









 本文探讨了深度学习在自然语言处理(NLP)领域的应用,尤其是单词嵌入技术如何帮助模型学习有意义的表示。深度学习模型通过学习单词向量,不仅可以捕捉到相似词汇的语义关系,还能实现跨语言映射和图像分类。递归神经网络(RNN)在处理语言结构和表达方面展现出了巨大潜力,尽管在可逆句子表示方面仍面临挑战。
本文探讨了深度学习在自然语言处理(NLP)领域的应用,尤其是单词嵌入技术如何帮助模型学习有意义的表示。深度学习模型通过学习单词向量,不仅可以捕捉到相似词汇的语义关系,还能实现跨语言映射和图像分类。递归神经网络(RNN)在处理语言结构和表达方面展现出了巨大潜力,尽管在可逆句子表示方面仍面临挑战。
深度学习(Deep Learning),自然语言处理(NLP)及其表达(Representation)
简介
过去几年中,深度神经网络在模式识别领域占据着统治地位。他们在诸多计算机视觉任务领域,将之前的最好算法彻底击败。语言识别也正朝着这个方向发展。
They blew the previous state of the art out of the water for many computer vision tasks.
尽管如此,我们不禁要问,DNN(Deep Neural Networks)为什么这么好?
本文列举了一些将DNN在自然语言处理方面的出色成果。通过这种方式,我希望对于DNN为何有效果提供一个不错的答案。
单隐含层神经网络
带有一个隐含层的神经网络具有通用性(Universality):给定足够的隐藏节点,它能够你和任意函数。这是一个经常被引用,但是被误解的“定理”。
这基本上是正确的,因为隐含层可以被当成是查找表(lookup table)来使用。
为简明起见,先考虑感知机(perception)网络。感知机是非常简单的神经元,超出阈值就激活,反之不激活。感知机网络的都以二进制作为输入和输出。
需要注意的是可能的输入类型是有限的。对于每一个可能的输入,我们都可以在隐含层构建一个仅对其激活的神经元。然后我们可以利用隐藏层与输出层直接的连接来控制输出层的特定样本。如图1所示。
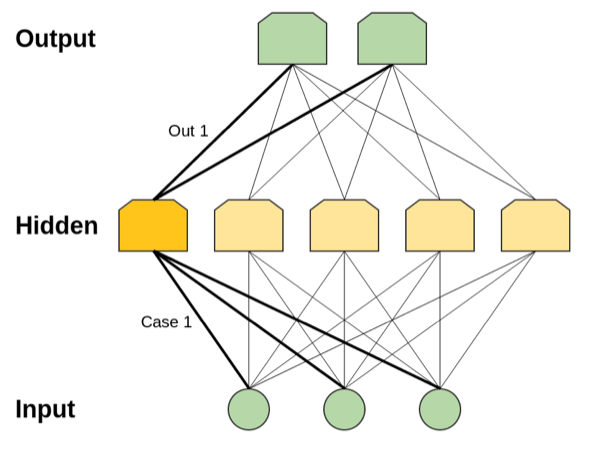
事实上,具有单层的神经网络是通用的。但是这完全没有什么值得让人感到兴奋的地方。你的模型能够达到和查找表格一样的能力,但这并不是让人觉得这个模型很好的有力依据。这是表示,你的模型仅仅只是有可能完成相应任务而已。
通用性意味着网络可以拟合你任意给定的数据。但是却并不意味着能够以合理方式生成合理的新数据点。
因此,通用性并不能很好地解释为何神经网络效果这么好。真正的原因是更加微妙的,为了理解这些,我们需要首先去理解一些具体的结果。
单词嵌入(Word Embedding)
我希望通过介绍一个深度学习中的有趣实例来作为开始:单词嵌入。我认为单词嵌入是目前深度学习中最有趣的研究领域,尽管这个问题Bengio等人在10年前就已经提出了。此外,我认为这是从直觉上理解为何深度学习如此有效的最好方式。
一个单词嵌入操作:
