







逻辑回归(Logistic Regression)的本质就是分类问题,决定一个邮件是否是垃圾邮件,根据肿瘤大小确定是良性还是恶性,这是单变量的逻辑回归问题。而邮件自动分类为家庭、工作、生活等分组,以及天气预报确定明天是晴天、多云、阴天等则是多变量的逻辑回归问题。
如果按照线性回归将取得的概率按照一个阈值分类,比如在下面的肿瘤预测中,如粉红色的斜线所示,高于0.5为一类,低于0.5又是另一类,这个看上去线性回归没有什么问题。但是如下图中加入最右的这个特例,如果按照线性回归,假设预测的模型线如蓝色那条直线,如果继续使用0.5为分界线(分界线右移),则会造成原本应该归为右边那一类的样本错误的分到左边来了,这当然是不该发生的。
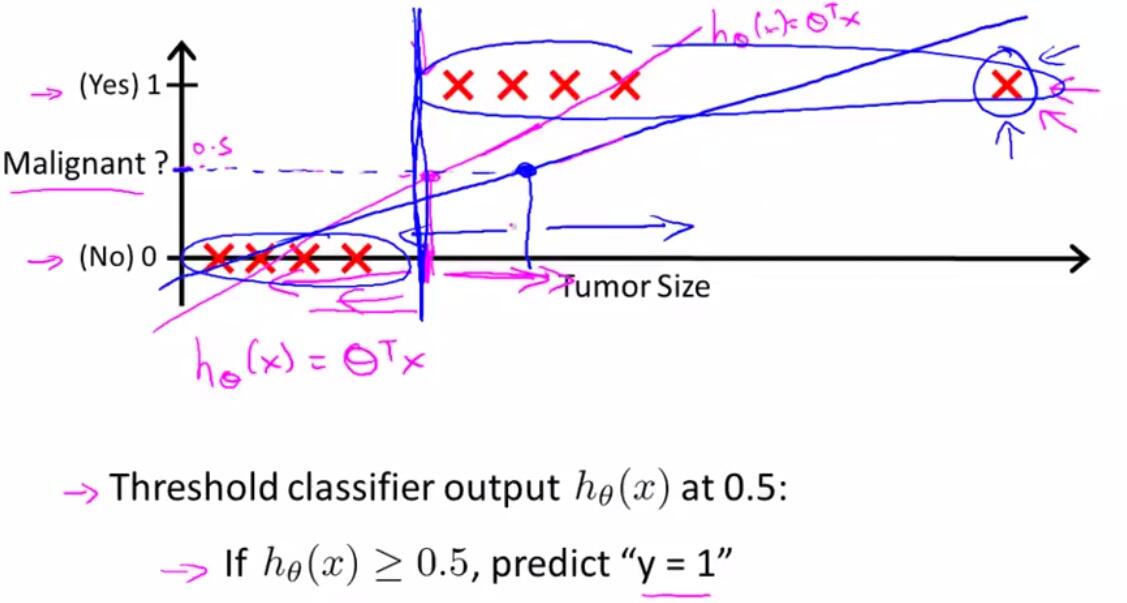
而且假设的h(θ)的范围只在0~1间,线性回归的范围太大,因此引入了新的假设函数(Hypothesis Function)——Sigmoid函数

Decision boundary是用来区分y=0和y=1的边界,它是由Hypothesis function产生。如下面例子
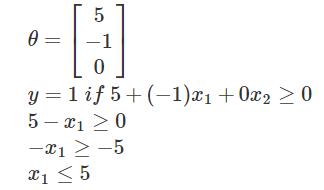
这里的Decision boundary就是x小于等于5的直线,此时有y=1,当x大于5时,y=0。

