






在机器学习领域,分类任务是最常见的应用场景之一。无论是图像识别、垃圾邮件过滤,还是疾病诊断,都离不开分类算法的支持。本文将通过一个简单的二维数据分类实例,详细介绍如何使用神经网络完成分类任务,帮助你理解神经网络的工作原理和实现过程。
一、数据生成:构建我们的数据集
为了方便演示,我们首先使用代码生成一个简单的二维数据集。
n_samples = 100
data = torch.randn(n_samples, 2) # 生成 100 个二维数据点
labels = (data[:, 0]**2 +
data[:, 1]**2 < 1).float().unsqueeze(1) # 点在圆内为1,圆外为0上述代码生成了 100 个符合标准正态分布的二维数据点,并且根据这些点是否在单位圆内,为每个点分配了一个标签。如果点在单位圆内,标签为 1;如果点在单位圆外,标签为 0。这就形成了一个简单的二分类数据集。
为了更直观地观察数据分布,我们使用以下代码进行可视化:
plt.scatter(data[:, 0], data[:, 1], c=labels.squeeze(), cmap='coolwarm')
plt.title("Generated Data")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()运行代码后,我们可以看到数据点以不同颜色区分,清晰地展示出在单位圆内和圆外的分布情况。

二、模型构建:搭建神经网络架构
接下来,我们需要定义一个神经网络模型来完成分类任务。这里我们构建了一个简单的前馈神经网络。
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
# 定义神经网络的层
self.fc1 = nn.Linear(2, 4) # 输入层有 2 个特征,隐藏层有 4 个神经元
self.fc2 = nn.Linear(4, 1) # 隐藏层输出到 1 个神经元(用于二分类)
self.sigmoid = nn.Sigmoid() # 二分类激活函数
def forward(self, x):
x = torch.relu(self.fc1(x)) # 使用 ReLU 激活函数
x = self.sigmoid(self.fc2(x)) # 输出层使用 Sigmoid 激活函数
return x 在这个模型中,我们定义了两个全连接层。fc1 层接收二维数据作为输入,并将其映射到包含 4 个神经元的隐藏层;fc2 层则将隐藏层的输出映射到单个神经元,用于输出分类结果。
在 forward 方法中,我们对 fc1 层的输出使用了 ReLU 激活函数,以引入非线性,而 fc2 层的输出则通过 Sigmoid 激活函数,将输出值压缩到 0 到 1 之间,方便我们将其解释为属于某一类别的概率。
三、训练准备:选择损失函数和优化器
在训练模型之前,需要选择合适的损失函数和优化器。
criterion = nn.BCELoss() # 二元交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.1) # 使用随机梯度下降优化器 对于二分类问题,二元交叉熵损失(BCELoss)是一个常用的选择,它能够有效地衡量模型预测概率与真实标签之间的差异。而随机梯度下降(SGD)优化器则通过不断调整模型参数,使损失函数最小化,从而让模型的预测结果更接近真实标签。这里我们设置学习率为 0.1,学习率决定了每次参数更新的步长,过大或过小都可能影响训练效果。
四、模型训练:让神经网络学习分类
有了数据、模型、损失函数和优化器,我们就可以开始训练模型了。
epochs = 1000
for epoch in range(epochs):
# 前向传播
outputs = model(data)
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每 10 轮打印一次损失
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}')在训练过程中,我们进行了 1000 个训练周期(epochs)。每个周期内,首先通过前向传播计算模型的预测输出,并根据预测输出和真实标签计算损失值。然后,通过反向传播计算损失对模型参数的梯度,使用优化器更新模型参数,以减小损失。每隔 10 个周期,我们打印当前的损失值,以便观察模型的训练进度和效果。随着训练的进行,我们可以看到损失值逐渐减小,说明模型在不断学习和优化。
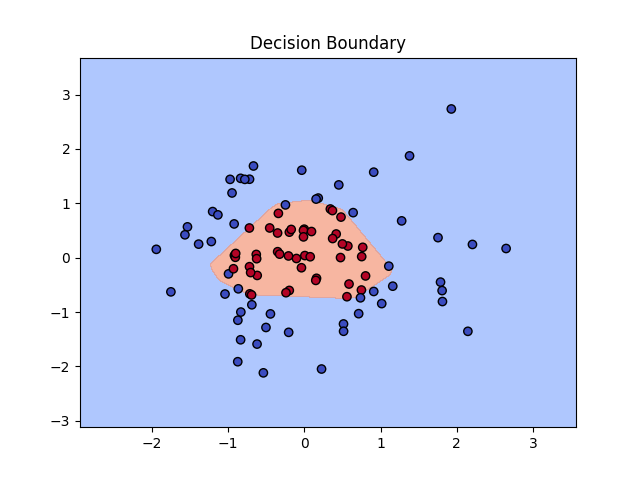
五、结果可视化:展示决策边界
训练完成后,我们可以通过可视化决策边界来直观地展示模型的分类效果。
def plot_decision_boundary(model, data):
x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1
y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1
xx, yy = torch.meshgrid(torch.arange(x_min, x_max, 0.1), torch.arange(y_min, y_max, 0.1), indexing='ij')
grid = torch.cat([xx.reshape(-1, 1), yy.reshape(-1, 1)], dim=1)
