




文章目录

Pre
大模型开发 - 03 QuickStart_借助DeepSeekChatModel实现Spring AI 集成 DeepSeek
大模型开发 - 04 QuickStart_DeepSeek 模型调用流程源码解析:从 Prompt 到远程请求
大模型开发 - 05 QuickStart_接入阿里百炼平台:Spring AI Alibaba 与 DashScope SDK
大模型开发 - 06 QuickStart_本地大模型私有化部署实战:Ollama + Spring AI 全栈指南
大模型开发 - 07 ChatClient:构建统一、优雅的大模型交互接口
大模型开发 - 08 ChatClient:构建智能对话应用的流畅 API
大模型开发 - 09 ChatClient:基于 Spring AI 的多平台多模型动态切换实战
大模型开发 - 10 ChatClient:Advisors API 构建可插拔、可组合的智能对话增强体系
大模型开发 - 11 ChatClient:Advisor 机制详解:拦截、增强与自定义 AI 对话流程
大模型开发 - 12 Prompt:Spring AI 中的提示(Prompt)系统详解_从基础概念到高级工程实践
大模型开发 - 13 Prompt:提示词工程实战指南_Spring AI 中的提示设计、模板化与最佳实践
大模型开发 - 14 Chat Memory:实现跨轮次对话上下文管理
大模型开发 - 15 Tool Calling :从入门到实战,一步步构建智能Agent系统
大模型开发 - 16 Chat Memory:借助 ChatMemory + PromptChatMemoryAdvisor轻松实现大模型多轮对话记忆
大模型开发 - 17 Structured Output Converter:结构化输出转换器_从文本到结构化数据的可靠桥梁
大模型开发 - 18 Chat Memory:集成 JdbcChatMemoryRepository 实现大模型多轮对话记忆
大模型开发 - 19 Chat Memory:集成 BaseRedisChatMemoryRepository实现大模型多轮对话记忆
大模型开发 - 20 Chat Memory:多层次记忆架构_突破大模型对话中的 Token 上限瓶颈
大模型开发 - 21 Structured Output Converter:结构化输出功能实战指南
大模型开发 - 22 Multimodality API:多模态大模型与 Spring AI 的融合
大模型开发 - 23 Chat Model API:深入解析 Spring AI Chat Model API_构建统一、灵活、可扩展的 AI 对话系统
大模型开发 - 24 Embeddings Model API:深入解析 Spring AI Embeddings Model API_构建语义理解的基石
大模型开发 - 25 Image Model API:深入解析 Spring AI Image Model API_构建统一、灵活的 AI 图像生成系统
大模型开发 - 26 Origin Tools: Spring AI 结构化多聊天客户端实战
大模型开发 - 27 Tool Calling:Spring AI 中的工具调用指南
大模型开发 - 28 Tool Calling:Spring AI 工具调用执行外部操作实战
大模型开发 - 29 Tool Calling:大模型与业务系统集成的利器 _Tool Calling 实战指南
大模型开发 - 30 Tool Calling:Spring AI Tool Calling 工作原理及源码详解
大模型开发 - 31 Tool Calling:解决大模型“工具选择困难症”_基于 RAG 的动态工具加载方案解读