单词嵌入定义了语言中的单词到高维向量的一个映射函数(可能是从200维到500维)。例如:
W(“cat”) = (0.2, -0.4, 0.7, …)
W(“mat”) = (0.0, 0.6, -0.1, …)
通常函数就是一个查找表格,由一个矩阵
θ
参数化,其中每个词占一行:
W对每个单词进行随机初始化,随后将会学习到有意义的向量,从而能够实现某些特定任务。
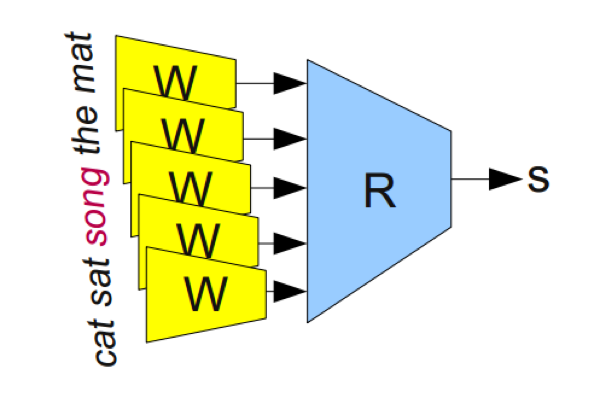
例如,我们可以训练网络来判断一个5元组(5个单词的短语)是否是“有效的”。我们能够很容易地从维基百科获得大量的5元组(例如:“cat sat on the mat”),然后把其中一半的5元组通过随机替换单词来破坏掉(例如:“cat sat song the mat”),通过这种方式我们总是能够把一个5元组变成无意义的。
我们模型在5元组上训练,通过W得到单词的向量表达。然后对模型输入一些“模式”R来预测这个5元组是“有效”还是“无效”的,如图2所示:
R(W(”cat”), W(”sat”), W(”on”) , W(”the”) , W(”mat”)) = 1
R(W(”cat”), W(”sat”), W(”song”) , W(”the”) , W(”mat”)) = 0

为了预测这些值的正确性,网络需要同时学习W和R的良好参数。
目前看来这个任务并不是那么有趣。这个任务可能对于检测文本中是否有语法错误比较有效。但是真正有趣的其实是W。
(事实上对我们来说,最重要的就是学习W的参数。虽然我们也可以用来预测句子中得下一个单词是什么。但是我们却并不关心这个。本节将会讨论单词嵌入并且对不同的方法并不做详细区分。)
我们可以通过视觉化方法如t-SNE来感受单词嵌入空间(Word Embedding Space),如图3所示。

这种类型的单词“映射”带给我们许多直观上的理解。相似的词靠的很近。另一种方式是给定一个词,看看最靠近它的单词是什么。还是可以看到,靠近的单词都很类似。
让相似的单词具有相似的向量是很自然的想法。如果你为某一个单词替换了同义词(例如:“a few people sing well” 到 “a couple people sing well”),句子的有效性并不会发生改变。然而从朴素的角度看,句子的内容其实改变了很多;
如果W将同义词映射到一起(如“few” 与 “couple”),从R的角度看,句子改变并不大。
这是非常有用的。因为5元组的所有可能组合是非常巨大的,我们用以作为训练集的数据却相对较少。相似的单词靠近使得我们能够从一个句子生成另一个相似的句子。这并不是说仅仅是同义词之间的替换,这种替换也可以是相似种类的单词的替换(例如:“the wall is blue” 到 “the ceiling is red”)。这种影响随着单词数量的扩大而指数级增长。
因此,显然用W可以做非常有用事情。但问题是我们如何学习W?这很类似于这种情况:有很多类似“the wall is blue”的句子,并且知道这些句子都是“有效的”,然后给模型看“the wall is red”这个句子。因此将“red”变换得靠近“blue”将会使网络表现得更好。
