






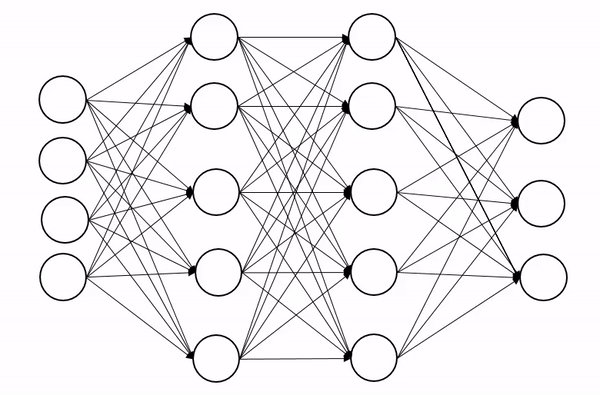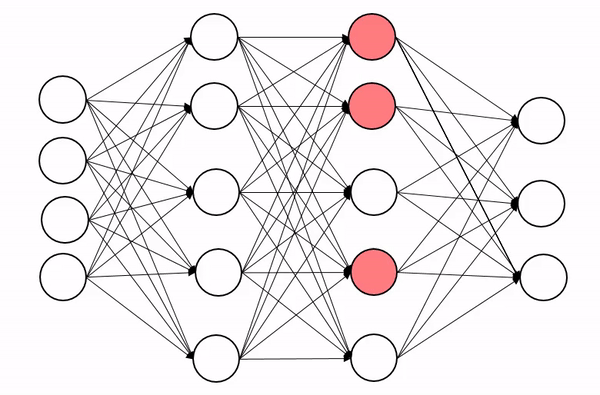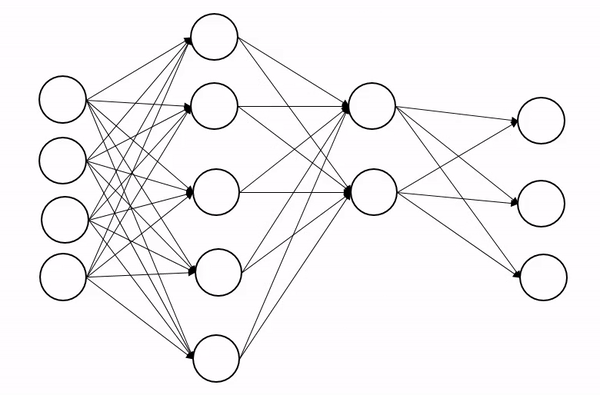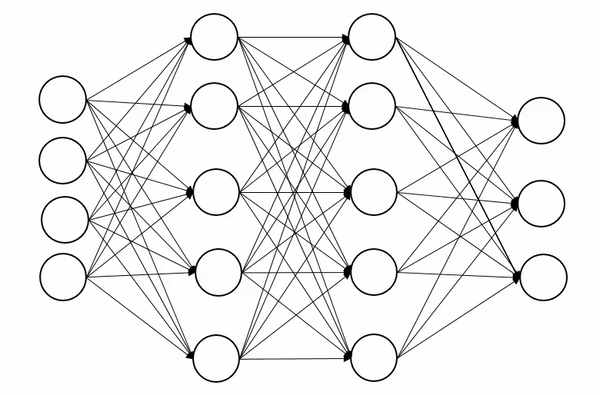
一、Dropout 是什么?
定义:Dropout 是一种正则化技术,通过在训练阶段随机“关闭”(置零)神经网络中的部分神经元,防止模型过拟合。
核心思想:强制网络不依赖某些特定的神经元,从而学习到更鲁棒的特征。
二、为什么需要 Dropout?