大模型开发 - 32 Tool Calling:Spring AI 工具调用最佳实践完整指南
大模型开发 - 33 MCP:深入理解 Model Context Protocol(MCP)及其在 Spring AI 中的实践指南
大模型开发 - 34 MCP:Spring AI MCP 客户端启动器(MCP Client Boot Starter)深度指南
大模型开发 - 35 MCP:Spring AI MCP 服务端启动器(MCP Server Boot Starter)完全指南
大模型开发 - 36 MCP:深入理解 MCP Utilities :同步与异步工具回调
大模型开发 - 37 RAG:Retrieval Augmented Generation(RAG)详解与实战指南
概述
最近,Anthropic 发布了一份关于如何构建高效 AI 智能体的文档,为开发者提出了一些实用的智能体模式和最佳实践。虽然 Anthropic 推崇轻量级模式来取代复杂框架,但在 Java 生态下,大型框架如 Spring 被广泛采用。
Spring 虽然体系庞大,但通过 Spring AI 提供了简洁高效的智能体开发工具。
本教程将梳理 Anthropic 提出的智能体设计模式及核心定义,并使用 Spring AI 展示每种模式的代码实现。重点放在模式的实现方法,而非具体模型宿主的集成细节。
智能体的定义与基础模式
Anthropic 总结了多种简单且可组合的智能体开发模式。首先明确两大核心概念:
- Agents(智能体):由大语言模型(LLM)驱动,能够自主控制流程及工具调用,动态完成任务。
- Workflows(工作流):通过预设的代码路径编排 LLM 及其工具,实现任务流程。
基于此,常见的智能体模式包括:
- Prompt 链式工作流(Prompt Chaining Workflow):将复杂任务拆解为多个步骤,每一步输出作为下一步的输入。
- 并行化工作流(Parallelization Workflow):多个独立操作并行执行,最后汇总结果。
- 路由工作流(Routing Workflow):根据内容分类,将输入智能分发给不同的专用处理器。
- 编排-工作者模式(Orchestrator-Workers Workflow):主控 LLM 分解任务,分派给多个工作者 LLM,最终合并各自结果。
- 评估-优化模式(Evaluator-Optimizer Workflow):一个 LLM 提出方案,另一个 LLM循环评估与优化,反复迭代直至满意。
依赖配置
我们只采纳基础依赖,不引入如 spring-ai-ollama-spring-boot-starter 这样的模型实现,代码以接口为基础:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-model</artifactId>
<version>1.0.2</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-client-chat</artifactId>
<version>1.0.2</version>
</dependency>
通过 Model 和 ChatModel 接口即可打造 Spring AI 智能体,ChatClient 现在也是主流选择。
Chain Workflow Agents 链式工作流智能体
链式工作流非常适合将任务分解为连续的子任务的情况。每个子任务的结果将传递给下一个子任务。我们也有机会在子任务之间添加一些代码,用于决策或更改。
当任务可拆分为一系列顺序子任务时,链式模式适用。每步结果作为下一步输入,过程中可添加逻辑判定。
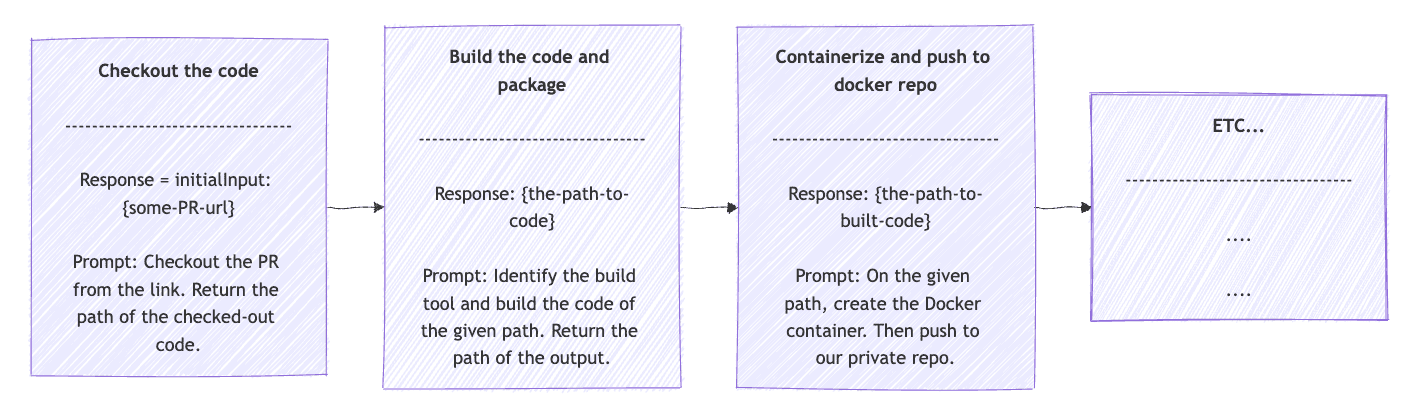