Cost Function
如果使用线性回归的Cost Function会造成许多局部极大值。

因此它的cost Function如下所示

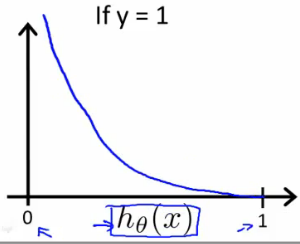
当y=1,J(θ)和hθ(x)如下图
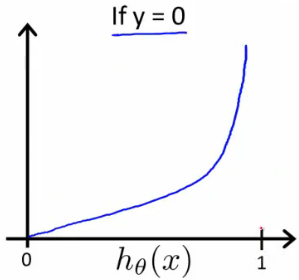

对于y=0,如果假设函数(Hypothesis Function)也输出0,那么cost function的结果也会是0。如果Hypothesis输出接近于1,那么cost function输出趋近于无穷。
对于y=1,如果假设函数(Hypothesis Function)也输出1,那么cost function的结果会是0。如果Hypothesis输出接近于0,那么cost function输出趋近于无穷。
Cost Function分段函数两句合在一起
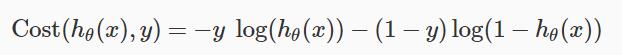
整个J(θ)如下所示
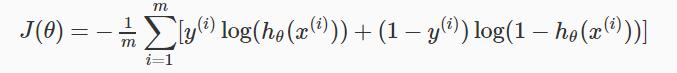
向量化实现如下

Gradient Descent
最初的梯度下降公式为:
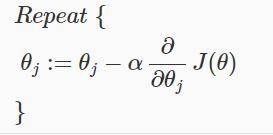
带入微分部分为:

注意需要同时更新所有的θ值
向量化实现如下

关于优化部分

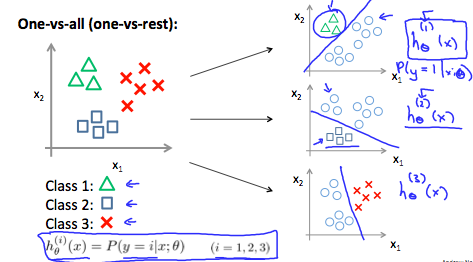
关于多分类
转化为二分类问题
Overfitting 和 Regularlization
Overfitting的含义就是过拟合,也称之为高方差(High Variance),通俗来说就是从样本数据集提取了太多信息,容易造成的后果就是在训练数据集上有较好效果,但是在测试数据集上效果较差,即泛化能力差,模型不具备通用性。

与之对应的为Underfitting欠拟合,也称之为高偏差(High bias),具体表现就是拟合程度不够,离真实数据偏差较大。
如果在Hypothesis Function中存在Overfitting,通过在Cost Function中引入高次项来控制拟合程度
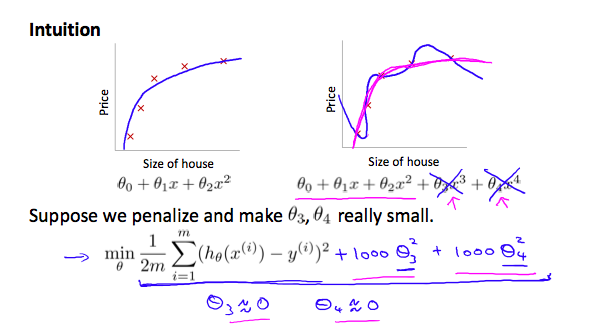
写成一句,如下所示

λ或 lambda称之为正则化参数(regularization parameter),它决定了cost Function中θ的影响力。如果它很大,则cost比较大,表示离真实数据误差较大,容易造成欠拟合,描述不足,模型针对训练数据集就不准确。

