







知识星球:https://articles.zsxq.com/id_fxvgc803qmr2.html
目录
一.定义:
jieba 是一个非常流行的中文分词库,广泛用于自然语言处理(NLP)任务中。它提供了多种分词模式,能够高效地将中文文本切分为词语
jieba库支持四种分词模式:精确模式、全模式、搜索引擎模式、paddle模式,并且支持繁体分词,以及自定义词典。具体介绍:
精确模式,试图将句子最精确地切开,适合文本分析;
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
算法
基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
安装:可以通过 pip 命令安装 jieba 库: pip install jieba
基本分词:
-
- 精确模式(默认):jieba.cut(sentence, cut_all=False)
- 全模式:jieba.cut(sentence, cut_all=True)
- 搜索引擎模式:jieba.cut_for_search(sentence)
精确模式(默认模式):
这是 jieba 的默认分词模式,它试图将句子最精确地切开,适合文本分析。
python
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("精确模式: " + "/ ".join(seg_list))
# 输出结果:我/ 来到/ 北京/ 清华大学全模式:
这个模式会把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义。
python
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("全模式: " + "/ ".join(seg_list))
# 输出结果:我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学搜索引擎模式:
这个模式在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
python
seg_list = jieba.cut_for_search("我来到北京清华大学")
print("搜索引擎模式: " + "/ ".join(seg_list))
# 输出结果:我/ 来到/ 北京/ 清华大学/ 北京大学/ 清华大学
paddle 模式(基于深度学习的分词模式):
这个模式利用 PaddlePaddle 深度学习框架,进行更准确的分词和词性标注。使用前需要确保安装了 paddlepaddle。
pip install paddlepaddle
python复制
import jieba
jieba.enable_paddle() # 启动 paddle 模式
seg_list = jieba.cut("我来到北京清华大学", use_paddle=True)
print("Paddle 模式: " + "/ ".join(seg_list))
# 输出结果可能会更加准确,依赖于深度学习模型的效果二 自定义词典
在jieba自定义字典方面,目前我所了解到的常见的应用环境是各网络平台对违禁词的查询搜索处理,以及网站也对用户个人信息的处理,对购物方面评价信息的处理等等。因此,我同样也使用了jupyter notebook尝试了自定义词典的使用,text文本文件及运行结果如下图所示:
A. 添加词语
使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
B. 载入自定义词典
如果有一个包含自定义词语的文件,可以使用jieba.load_userdict(file_path)方法加载该文件,并将其中的词语加入到词典中。
import jieba
# 添加单个词语到词典中
jieba.add_word("自然语言处理")
# 载入自定义词典文件
jieba.load_userdict("custom_dict.txt")
sentence = "我爱自然语言处理"
# 分词结果包含自定义词语
seg_list = jieba.cut(sentence)
print("/".join(seg_list)) # 输出: 我/爱/自然语言处理三.文本解析
def getext():
fname=input("请输入要打开的文件路径及名称,以txt结尾:")
fo=open(fname) #打开该文件,默认是文本文件,文本文件其实就是一个字符串
txt=fo.read() #<文件名>.read() 默认是读取文件全部内容
txt=txt.lower() #将文本所有字母小写
for ch in '!"#$%()*+<_>/:;<>=?@[\]\^_{}|~':
txt=txt.replace(ch,'') #将文本中含有的所有上述字符都变为空格
return txt
hamlettxt=getext()
words=hamlettxt.split() #默认值,是将文本中单词按照空格分成一个一个的单词,并将结果保存成列表类型
counts={} #定义一个空字典类型,因为我们希望单词和该单词出现的次数作为一个键值对
for word in words: #遍历words列表的每一个值
counts[word]=counts.get(word,0)+1
items=list(counts.items()) #将该字典转化成一个列表,其中的键值对是以元组的形式存在
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count=items[i] #items[i] 是个元组,元组可以带括号,可以不带括号;赋值
print("{:<10}{:>5}".format(word,count))调整词出现的频率
str = "你好呀,我叫李华!多多关照!"