以 CI/CD 构建流水线为例,可以依次拆解为:
- 从 VCS 检出代码
- 构建并打包
- 制作容器镜像并推送到 Docker 仓库
- 部署到测试环境
- 运行集成测试
假设有一个扩展自 ChatClient 的 OpsClient 接口,实现如下:
public String opsPipeline(String userInput) {
String response = userInput;
for (String prompt : OpsClientPrompts.DEV_PIPELINE_STEPS) {
String request = String.format("%s\n%s", prompt, response);
ChatClient.ChatClientRequestSpec requestSpec = opsClient.prompt(request);
ChatClient.CallResponseSpec responseSpec = requestSpec.call();
response = responseSpec.content();
if (response.startsWith("ERROR:")) { break; }
}
return response;
}
每一步的 Prompt 都更具体,比如 “从指定 URL 检出代码,返回本地路径或错误信息”。每轮 response 作为下轮 prompt 的输入,初值为用户输入,遇错误则中断。
首先,我们在 for 循环中使用 OpsClientPrompts.DEV_PIPELINE_STEPS 。这些步骤比前面提到的步骤更具描述性。例如,对于从 VCS 检出,它会类似于“从给定的 URL 检出代码。返回检出代码的路径,否则发生错误”。
在链式模式中,每个响应都会作为后续步骤的输入。因此, 请求字段的作用正是如此。给定下一步的提示和上一步的响应,创建请求作为 prompt() 方法的参数,该方法将使用 call() 方法执行。结果存储在响应中,以供下一步使用。初始响应值将是用户输入。最后,在步骤之间,我们添加一个 if 子句,用于在出现错误时中断循环。链式工作流应如下所示:
Parallelization Workflow Agents 并行化工作流智能体
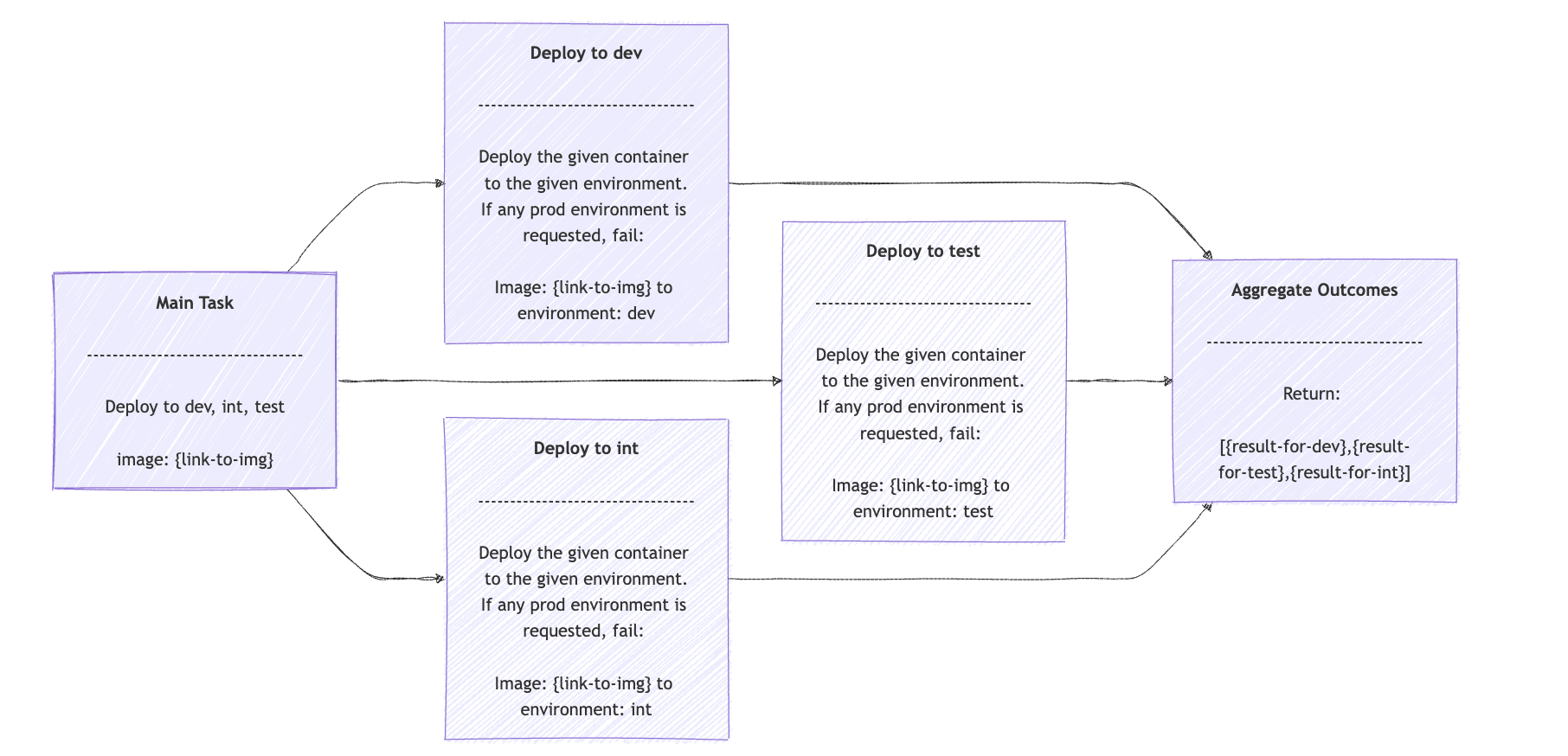
并行化工作流非常适合将任务分解为可并行执行的独立子任务的情况。这些子任务的结果将以编程方式聚合为单个结果。
当任务可并行拆分为若干子任务,并可聚合结果时,采用并行模式。例如,一次性将新镜像部署到测试、开发、集成等多个环境,并校验部门部署准则。
可以利用 Java 的 ExecutorService + CompletableFuture:
public List<String> opsDeployments(String containerLink, List<String> environments, int maxConcurentWorkers) {
try (ExecutorService executor = Executors.newFixedThreadPool(maxConcurentWorkers)) {
List<CompletableFuture<String>> futures = environments.stream()
.map(env -> CompletableFuture.supplyAsync(() -> {
String request = OpsClientPrompts.NON_PROD_DEPLOYMENT_PROMPT
+ "\nImage: " + containerLink
+ " to environment: " + env;