我们依然需要学习每一个单词使用的例子,但是我们可以通过类比来生成这些单词的全新组合。你见过所有你理解的单词,但是你能理解的句子,并不需要所有都见过。这对于神经网络也是一样的。
单词嵌入还表现出更加出色的特性:单词之间的类比关系能够以它们对应向量的关系编码。例如,存在着恒定不变的表示男人-女人这种不同关系的向量:
W(woman)−W(man)≃W(aunt)−W(uncle)≃W(queen)−W(king)
这似乎并不让人惊讶,毕竟将性别代词替换掉会造成句子的语法错误。可以说『she is the aunt』『he is the uncle』,如果你见到了『she is the uncle』,那么很有可能是语法错误了。如果一半的单词都被随机替换,那么这种语法错误很有可能会发生。
『当然了!』我们也许会事后诸葛亮地说:『单词嵌入能够以一种连续的方式来学习编码性别信息。事实上可能就存在着一个「性别维度」,对于单复数的区别也是一样的。所以学习这种微不足道的关系是非常容易的。』
然而事实并非如此,通过这种编码方式,比性别关系复杂得多的关系也可以能被学习出来,简直就是个奇迹!
| Relationship | Example 1 | Example 2 | Example 3 |
|---|---|---|---|
| France-Paris | Italy:Rome | Japan:Tokyo | Florida:Tallahassee |
| big-bigger | small:larger | cold:colder | quick:quicker |
| Miami-Floarida | Baltimore:Maryland | Dallas:Texas | Kona:Hawaii |
| Einstein-scientist | Messi:midfielder | Mozart:violinist | Picasso:painter |
| Sarkozy-France | Berlusconi:Italy | Merkel:Germany | Koizumi:Japan |
| copper-Cu | zinic:Zn | gold:Au | uranium:plutonium |
| Berlusconi-Silvio | Sarkozy:Nicolas | Puttin:Medvedev | Obama:Barack |
| Microsoft-Windows | Google:Android | IBM:Linux | Apple:iPhone |
| Microsoft-Ballmer | Google:Yahoo | IBM:McNealy | Apple:Jobs |
| Japan-sushi | Germany:brawurst | France:tapas | USA:pizza |
单词嵌入中的关系配对 (Mikolov 2013)
