






Abstract & Introduction
完整的题目是MX-LSTM: mixing tracklets and vislets to jointly forecast trajectories and head poses,就是说引入了tracklets和vislets这两个新的东西来进行轨迹预测
tracklet:在tracking中的连续的一小部分图像序列
vislet:在头部位姿估计中的短序列
迄今(论文发稿 )为止的用LSTM的方法都只用了位置坐标来预测,忽略了还可以从人的头部姿态可以获得的预测信息,这篇文章中的tracklet就是利用位置坐标信息,vislet就是对人的头部位姿进行预测
vislet的优化方法是在LSTM里优化了一个高斯矩阵
vislet也提供了一种构建场景上下文的方法,通过共享一个pooling的过程
同时作为副产物,MX-LSTM也可以预测人在下一秒最可能看向的方向(因为主要贡献是对轨迹的预测,所以头部方向的预测就是副产物)
本文的主要贡献:
•我们表明,通过考虑头部姿态估计,轨迹预测可以显著改善;
•我们提出了一种新的LSTM架构MX-LSTM,它利用位置(tracklets)和方向(vislets)信息,通过优化高于二阶的高斯矩阵来完成
•我们激发了MX-LSTM的需求,表明头部姿势与轨迹相关,即使是在低速度下,大多数预测方法于此失败;
•我们通过利用vislet信息定义了一种新的pooling方法,在[3,55]的意义上;
•由于MX-LSTM,我们在不同的数据集上定义了最先进的预测结果;
•我们提供MX-LSTM头部姿势预测结果,显示新的长期行为分析能力
前人的工作
经典的预测方法有卡尔曼滤波的,线性或高斯回归的,自动回归的,但是都没有把人的行动考虑进去
在之前考虑到了人之间的互动的方法中,要考虑所有的外部人,在本方法中只考虑在人的注意力视锥之内的人
之前的路径预测中都需要知道受追踪的人的目的地是已知的,本方法不需要考虑目的地
虽然高速下头的位姿和动作关系更加紧密,但是低速下也有比较好的关系
LSTM预测模型简述
LSTM很适合那些输出随输入量变化的任务
将行人建模为一个通过“social pooling 层”共享隐藏状态的LSTM,避免出现预测的不一致。这已经有人做的很好了,本文是把social pooling做了一些魔改
本文把头部位姿和轨迹坐标放在一个大的矩阵中一起进行优化
MX-LSTM结构
Tracklets 与 Vislets
对某一个对象而言,一个tracklet包含T个时间连续的坐标点x,一个vislet包含T个时间连续的锚点a(实际上是一个向量),每个锚点和一个坐标点相对应,两个点的距离恒定为r(超参数),a这个向量从x开始指向人脸面向的方向,长度是r。实际而言,这个向量和“绝对水平”之间的夹角就可以拿来代替a,但是为了保持表示的一致性,决定用向量a来表示
用上面的方式形成的tracklet和vislet就被作为两个流送入了MX-LSTM,就可以进行联合的预测,但是送入后要进行如下的预处理,将x和a用嵌入系数作用后变成D维向量,D是隐藏空间的维数
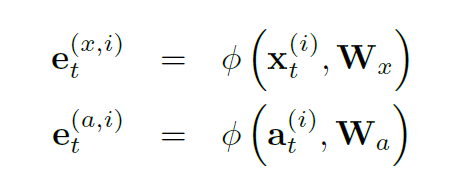
注意对于每一个行人都要形成一个MX-LSTM
Social Pooling
实际架构是基于之前有的一篇做Social pooling的文章,sp可以让LSTM理解人们在拥挤的场景中为了避免相撞是怎样运动的,这篇文章里考虑了所有的人,甚至考虑了观察者背后的人
所以在本文中考虑只关注view frustum of attention (VFOA)——人注意力视锥中的人,视锥的中心线就是a向量,展开角度和深度应该都是超参数
本文的social pooling是一个NND的张量,行人身边的空间被划分为N*N的小格子,池化函数如下:(m,n,h都是啥意思?),若j在i的VFOA里面,就会被扔进去加和
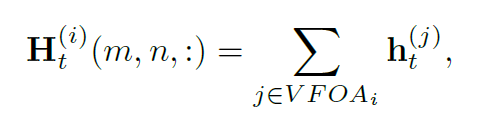
随后又会被统一包装
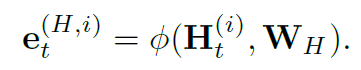
最终形成MX-LSTM的递归方程
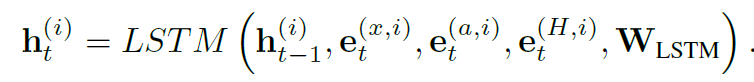
LSTM递归
标准的LSTM里面,hidden state必须包含一个四维的高斯分布,协方差矩阵代表tracklet和vislet之间的协方差,然后运算来实现估计
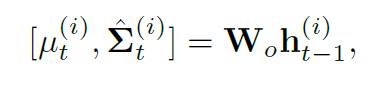
LSTM的权重参数通过最小化这个log函数来获得,为了避免过拟合加了L2正则

Tobs是LSTM看到真值的时间帧,剩下的是做预测要用的时间帧
MX-LSTM优化
要通过优化上面那个特别长的方程来估计一个满秩矩阵是很难的,所以必须保证矩阵半正定,原有的LSTM优化方法无法处理高于二阶的矩阵优化
解决方案涉及无约束优化,对待学习变量的合适的参数化允许执行正半定约束,这更容易表达,极大地提高了优化算法的收敛性。
具体来讲利用了Choleski factorization,这个方法有个缺陷是解不是独特的,解向量每一行乘上-1之后也是解,要保证唯一,就要让对角线元素为正(通过数学的方法可以做到,这里略过)
MX-LSTM的背景
1)人们经常不看向走路方向的正前方,有25%的视频序列中偏移大于20°
2)头部位姿和运动有强相关性,速度越快,头部位姿和运动方向相关性越大,要让LSTM学到这一点
3)速度越低,预测的效果越差
实验结果
分为定量和定性实验
Zara02数据集上表现相对于其他方法优秀的最多
social reasoning去掉之后对性能的影响最大
MX-LSTM要求前八帧给定ground truth,也测试了前八帧用学习估计的MX-LSTM-HPE版,效果比MX-LSTM差一些但是依然优于其他的方法















 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