ChatClient.ChatClientRequestSpec requestSpec = opsClient.prompt(request);
ChatClient.CallResponseSpec responseSpec = requestSpec.call();
return responseSpec.content();
}, executor))
.toList();
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
return futures.stream().map(CompletableFuture::join).collect(Collectors.toList());
}
}
方法接受镜像链接、目标环境列表、并发线程数,通过流将部署任务拆分执行,最后收集各自结果。
opsDeployments() 方法接受指向包含待部署镜像的容器的链接、目标环境以及最大并发工作线程数。然后,我们使用流将任务分解为每个给定环境的一个部署任务。
每个请求字段都是部署的提示符(在我们的例子中是 OpsClientPrompts.NON_PROD_DEPLOYMENT_PROMPT ) 、 容器链接以及具体的环境变量。结果只是一个包含每个结果的数组。并行化工作流应该如下所示:
Routing Workflow Agents 路由工作流智能体
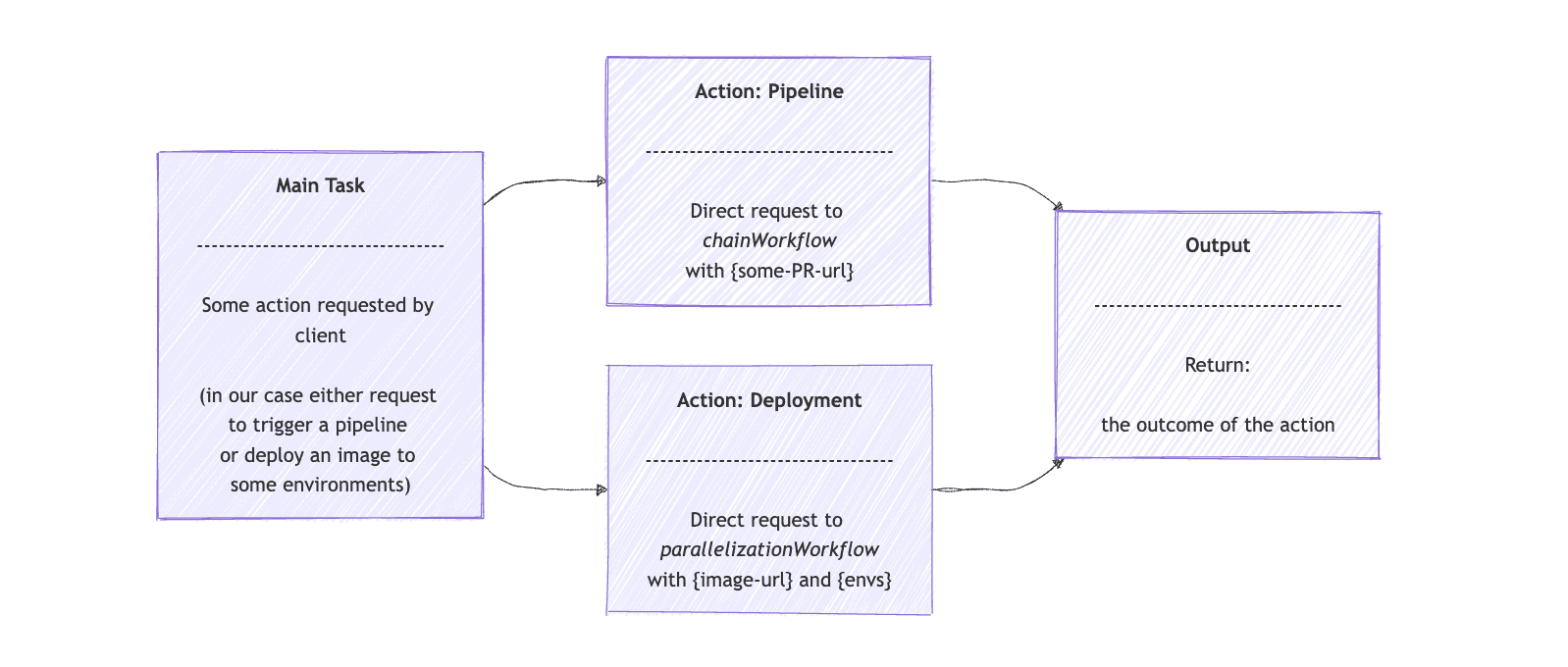
当我们想要将任务分配给更专业的 AI 模型时,路由工作流 (Routing Workflow) 非常适用 。一个很好的例子是,LLM 充当客户服务支持,接收客户输入,然后将任务重定向到技术支持模型、客户服务模型等。客户无需知道存在多个模型。相反,使用通用的模型作为路由工作流即可。
当任务需根据输入智能分发到不同模型处理时,采用路由模式。如客服 AI 根据内容转发给技术或账户支持模型。
继续 DevOps 场景,可实现通用 Smart DevOps Agent,根据需求分发到构建或部署流程:
首先,我们使用扩展了 ChatClient 的 opsRoutingClient 接口。我们向客户端提供路由选项和用户输入。然后,我们要求它将请求路由到 ChainWorkflow 或 ParallelizationWorkflow ,就像本文前面实现的那样:
public class RoutingWorkflow {
private final OpsRouterClient opsRouterClient;
private final ChainWorkflow chainWorkflow;
private final ParallelizationWorkflow parallelizationWorkflow;
public String route(String input) {
String[] route = determineRoute(input, OPS_ROUTING_OPTIONS);
String opsOperation = route[0];
List<String> requestValues = route[1].lines().toList();
return switch (opsOperation) {
case "pipeline" -> chainWorkflow.opsPipeline(requestValues.getFirst());
case "deployment" -> executeDeployment(requestValues);
default -> throw new IllegalStateException("Unexpected value: " + opsOperation);
};
}
