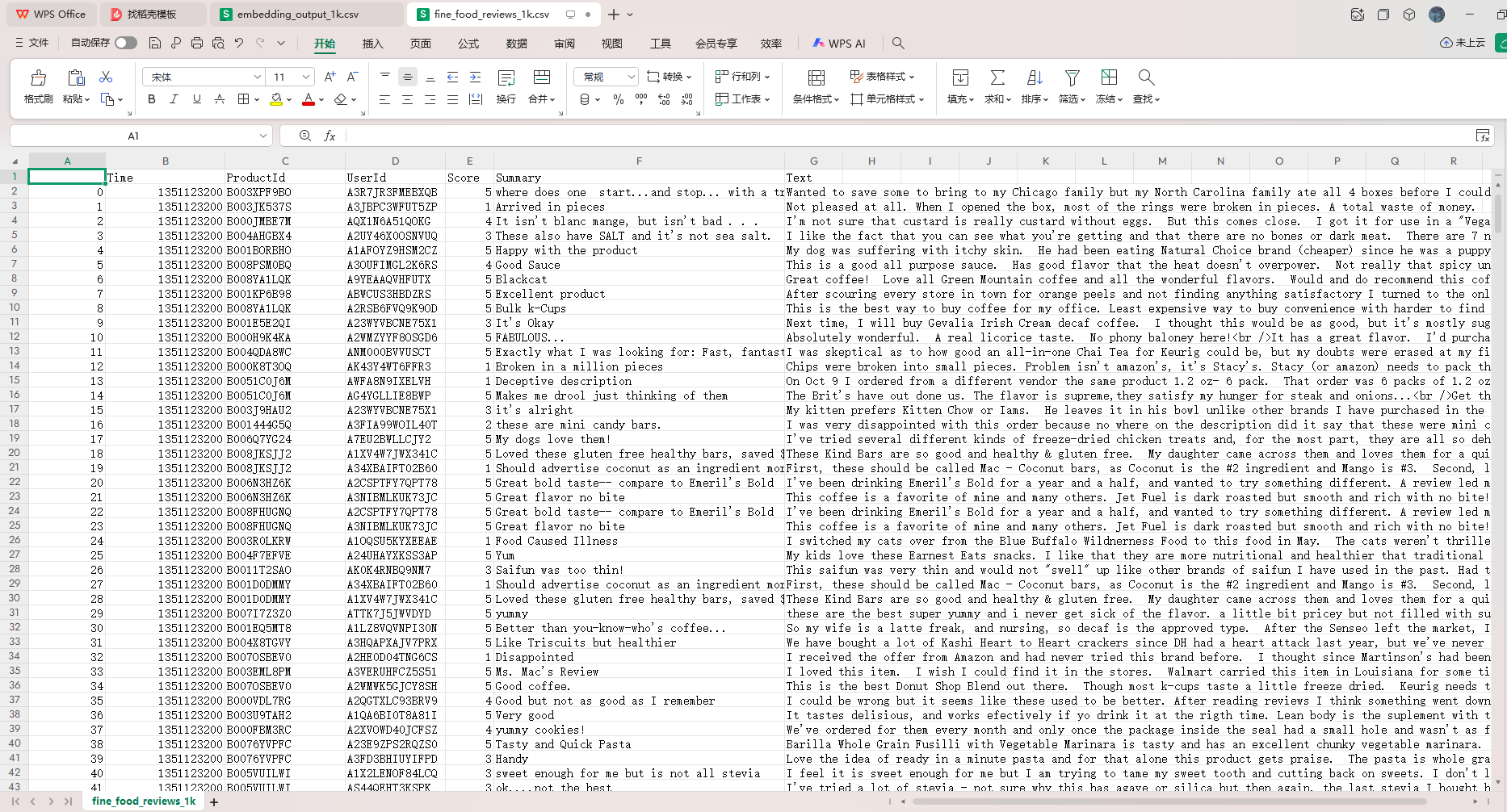
初始文档
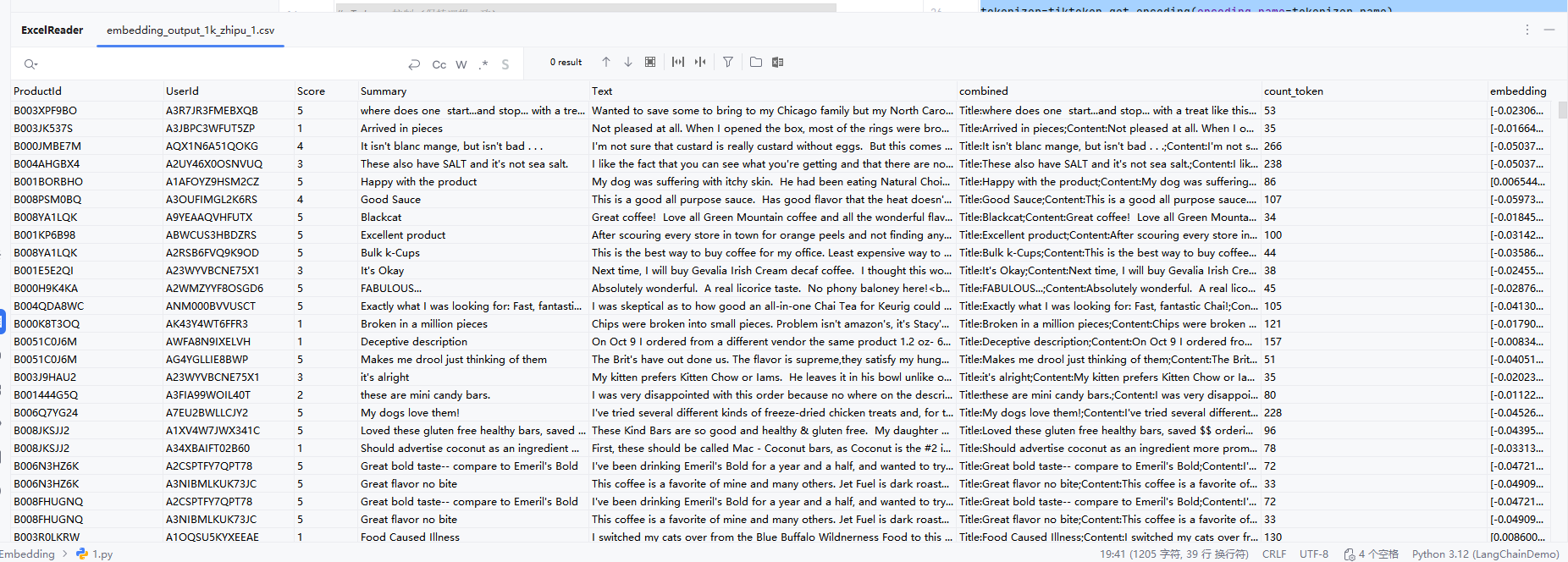
