







自动驾驶汽车让我感到恐惧。这些巨大的金属块在没有人类干预的情况下四处飞驰,如果出现问题,没有人能够制止它们。为了降低这种风险,仅仅评估驱动这些汽车的模型是不够的。我们还需要了解它们是如何进行预测的。这是为了避免任何可能导致意外事故的边缘情况。
好吧,我们的应用程序并不那么重要。我们将调试用于驱动小型自动驾驶汽车的模型(你所能期望的最糟糕的情况可能只是扭伤了脚踝)。不过,IML方法可能会有所帮助。我们将看看它们如何甚至可以改善模型的性能。
具体来说,我们将:
使用PyTorch和图像数据以及连续目标变量对ResNet-18进行微调。
使用均方误差(MSE)和散点图来评估模型。
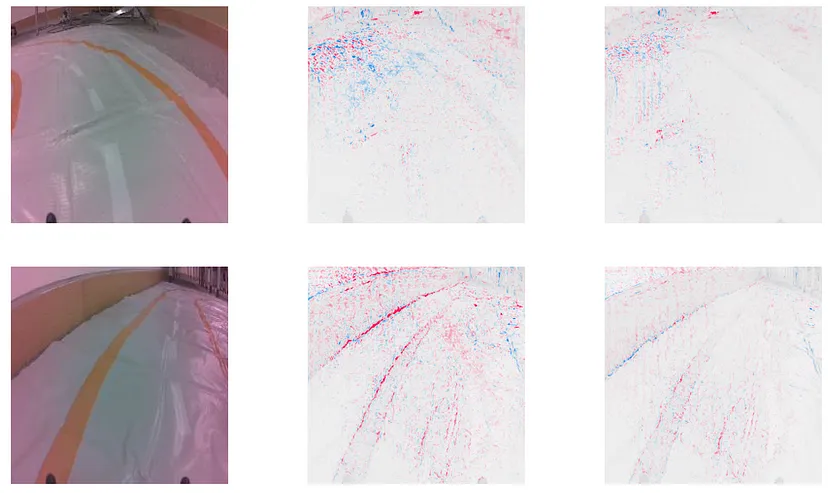
使用DeepSHAP解释模型。
通过更好的数据收集来校正模型。
探讨图像增强如何进一步改善模型。
在这个过程中,我们将讨论一些关键的Python代码片段。你还可以在GitHub上找到完整的项目。
如果你对SHAP不熟悉,那么请看下面的视频。如果你想了解更多,请参加我的SHAP课程。如果你订阅我的新闻通讯,你可以免费获得访问权限 :)
https://youtu.be/L8_sVRhBDLU
Python软件包
# Imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import glob
import random
from PIL import Image
import cv2
import torch
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
import shap
from sklearn.metrics import mean_squared_error数据集
我们从仅在一个房间内收集数据开始(这将会给我们带来麻烦)。如前所述,我们使用图像来驱动一辆自动驾驶汽车。你可以在Kaggle上找到这些图像的示例。这些图像都是224 x 224像素。
我们使用下面的代码显示其中一个图像。请注意图像的名称(第2行)。前两个数字是在224 x 224框架内的x和y坐标。在图1中,你可以看到我们使用绿色圆圈(第8行)显示了这些坐标。
#Load example image
name = "32_50_c78164b4-40d2-11ed-a47b-a46bb6070c92.jpg"
x = int(name.split("_")[0])
y = int(name.split("_")[1])
img = Image.open("../data/room_1/" + name)
img = np.array(img)
cv2.circle(img, (x, y), 8, (0, 255, 0), 3)
plt.imshow(img)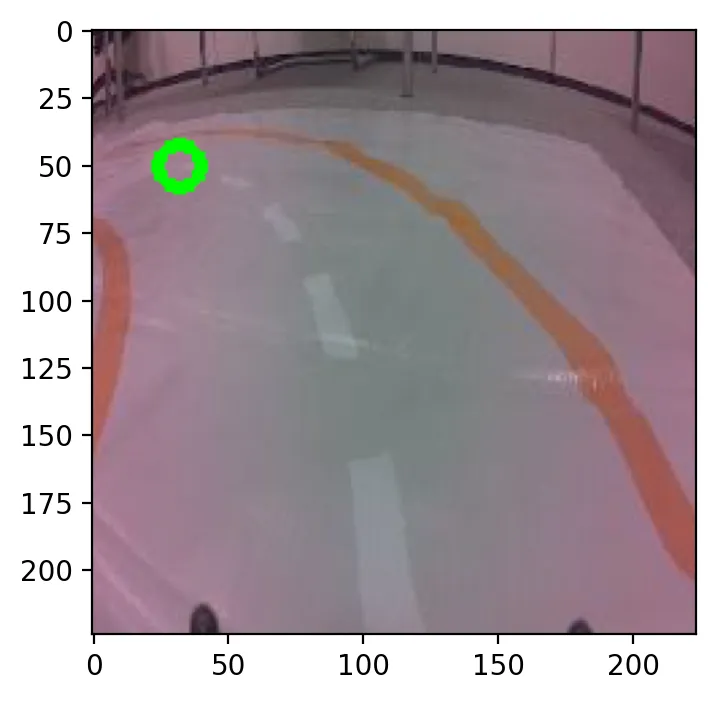
这些坐标是目标变量。模型使用图像作为输入来预测它们。然后,这个预测值用于控制汽车。在这种情况下,你可以看到汽车即将转向左边。理想的方向是朝着绿色圆圈给出的坐标前进。
训练PyTorch模型
我想重点介绍SHAP,所以我们不会深入研究建模代码。如果你有任何问题,请随时在评论中提问。
我们首先创建ImageDataset类。这个类用于加载我们的图像数据和目标变量。它使用图像的路径来完成这个任务。需要指出的一件事是目标变量是如何缩放的 —— x和y都将在-1到1之间。
class ImageDataset(torch.utils.data.Dataset):
def __init__(self, paths, transform):
self.transform = transform
self.paths = paths
def __getitem__(self, idx):
"""Get image and target (x, y) coordinates"""
# Read image
path = self.paths[idx]
image = cv2.imread(path, cv2.IMREAD_COLOR)
image = Image.fromarray(image)
# Transform image
image = self.transform(image)
# Get target
target = self.get_target(path)
target = torch.Tensor(target)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2510
2510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