jieba.suggest_freq(("李", "华"), True)
print(jieba.lcut(str))
四. 关键词提取
A. 基于TF-IDF算法的关键词提取
jieba库提供了基于TF-IDF算法的关键词提取方法jieba.extract_tags(sentence, topK=10),用于从文本中提取关键词。
参数:
sentence:要提取的文本
topK:返回多少个具有最高TF/IDF权重的关键字。默认值为 20
withWeight:是否返回关键字的TF/IDF权重。默认为假
allowPOS:过滤包含POS(词性)的单词。空无过滤,可以选择['ns', 'n', 'vn', 'v','nr']
B. 基于TextRank算法的关键词提取
jieba库还提供了基于TextRank算法的关键词提取方法jieba.textrank(sentence, topK=10),也可以用于从文本中提取关键词。
topK参数指定返回的关键词数量,默认为10。
C. 使用示例
import jieba
sentence = "自然语言处理是人工智能领域的重要技术之一"
# 基于TF-IDF算法的关键词提取
keywords = jieba.extract_tags(sentence, topK=5)
print(keywords) # 输出: ['自然语言处理', '人工智能', '技术', '领域', '重要']
# 基于TextRank算法的关键词提取
keywords = jieba.textrank(sentence, topK=5)
print(keywords) # 输出: ['技术', '重要', '领域', '自然语言处理', '人工智能']五. 词性标注
A. 词性标注集
jieba库支持对分词结果进行词性标注,使用的是jieba库内置的词性标注集。
B. 使用示例
import jieba
import jieba.posseg as pseg
# 分词并进行词性标注
words = pseg.cut("自然语言处理很有趣") #jieba默认模式
jieba.enable_paddle() #启动paddle模式。 0.40版之后开始支持,早期版本不支持
words = pseg.cut("我爱北京天安门",use_paddle=True) #paddle模式
for word, flag in words:
print(word, flag)
# 输出:
# 自然语言 l
# 处理 v
# 很 d
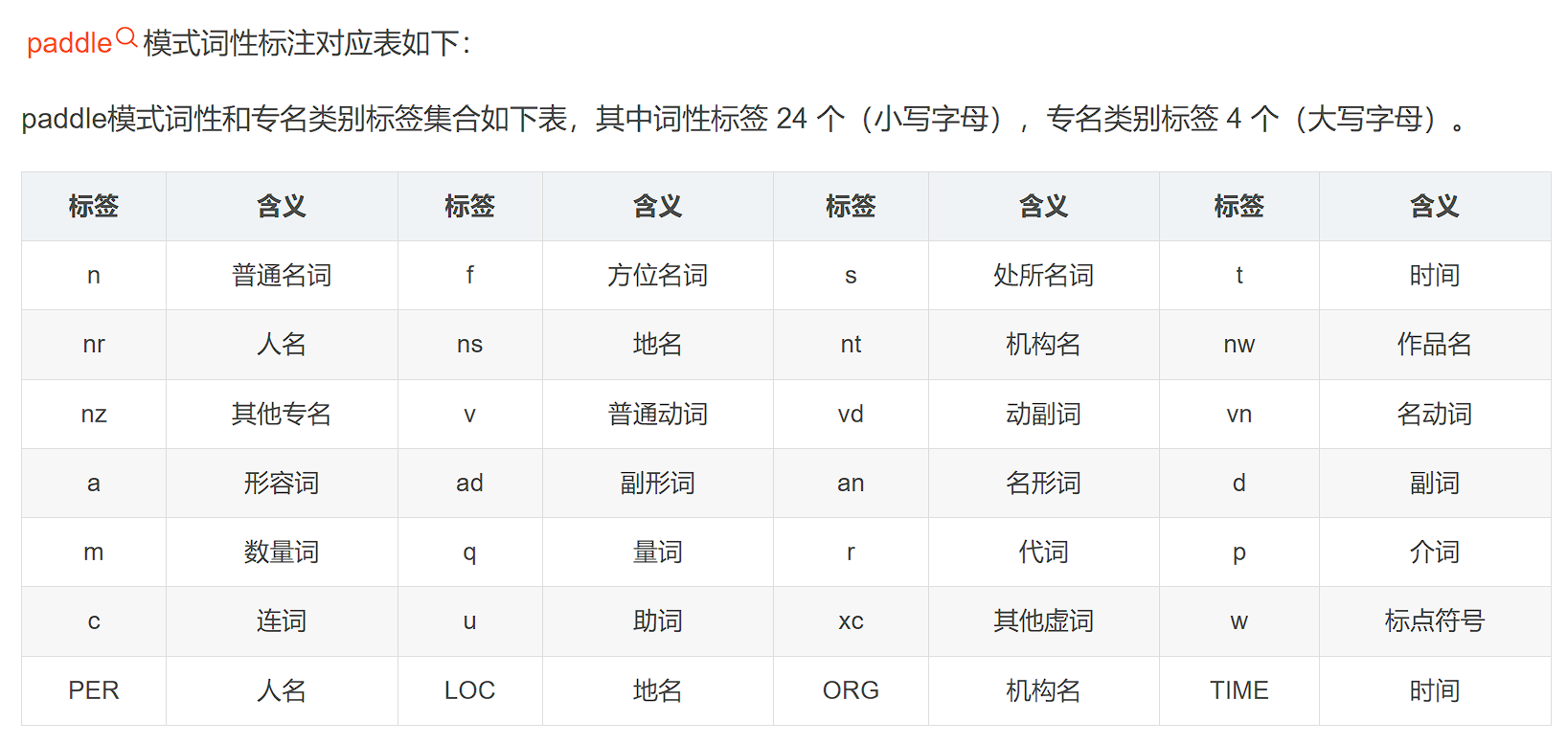
# 有趣 apaddle模式词性标注对应表如下:
paddle模式词性和专名类别标签集合如下表,其中词性标签 24 个(小写字母),专名类别标签 4 个(大写字母)。
六. 并行分词
A. 并行分词的优势
jieba库支持并行分词,能够利用多核CPU提高分词速度。
并行分词使用的是基于python多进程的方式,需要在分词前调用jieba.enable_parallel()启用并行分词,之后可以正常使用分词功能。
B. 并行分词使用示例
import jieba
