








熟悉神经网络的可能知道,Hornik在1989年,就证明了一个定理:
- 只需一个包含足够多神经元的隐层,多层前馈神经网络就能以任意精度逼近任意复杂的连续函数
那大家可能就会有疑问:既然一个隐层就够了,我们为什么还需要多层神经网络呢?
我们可以从这个定理中找到可能思考方式:
- (1)足够多神经元,你在实践中能保证么?
- (2)如果你要拟合的模型并不是连续函数,单个隐层够吗?
显然,这两个问题的回答都是否定的。
如果觉得我这个解释过于粗糙,可以看Andrew Ng在新课程”Deep Learning”中的解释。




下面这个图,我们也能看到:
- 第一层,提取低层次的简单特征(边缘特征)
- 第二层,将简单特征组合成复杂一点的特征(器官)
- 第三层,将第二层的特征组合起来
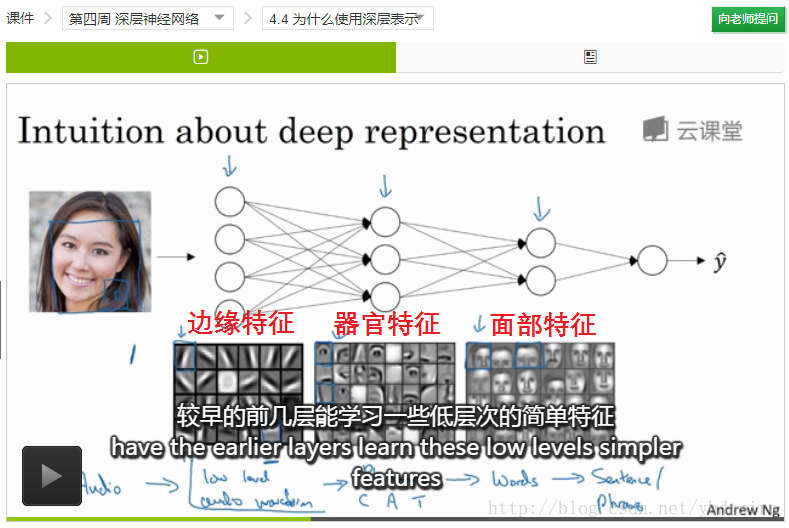
Andrew Ng还提到,神经科学家们觉得,人的打到也是先探测简单的东西,然后组合起来才能看到整体。















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