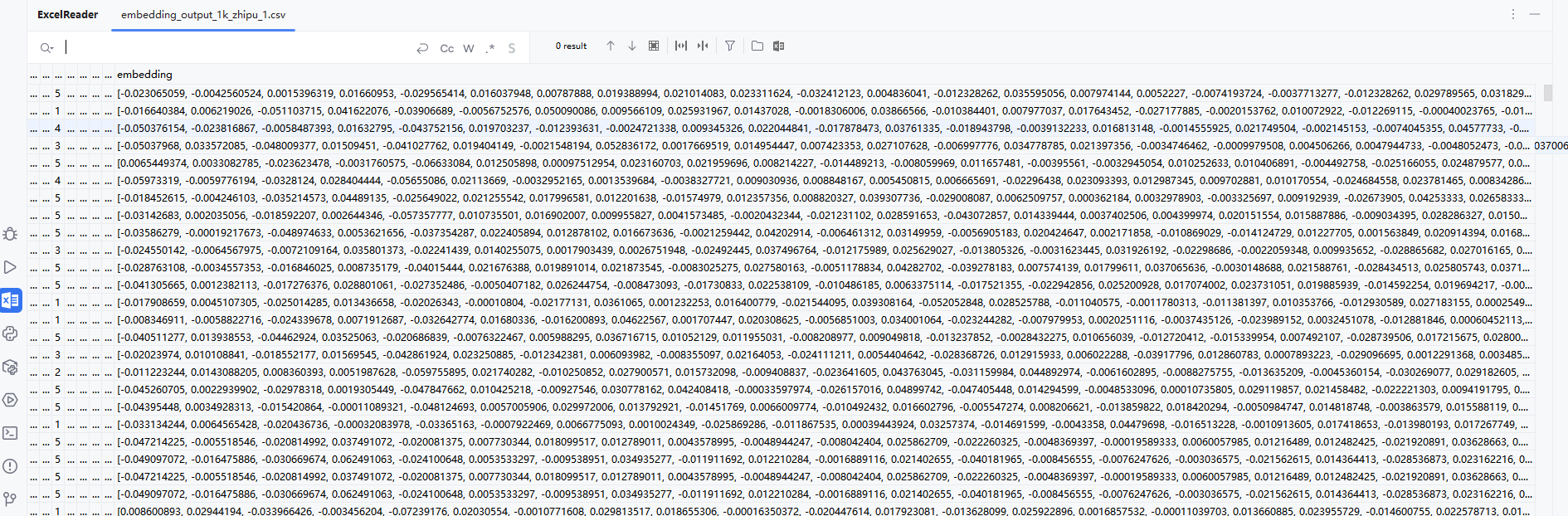
运行后文档

















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