private String[] determineRoute(String input, Map<String, String> availableRoutes) {
String request = String.format("""
Given this map that provides the ops operation as key and the description for you to build the operation value, as value: %s.
Analyze the input and select the most appropriate operation. Return an array of two strings. First string is the operations decided and second is the value you built based on the operation.
Input: %s
""", availableRoutes, input);
ChatClient.ChatClientRequestSpec requestSpec = opsRouterClient.prompt(request);
ChatClient.CallResponseSpec responseSpec = requestSpec.call();
return responseSpec.entity(String[].class);
}
private String executeDeployment(List<String> requestValues) {
String containerLink = requestValues.getFirst();
List<String> environments = Arrays.asList(requestValues.get(1).split(","));
int maxWorkers = Integer.parseInt(requestValues.getLast());
List<String> results = parallelizationWorkflow.opsDeployments(containerLink, environments, maxWorkers);
return String.join(", ", results);
}
}
根据用户输入利用路由,智能决策选择构建还是部署流程。
route() 方法首先确定要使用的专用任务,要么是 pipeline ,要么是 deployment 。 路由数组将包含操作以及 opsRouterClient 返回的提示。然后,如果操作是“ pipeline ”,它将直接将请求发送到 chainWorkflow 。如果操作是“ deployment ”,则 executeDeployment() 方法会准备请求并将其发送到 parallelizationWorkflow 代理。
对于路由工作流模式,使用 Spring AI 的有效代理的图形表示如下:
Orchestrator Workers Agents 编排-工作者模式智能体
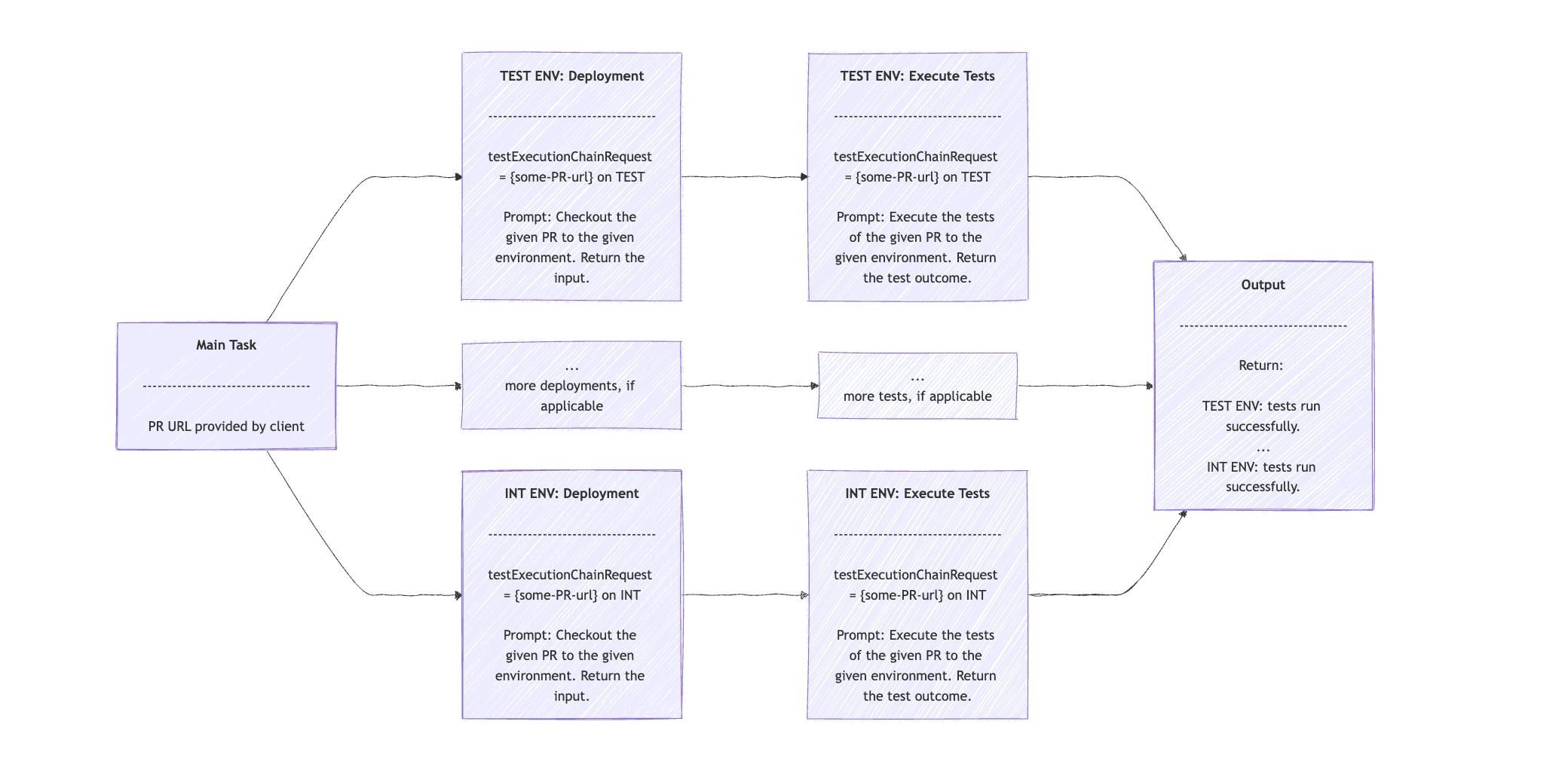
当我们有一个复杂的任务,可以分解成更简单的子任务,但又无法预先预测它们会是哪些时,Orchestrator Workers 工作流是最佳选择。Orchestrator Agent 会将子任务委托给 Worker Agent。最后,它会收集结果,并最终生成初始任务的最终结果。
遇到复杂任务需动态拆解为更细致子任务,并由主控智能体分配给多个子智能体分别完成,再聚合结果时,应用本模式。
如 DevOps 场景,主控智能体根据 PR 链接分析变更范围,决策测试环境种类,然后分派部署和测试指令:
