







本文深入探讨了基于深度学习的恶意软件检测系统的开发与实现。通过分析Windows可执行程序的API调用序列,利用长短期记忆网络(LSTM)构建高效检测模型。系统采用模块化设计,涵盖数据处理、特征工程、模型训练及结果可视化,并通过GPU加速和多线程技术优化性能,提供流畅的用户交互体验。
一、引言
恶意软件检测是网络安全领域的关键任务。传统方法在面对新型恶意软件时存在局限性,而深度学习技术凭借其强大的模式识别能力,为恶意软件检测提供了新的解决方案。本文将详细介绍一个基于深度学习的恶意软件检测系统的开发过程,分享技术实现细节和实践经验。
二、系统设计与技术选型
2.1 整体架构
系统采用分层架构,包括数据获取与预处理层、特征工程层、模型构建与训练层以及结果展示与交互层。这种分层设计有助于各部分的独立开发与优化,同时便于后续的扩展与维护。
2.2 技术栈选择
-
深度学习框架:TensorFlow因其广泛的社区支持和强大的功能成为首选。
-
GUI开发:PyQt5提供了丰富的组件和布局管理器,适合构建跨平台的桌面应用。
-
数据处理:Pandas和NumPy是Python中处理结构化数据和数值计算的常用库。
-
可视化:Matplotlib和Seaborn用于生成各类统计图表,辅助数据分析和结果展示。
三、核心功能模块详解
3.1 数据获取与预处理
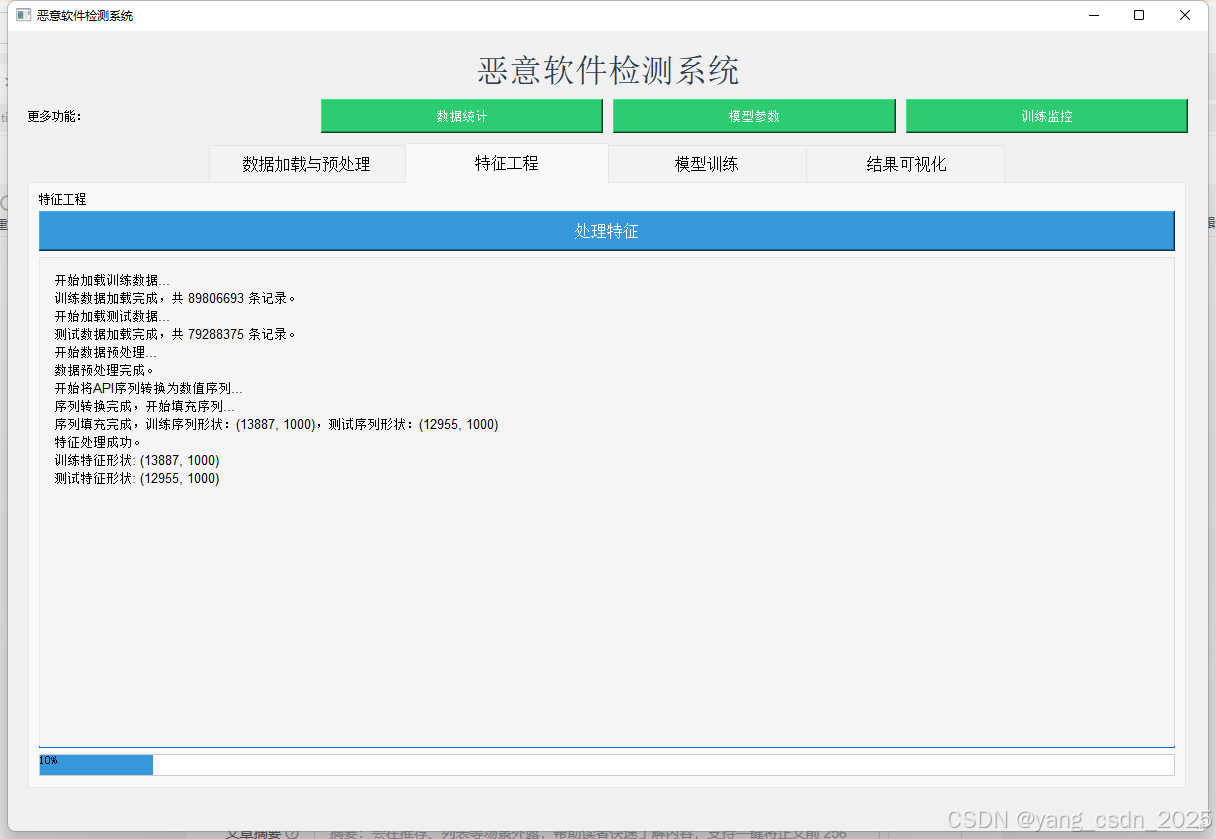
系统从阿里云安全恶意程序检测数据集获取数据,该数据集包含大量正常程序和恶意软件的API调用序列。数据预处理模块负责清洗数据、提取关键特征,并将API序列转换为适合深度学习模型输入的格式。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as snsdef load_and_preprocess_data(train_path, test_path, info_callback=None):
# 加载训练数据
if info_callback:
info_callback("开始加载训练数据...")
train_data = pd.read_csv(train_path)
if info_callback:
info_callback(f"训练数据加载完成,共 {len(train_data)} 条记录。")
# 加载测试数据
if info_callback:
info_callback("开始加载测试数据...")
test_data = pd.read_csv(test_path)
if info_callback:
info_callback(f"测试数据加载完成,共 {len(test_data)} 条记录。")
# 数据预处理
if info_callback:
info_callback("开始数据预处理...")
# 将API序列转换为文本形式,方便后续处理
train_data['api_sequence'] = train_data.groupby(['file_id', 'tid'])['api'].transform(lambda x: ' '.join(x))
# 去除重复的file_id行,保留每个文件的API序列
train_data = train_data.drop_duplicates(subset=['file_id']).reset_index(drop=True)
# 提取特征和标签
X_train = train_data['api_sequence']
y_train = train_data['label']
# 测试数据预处理
test_data['api_sequence'] = test_data.groupby(['file_id', 'tid'])['api'].transform(lambda x: ' '.join(x))
test_data = test_data.drop_duplicates(subset=['file_id']).reset_index(drop=True)
# 提取测试特征
X_test = test_data['api_sequence']
if info_callback:
info_callback("数据预处理完成。")
return X_train, y_train, X_test, test_data
3.2 特征工程与序列处理
考虑到API调用序列的长度可能远超常规文本数据,系统采用了截断策略,确保每个文件的API序列长度控制在预设范围内。同时,利用Tokenizer将API名称转换为整数索引,形成模型可处理的数值型序列数据。
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import matplotlib.pyplot as pltdef text_to_sequence(X_train, X_test, max_sequence_length=1000, num_words=10000, info_callback=None):
if info_callback:
info_callback("开始将API序列转换为数值序列...")
tokenizer = Tokenizer(num_words=num_words)
tokenizer.fit_on_texts(X_train)
X_train_sequences = tokenizer.texts_to_sequences(X_train)
X_test_sequences = tokenizer.texts_to_sequences(X_test)
if info_callback:
info_callback("序列转换完成,开始填充序列...")
X_train_padded = pad_sequences(X_train_sequences, maxlen=max_sequence_length)
X_test_padded = pad_sequences(X_test_sequences, maxlen=max_sequence_length)
if info_callback:
info_callback(f"序列填充完成,训练序列形状:{X_train_padded.shape},测试序列形状:{X_test_padded.shape}")
return X_train_p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