针对线性回归、一般方程和逻辑回归都可以使用正则化来控制overfitting


Logistic Regression


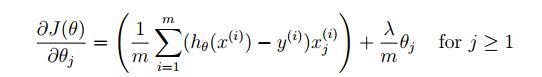

和之前没有Regularlization的时候的对比

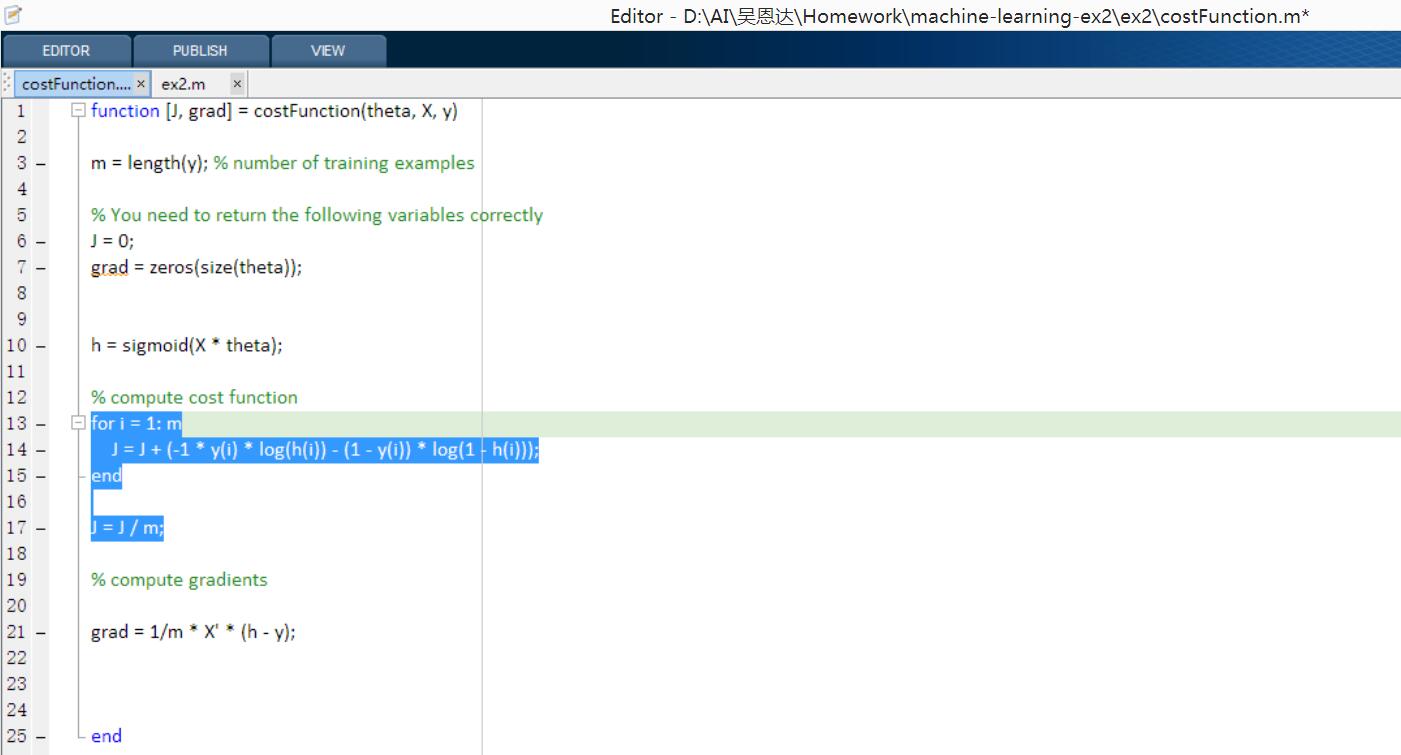
编程作业部分

plotDecisionBoundary.m 这里的直线方程y的求解并不是太理解。它这里取的一个最大的和最小的x然后两点确定直线
% Calculate the decision boundary line
% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% ax + by + c = 0
% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% theta(2)x + theta(3) y + theta(1) = 0
plot_y = (-1./theta(3)).*(theta(2).*plot_x + theta(1));