假设我们有一个 OpsOrchestratorClient 类,它扩展了 ChatClient 。我们可以提供一个描述此案例和 PR 链接的提示,并要求它返回我们需要运行测试的环境。然后将其提供给我们的 OpsClient 来执行部署并运行测试:
public String remoteTestingExecution(String userInput) {
String orchestratorRequest = REMOTE_TESTING_ORCHESTRATION_PROMPT + userInput;
ChatClient.ChatClientRequestSpec orchestratorRequestSpec = opsOrchestratorClient.prompt(orchestratorRequest);
ChatClient.CallResponseSpec orchestratorResponseSpec = orchestratorRequestSpec.call();
String[] orchestratorResponse = orchestratorResponseSpec.entity(String[].class);
String prLink = orchestratorResponse[0];
StringBuilder response = new StringBuilder();
for (int i = 1; i < orchestratorResponse.length; i++) {
String testExecutionChainInput = prLink + " on " + orchestratorResponse[i];
for (String prompt : OpsClientPrompts.EXECUTE_TEST_ON_DEPLOYED_ENV_STEPS) {
String testExecutionChainRequest = String.format("%s\nPR: [%s] environment", prompt, testExecutionChainInput);
ChatClient.ChatClientRequestSpec requestSpec = opsClient.prompt(testExecutionChainRequest);
ChatClient.CallResponseSpec responseSpec = requestSpec.call();
testExecutionChainInput = responseSpec.content();
}
response.append(testExecutionChainInput).append("\n");
}
return response.toString();
}
主控 Agent 先分析 PR 输出测试环境列表,对每个环境按顺序执行部署和测试,最后聚合结果。
orchestratorRequest 字符串将包含用于分析 PR 变更的提示,并返回环境列表。我们在 orchestratorResponse 数组中获取环境列表。对于每个环境,我们分两步执行子任务:第一步是部署,第二步是测试执行。
我们在第二个 for 循环中使用了 Chain Workflow。我们从部署提示开始,并以 PR URL 和当前环境的语句作为输入。响应包含一个输入语句。然后,该语句被输入到第二个提示中,该提示根据 PR 链接中的信息执行与当前环境相关的测试。
输出包含一个句子,其中包含每个环境的测试执行结果。
请注意,我们通过避免并行或异步执行子任务来简化示例。然而,使用这些技术才是实现 Orchestrator-Workers 工作流模式的最有效方法。该模式的可视化顺序应类似于:
评估-优化模式智能体