过拟合问题:当模型在训练集上表现很好,但在测试集上表现差时,说明模型记住了训练数据的噪声,而非学习通用模式。
神经元协同适应:传统神经网络中,神经元可能过度依赖其他特定神经元,导致模型脆弱。Dropout 通过随机丢弃神经元,打破这种依赖,迫使每个神经元独立学习有用特征。
三、Dropout 的工作原理
1. 训练阶段
随机丢弃:每个神经元以概率
p被保留,以1-p被丢弃(置零)。
举例:
假设某层有 4 个神经元,输入为[0.2, 0.5, 0.8, 1.0],若p=0.5,可能随机保留其中 2 个,输出变为[0.0, 0.5, 0.8, 0.0]。缩放操作:为确保训练和测试时的输出期望一致,保留的神经元值会被放大为原来的
1/(1-p)倍。
数学推导:设原输出期望为 E(x),训练时每个神经元以概率 1−p 被丢弃,保留的神经元值变为 x/(1−p),则期望仍为:
2. 测试阶段
关闭 Dropout:所有神经元均被保留,不做任何丢弃。
无需缩放:由于训练时已通过
1/(1-p)缩放,测试时直接使用原始权重,无需额外调整。
(注:PyTorch 等框架在测试时自动禁用 Dropout,开发者无需手动处理。)四、参数详解:
p(丢弃概率)定义:
p表示神经元被丢弃的概率(注意:PyTorch 中nn.Dropout(p=0.2)表示 20% 的神经元被丢弃,80% 被保留)。取值范围:
0 ≤ p < 1,常见值为0.2~0.5。选择建议:
输入层:
p=0.1~0.2(较少丢弃,避免信息损失过大)。隐藏层:
p=0.5(常用值,平衡正则化与信息保留)。输出层:通常不加 Dropout(保留完整预测能力)。
五、代码详解(PyTorch 实现)
class Net(nn.Module): def __init__(self, input_shape=(3,32,32)): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 32, 3) self.conv2 = nn.Conv2d(32, 64, 3) self.conv3 = nn.Conv2d(64, 128, 3) self.pool = nn.MaxPool2d(2,2) n_size = self._get_conv_output(input_shape) self.fc1 = nn.Linear(n_size, 512) self.fc2 = nn.Linear(512, 10) self.dropout = nn.Dropout(0.25) def forward(self, x): x = self._forward_features(x) x = x.view(x.size(0), -1) x = self.dropout(x) x = F.relu(self.fc1(x)) # Apply dropout x = self.dropout(x) x = self.fc2(x) return x1. 定义 Dropout 层
import torch.nn as nn # 创建 Dropout 层,丢弃概率 p=0.5 dropout = nn.Dropout(p=0.5)参数解释:
p=0.5表示每个神经元有 50% 的概率被丢弃。2. 输入数据
# 模拟输入数据(批量大小=32,特征数=256) x = torch.randn(32, 256) # 形状 [32, 256]输入形状:任意维度,Dropout 会作用在最后一个维度(特征维度)。
3. 前向传播(训练模式)
# 设置为训练模式(启用 Dropout) model.train() output = dropout(x) # 随机丢弃部分神经元并缩放输出示例:假设输入为
[0.2, -0.3, 1.5, 0.7],若第二、第四个神经元被丢弃,输出为[0.4, 0.0, 3.0, 0.0](缩放因子为1/(1-0.5)=2)。4. 测试模式
# 设置为测试模式(关闭 Dropout) model.eval() output = dropout(x) # 直接返回原始输入,无丢弃和缩放框架自动处理:PyTorch 在
eval()模式下会禁用 Dropout。六、数学公式与具体示例
七、使用场景与技巧
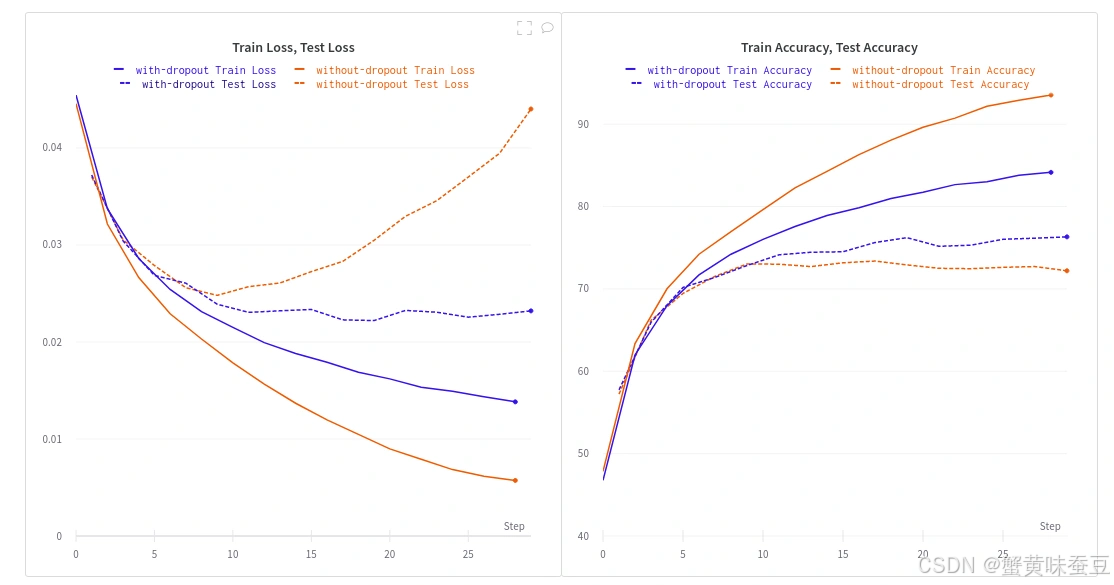
1. 何时使用 Dropout?
模型过拟合时(训练损失持续下降,验证损失停滞或上升)。
网络较深或参数量较大时(如全连接层堆叠)。
2. 使用技巧
位置选择:通常加在激活函数后,下一层线性层前。
例:
Linear → ReLU → Dropout → Linear → ...与 BatchNorm 配合:若网络包含批归一化(BatchNorm),Dropout 可能导致训练不稳定,需谨慎调整学习率。
学习率调整:使用 Dropout 后,可适当增大学习率(因参数更新更稀疏)。
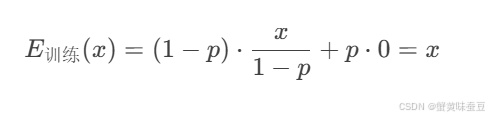




















 4602
4602
评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