这个问题并未想清楚,如果有知道的朋友欢迎在下面留言。
而且后面的另外一个ex2_reg.m中也用到了这个函数,根据最后的图片你会发现Desion Boundary并不是很好,是不是也跟这个有关。(选取最小和最大值,确定一条直线)
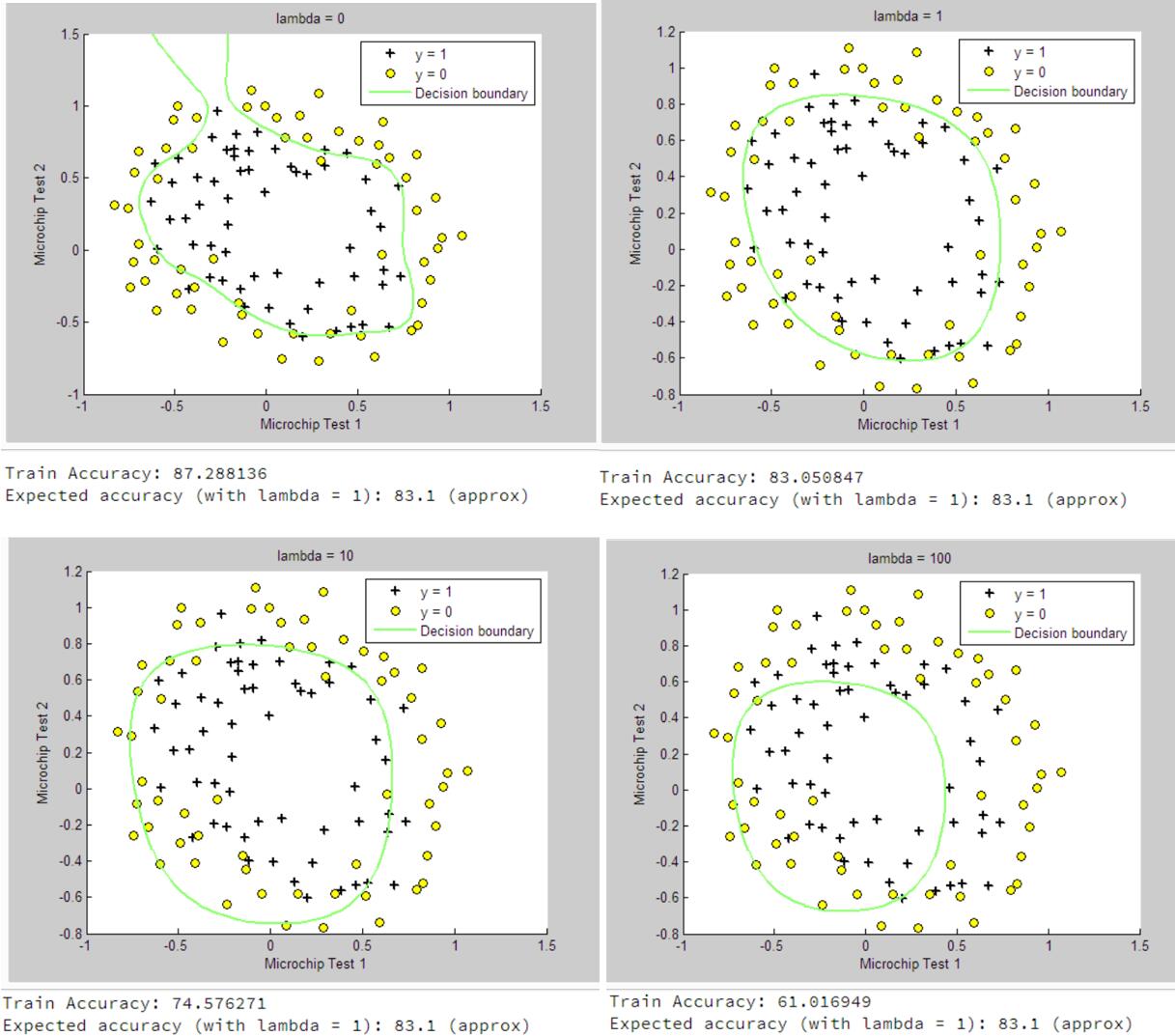
根据上面的四幅图可以看到,随着lambda的变大,Desion boundary的效果越来越差,Underfitting。而lambda为0的时候,相当于没有进行regularlization,Desion boundary有较好效果,但是函数复杂,易造成Overfitting
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