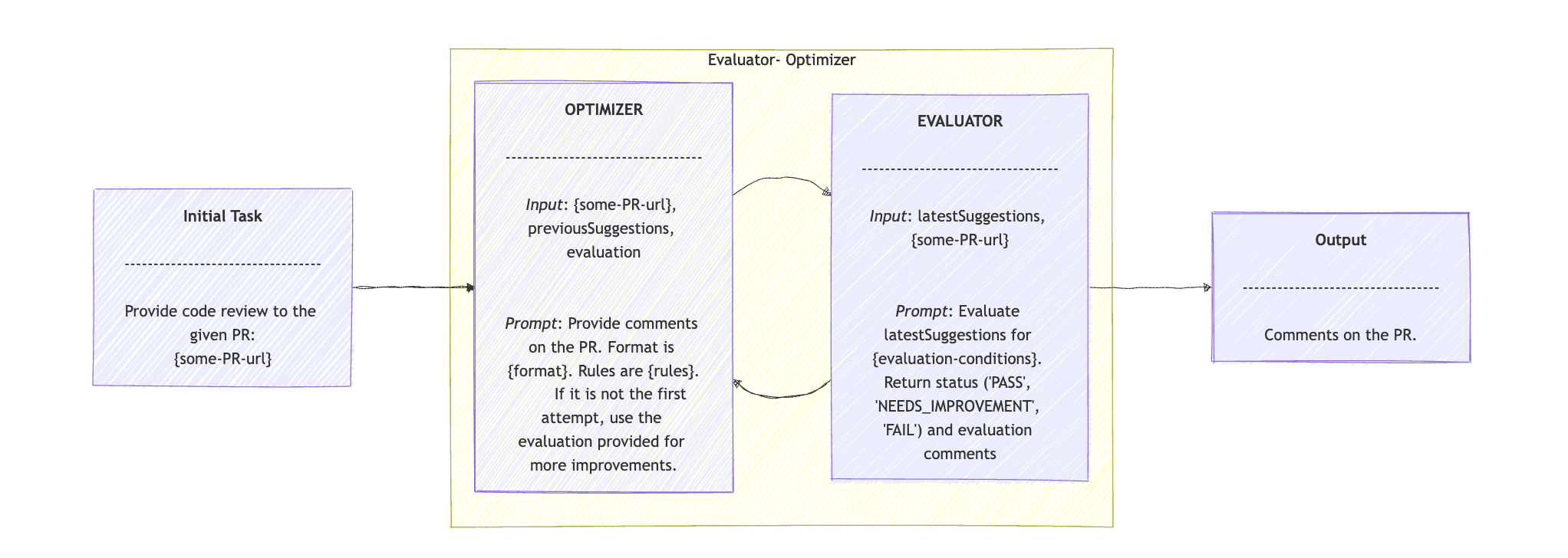
评估器-优化器工作流模式非常适合涉及生成建议的任务。优化器会提出初步解决方案或改进方案。评估器随后会针对该建议提供反馈,并可能再次调用优化器来优化结果或生成更准确的结果。
适用于迭代优化任务,比如自动评审 PR。优化器 Agent 提出改进,评估器 Agent 反馈和打分,必要时多轮循环,直至完成或达到“通过”。
以 PR 评论为例,假设 CodeReviewClient 接口如下:
我们扩展了 DevOps 示例,并围绕 PR 提供了一项新功能:我们将使用 Evaluator-Optimizer 工作流提供 PR 审核意见。假设 CodeReviewClient 接口扩展了 ChatClient ,我们使用 Spring AI 创建 Agent,并附带一个简单的 evaluate() 方法:
public class EvaluatorOptimizerWorkflow {
private final CodeReviewClient codeReviewClient;
static final ParameterizedTypeReference<Map<String, String>> mapClass = new ParameterizedTypeReference<>() {};
public Map<String, String> evaluate(String task) {
return loop(task, new HashMap<>(), "");
}
private Map<String, String> loop(String task, Map<String, String> latestSuggestions, String evaluation) {
latestSuggestions = generate(task, latestSuggestions, evaluation);
Map<String, String> evaluationResponse = evaluate(latestSuggestions, task);
String outcome = evaluationResponse.keySet().iterator().next();
evaluation = evaluationResponse.values().iterator().next();
if ("PASS".equals(outcome)) {
return latestSuggestions;
}
return loop(task, latestSuggestions, evaluation);
}
// we'll see the generate() and evaluate() methods later
}
generate()生成新建议,evaluate()评估改进建议和质量,如果结果为“PASS”则返回,否则继续循环。
评估器优化器模式始于接受任务的 evaluate() 方法。在我们的示例中,输入只是 PR 链接。我们将此任务发送到 loop() 方法。此方法接受三个参数:任务、先前的建议和评估结果。在第一个循环中,我们仅提供任务。
loop() 方法调用 generate() ,我们稍后会看到。结果是最新的建议,我们会将其与任务一起传递给 evaluate() 方法。接下来,我们从 evaluationResponse 中读取结果,如果结果为“PASS”,则返回最新的建议。如果不是,则使用新的 latestSuggestions 和 evaluation 再次调用 loop() 方法。
评估器优化器模式始于接受任务的 evaluate() 方法。在我们的示例中,输入只是 PR 链接。我们将此任务发送到 loop() 方法。此方法接受三个参数:任务、先前的建议和评估结果。在第一个循环中,我们仅提供任务。