需要注意的是,W的这些特性都只是副产品。我们从未尝试使相似的单词靠的更近;我们也从未对不同向量的编码进行类比。我们所做的仅仅只是进行一项简单的任务,比如预测一个句子是否是有效的。这些特性或多或少会在优化的过程中显现。
这可能是神经网络的强大之处:他们可以自动学习出数据的更好表示。反之,良好的数据表达形式是解决许多机器学习问题的基础。单词嵌入只是学习表达的一个显著的例子。
共享表达(Shared Representations)
单词嵌入的性质固然有趣,但是我们能利用它来做什么呢?除了像预测一个五元组是否『有效』,这种简单的事情。
我们已经知道为了在简单任务上有良好效果,我们需要做单词嵌入,但是基于单词嵌入的良好表现,你可能猜想到这也可能应用在NLP的任务中。事实上,想这样的单词表达式非常重要的:
单词嵌入的应用已经成为了近年来许多NLP系统成功的关键,这些任务包括命名实体识别 (Named Entity Recognition, NER) 、会话片段标注 (Part-of-speech tagging) 、句法分析 (parsing) 以及语义角色标注(semantic role labeling)。
深度学习的通用策略是——学习任务A的良好表达形式,然后运用于任务B,如图4所示。根据其细节的不同,这种过程有诸如预训练(pretraining)、迁移学习(transfer learning)以及多任务学习(multi-task learning)。这种方法的一个重要优势在于可以让表达学习到多种类型的数据。
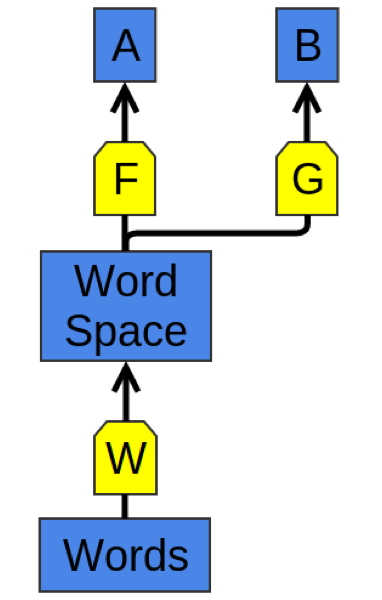
之前我们是从一种数据学习出表达形式,然后将其运用于多种任务中;反过来,我们可以通过学习多种数据,将其映射到一个表达之中。
双语单词嵌入(bilingual word-embedding)就是一个很好的例子。
我们可以将两种不同的语言映射到一个单一的共享空间。在这个例子中,我们可以把英语和普通话映射到同一空间,如图5所示。

当然,可以观察到到我们知道具有相似意义的单词,它们相互之间靠得很近,这并没有什么,因为我们的优化目标就是这样。但更有趣在于,我们并不知道的互为翻译的单词相互靠得很近。
根据我们之前关于单词嵌入的认识,这也并不太让人惊讶。单词嵌入能把相似的单词靠得很近,所以如果我们知道具有相似的意义的英语和汉语单词靠得很近,那么他们的同义词最终也会靠得很近。我们也知道,对于性别差异这种内容,最终会以一个表示不同量的常向量来表示。这就好像迫使大量的样本同时在英文与中文里,按照统一的『不同向量』排列。因此,如果我们知道两个表示男性的单词互为翻译,那么我们也能由此得到互为翻译的表示女性的单词。
从直观上看,这就有点像两种语言具有相似的『形状』,通过迫使他们按照上述方式排列在不同位置,两种语言就会在正确的位置重叠在一起,如图6所示。
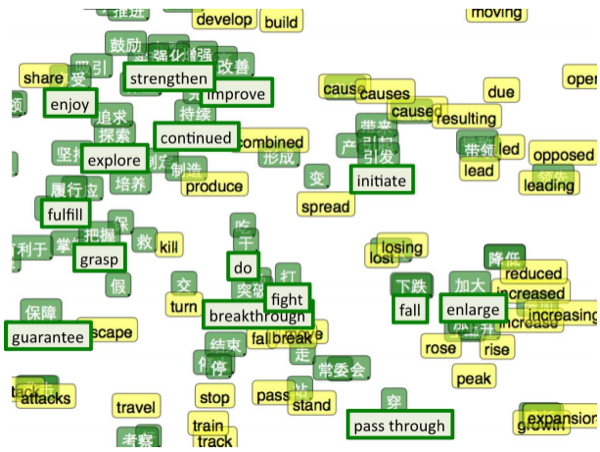
t-SNE visualization of the bilingual word embedding. Green is Chinese, Yellow is English.
