






SHAP(SHapley Additive exPlanations)是一种用于解释模型预测结果的特征重要性评估方法。它基于合作博弈理论中的 Shapley 值概念,将每个输入特征对于模型预测输出的贡献度进行量化。
在神经网络下,SHAP 的计算原理如下:
- 首先,选择一个基准值(例如全局平均值或者零向量),作为输入特征的参考点。
- 对于每个输入样本,通过遍历所有可能的特征子集来计算每个特征的 Shapley 值。该过程称为特征交互迭代(Feature Interaction Iteration)。
- 在每次特征交互迭代中,依次加入一个特征,并计算加入特征后的模型预测输出与不加入该特征时的预测输出之间的差异(贡献)。
- 通过对所有可能的特征子集进行加权平均来计算每个特征的 Shapley 值,这些权重符合合作博弈理论中的 Shapley 值定义。
- 最后,得到每个特征的 Shapley 值,用于衡量该特征对于模型预测输出的贡献度,从而得到特征的重要性评估。
SHAP 值的计算过程相对复杂,需要遍历特征子集并进行差分计算。但是它提供了一种全局解释模型预测的方法,可以帮助理解神经网络中每个输入特征对于预测结果的影响程度。
通过使用 SHAP 软件包提供的 DeepExplainer 类,我们可以方便地在 Keras 神经网络中计算 SHAP 值,并可视化特征的重要性。这样可以帮助我们更好地理解神经网络的决策过程和各个输入特征的相对贡献。
首先,需要安装 shap 库:
pip install shap
接下来,我们可以通过以下步骤来计算特征的重要性:
- 训练模型并准备输入数据。
- 使用 SHAP 值解释器来解释模型的预测结果。
- 使用 SHAP 的
summary_plot或其他可视化方法来展示特征的重要性。
下面是一个示例代码:
import numpy as np
import shap
import tensorflow as tf
from tensorflow import keras
# 准备训练数据和标签
(x_train, y_train), (_, _) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(-1, 784).astype('float32') / 255.0
# 构建并编译模型
model = keras.Sequential([
keras.layers.Dense(64, activation='relu', input_shape=(784,)),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=5)
# 创建一个 SHAP 解释器,并计算 SHAP 值
explainer = shap.DeepExplainer(model, x_train[:100])
shap_values = explainer.shap_values(x_train[100:110])
# 可视化特征重要性
shap.summary_plot(shap_values, x_train[100:110], feature_names=range(784))
最终绘图结果如下:
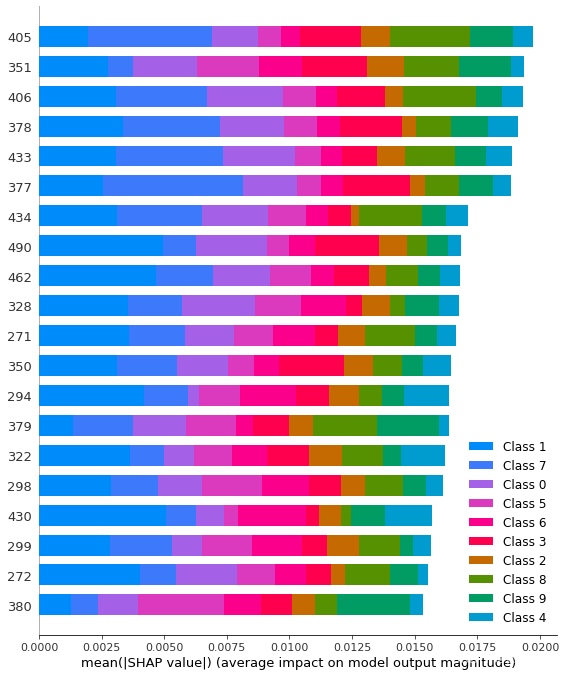
因为举例的数据是手写数据集案例,左边坐标轴相当于784像素点中的某个点对分类的重要性影响!
















 1271
1271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