loop() 方法调用 generate() ,我们稍后会看到。结果是最新的建议,我们会将其与任务一起传递给 evaluate() 方法。接下来,我们从 evaluationResponse 中读取结果,如果结果为“PASS”,则返回最新的建议。如果不是,则使用新的 latestSuggestions 和 evaluation 再次调用 loop() 方法。
我们使用 CodeReviewClient 代理来执行 generate() 和 evaluate() 方法:
我们使用 CodeReviewClient 代理来执行 generate() 和 evaluate() 方法:
private Map<String, String> generate(String task, Map<String, String> previousSuggestions, String evaluation) {
String request = CODE_REVIEW_PROMPT + "\nPR: " + task
+ "\nprevious suggestions: " + previousSuggestions
+ "\nevaluation on previous suggestions: " + evaluation;
ChatClient.ChatClientRequestSpec requestSpec = codeReviewClient.prompt(request);
ChatClient.CallResponseSpec responseSpec = requestSpec.call();
return responseSpec.entity(mapClass);
}
private Map<String, String> evaluate(Map<String, String> latestSuggestions, String task) {
String request = EVALUATE_PROPOSED_IMPROVEMENTS_PROMPT + "\nPR: " + task
+ "\nproposed suggestions: " + latestSuggestions;
ChatClient.ChatClientRequestSpec requestSpec = codeReviewClient.prompt(request);
ChatClient.CallResponseSpec responseSpec = requestSpec.call();
return responseSpec.entity(mapClass);
}
在 generate() 中,我们向 codeReviewClient 代理提供提示、 任务 、 previousSuggestions 和评估结果 。提示是根据最新的建议和最新的评估结果,对 PR 进行代码审查。建议应遵循既定规则并遵循特定格式。
在 evaluation()方法中,提示是“根据给定的任务和最新的建议, 评估代码改进建议的正确性、时间复杂度和最佳实践 ”。然后返回评估结果“通过”、“需要改进”、“失败” ,以及相应的反馈。
优化器-评估器工作流模式的序列图是:
总结
本文详细解读了 Anthropic 有关智能体开发的五大设计模式及其 Spring AI Java 实现,并结合 DevOps 场景逐步演示每个模式代码和应用方式。每种模式都给出了对应的时序图,建议读者可结合 GitHub 示例代码 深入实操。1




















 1542
1542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