在双语单词嵌入中,我们学习到了两种非常相近数据的共享表达。但是我们也可以在相同的空间中嵌入非常不同的数据。
最近,出现了深度学习将单词和图片嵌入到同一空间的探索。
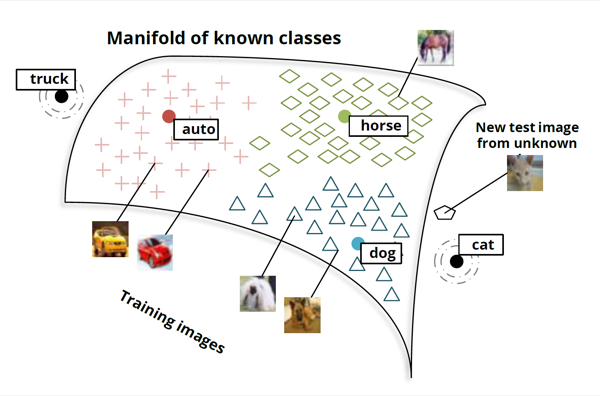
其基本思想是通过输出一个单词嵌入来对图像进行分类。关于狗的图片被映射到『狗』单词的向量附近。关于马的图片被映射到『马』单词的向量附近。等等。如图7所示。
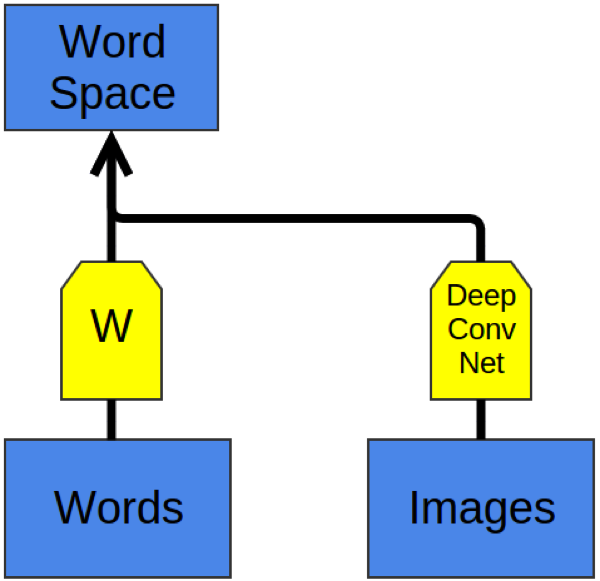
最有趣的是在你把这个模型在新类型的图片上进行测试的时候。例如,假设模型并没有对分类猫进行训练——即把猫的图片映射到『猫』单词向量的附近——那么如果我们尝试对猫进行分类会怎么样?
结果显示,网络能很好处理这些新类型的图片。猫的图片并非随机映射到嵌入空间中,而是映射到『狗』单词的附近,并且也很靠近『猫』单词。类似地,拖拉机的图片也被映射到『拖拉机』单词旁边,与『汽车』单词靠得很近,如图8所示。
Socher et al. (2013b)
如图9所示是由Stanford小组由8个已知类别(2个未知类别)得到的。结果已经很不错。但是仅使用如此少的类别,图片与语义空间能够插入的点太少。

Google 小组做了一个更大的版本——与此同时他们用了1000类——其后又有了新的改进。这两者都采用了非常强大的图片分类模型(Krizehvsky),但是他们对单词嵌入的方式并不一样。
实验结果非常不错。尽管对于没有见过图片,它们不能得到精确的对应类比向量的位置,但是它们能够得到正确的领域。因此,如果你将其应用于类比并不太相同的图像分类,模型能够正确区分其不同类别。
尽管我从未见过长锦蛇或者犰狳,如果你给我看它们俩的图片,我能够告诉你谁是谁,因为我对于各种动物对应什么单词有总体的认识。这个网络也能做到相同的事情。
(这些结果都是应用了『这些单词是相似的』进行推理。然而似乎直接基于单词之间的关系会更加强大。在我们的嵌入空间中,男性单词向量和女性单词向量之间有『区分常向量』。类似地,在图片空间中,男性图片与女性图片之间也应该有『区分常特征』。Beards, mustaches, baldness 这些都是作为男性的强烈标志。Breasts以及稍微不可靠的, long hair, makeup, jewelery显然是女性的标志。即使你没有见过国王,但是在见过皇后之后,又发现了一个同样带着皇冠,却长了胡子的,那么很有理由认为这是皇后的男性版本。)