jieba.enable_parallel(4) # 启用并行分词,使用4个进程
sentence = "自然语言处理很有趣"
# 分词结果
seg_list = jieba.cut(sentence)
print("/".join(seg_list))
# 输出: 自然/语言/处理/很/有趣jieba.disable_parallel() # 关闭并行分词
七. Tokenize接口
A. 默认模式
jieba库提供了Tokenize接口jieba.tokenize(sentence, mode='default'),用于获取每个词语的起始位置和词性。
默认模式下,返回结果包含词语、词语在文本中的起始位置和结束位置。
B. 搜索引擎模式
在Tokenize接口中,可以选择搜索引擎模式,通过mode='search'参数指定。
搜索引擎模式下,返回结果还包含分词的偏移量,适用于搜索引擎等应用场景。
C. 返回结果格式
Tokenize接口返回的结果是一个可迭代的生成器,每个生成器元素都是一个元组,包含词语、起始位置、结束位置和词性(可选)。
D. 使用示例
import jieba
sentence = "自然语言处理很有趣"
# 默认模式下的Tokenize接口
tokens = jieba.tokenize(sentence)
for tk in tokens:
word = tk[0]
start_index = tk[1]
end_index = tk[2]
print(word, start_index, end_index)
# 输出:
# 自然语言 0 4
# 处理 4 6
# 很 6 7
# 有趣 7 9
# 搜索引擎模式下的Tokenize接口
tokens = jieba.tokenize(sentence, mode='search')
for tk in tokens:
word = tk[0]
start_index = tk[1]
end_index = tk[2]
print(word, start_index, end_index)
# 输出:
# 自然 0 2
# 语言 2 4
# 处理 4 6
# 很 6 7
# 有趣 7 9八. 总结
本教程介绍了Python中jieba库的基本使用方法和常用功能,包括分词基础、自定义词典、关键词提取、词性标注、并行分词和Tokenize接口。通过学习和掌握这些功能,你可以在中文文本处理中灵活应用jieba库,实现有效的分词、关键词提取和词性标注等任务。
在使用jieba库时,你可以根据具体需求选择不同的分词模式,如精确模式、全模式和搜索引擎模式。还可以通过自定义词典添加特定词语,提高分词的准确性。关键词提取功能可以帮助你从文本中提取出重要的关键词,有助于文本理解和信息提取。词性标注功能可以标注每个词语的词性,对于一些需要深入分析的任务很有帮助。Tokenize接口可以提供词语的起始位置和词性信息,适用于一些特定的应用场景。并行分词功能可以充分利用多核CPU,提高分词速度。
九.下文
jieba数据分析
















 1702
1702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