predictions = model(grid).detach().numpy().reshape(xx.shape)
plt.contourf(xx, yy, predictions, levels=[0, 0.5, 1], cmap='coolwarm', alpha=0.7)
plt.scatter(data[:, 0], data[:, 1], c=labels.squeeze(), cmap='coolwarm', edgecolors='k')
plt.title("Decision Boundary")
plt.show()
plot_decision_boundary(model, data) 上述代码首先定义了一个函数 plot_decision_boundary ,用于绘制决策边界。通过生成一个二维网格,将网格中的每个点输入到训练好的模型中进行预测,然后根据预测结果绘制等高线图,从而展示出模型的决策边界。结合原始数据点的可视化,我们可以清晰地看到模型是如何对不同区域的数据进行分类的。
六、完整代码
完整代码如下:
#假设有一个二维数据集,目标是根据点的位置将它们分类到两个类别中(例如,红色和蓝色点)。
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# 生成一些随机数据
n_samples = 100
data = torch.randn(n_samples, 2) # 生成 100 个二维数据点
labels = (data[:, 0]**2 +
data[:, 1]**2 < 1).float().unsqueeze(1) # 点在圆内为1,圆外为0
# 可视化数据
plt.scatter(data[:, 0], data[:, 1], c=labels.squeeze(), cmap='coolwarm')
plt.title("Generated Data")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
# 定义前馈神经网络
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
# 定义神经网络的层
self.fc1 = nn.Linear(2, 4) # 输入层有 2 个特征,隐藏层有 4 个神经元
self.fc2 = nn.Linear(4, 1) # 隐藏层输出到 1 个神经元(用于二分类)
self.sigmoid = nn.Sigmoid() # 二分类激活函数
def forward(self, x):
x = torch.relu(self.fc1(x)) # 使用 ReLU 激活函数
x = self.sigmoid(self.fc2(x)) # 输出层使用 Sigmoid 激活函数
return x
# 实例化模型
model = SimpleNN()
# 定义损失函数和优化器
criterion = nn.BCELoss() # 二元交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.1) # 使用随机梯度下降优化器
# 训练
epochs = 1000
for epoch in range(epochs):
# 前向传播
outputs = model(data)
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每 10 轮打印一次损失
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}')
# 可视化决策边界
def plot_decision_boundary(model, data):
x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1
y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1
xx, yy = torch.meshgrid(torch.arange(x_min, x_max, 0.1), torch.arange(y_min, y_max, 0.1), indexing='ij')
grid = torch.cat([xx.reshape(-1, 1), yy.reshape(-1, 1)], dim=1)
predictions = model(grid).detach().numpy().reshape(xx.shape)
plt.contourf(xx, yy, predictions, levels=[0, 0.5, 1], cmap='coolwarm', alpha=0.7)
plt.scatter(data[:, 0], data[:, 1], c=labels.squeeze(), cmap='coolwarm', edgecolors='k')
plt.title("Decision Boundary")
plt.show()
plot_decision_boundary(model, data)七、总结与思考
通过这个二维数据分类的实例,我们完整地展示了从数据生成、模型构建、训练准备、模型训练到结果可视化的整个机器学习流程。虽然这个例子非常简单,但它涵盖了神经网络分类任务的核心步骤和关键概念,方便大家更好的理解分类问题和神经网络。

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