共享嵌入是非常有趣的一个研究领域,主要目的在于研究为何基于特征表达角度的深度学习方法如此强大。
递归神经网络
我们由下列网络(如图10)来讨论单词嵌入:
用来学习单词嵌入的模块化网络(Bottou(2011))
上面的图代表了一个模块化的网络:
这个网络由2个模块组成:W和R。这种把较小神经网络组织成完整神经网络的方法用得并不很广泛。然而这种方法在自然语言处理(NLP)中却应用广泛。
上述模型很强大,但不幸地有一些局限性:
他们都只能使用固定数量的输入。
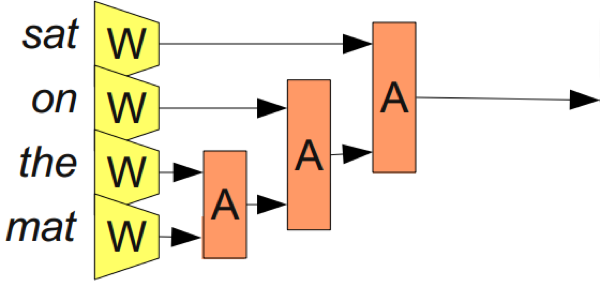
通过使用关联模块我们能够克服这个缺点。此时A把2个单词或者短语的表达进行合并,如图11所示。
From Bottou (2011)
通过合并单词序列,A让我们从表达单词到表达短语,甚至是表达句子!正因为我们能够合并不同数量的单词,我们并不需要指定数量的输入。
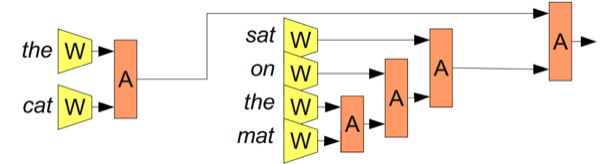
直接以现行方式合并单词并不一定有意义。例如:『the cat sat on the mat』可以被括号分隔为『((the cat)(sat(on(the mat))))』。我们可以将A应用于这种分隔,如图12所示。
From Bottou (2011)
这些模型经常被称为『递归神经网络』,因为其模块的输入经常是相似类型模块的输入。它们也经常被称为『树结构神经网络』。
递归神经网络已经在NLP任务中取得了巨大成功。例如Socher et al. (2013c)使用了递推神经网络来预测语句情感,如图13所示:
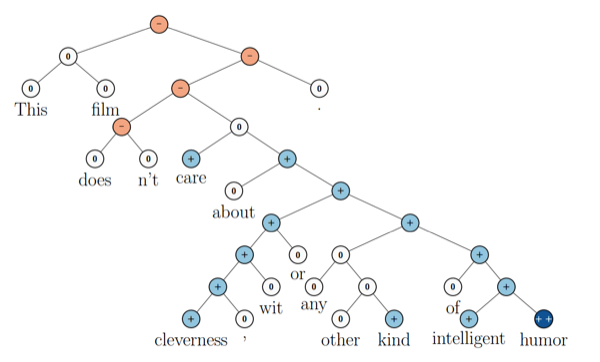
From Socher et al. (2013c)
一个主要目标是创造一个可翻转的句子表达。这个表达能够从大致具有相似意义的句子中重构褚一个实际的句子来。例如,我们引入一个分解模块D,作为A的逆操作,如图14所示。
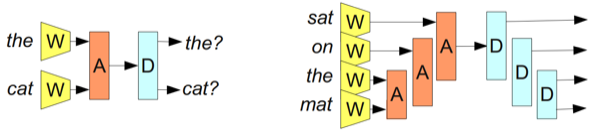
From Bottou (2011)
如果我们能够完成这些,这将是个非常强大的工具。例如,我们可以尝试做双语句子表达,并且运用它来坐翻译。
不幸的是,结果表明这非常困难。非常非常困难。很多人依然寄予了很大希望,继续着研究。
最近,Cho et al. (2014) 在短语表达上已经有所进展,这个模型(如图15)以对英文进行编码,然后解码为法语。请看它学到的短语表达!
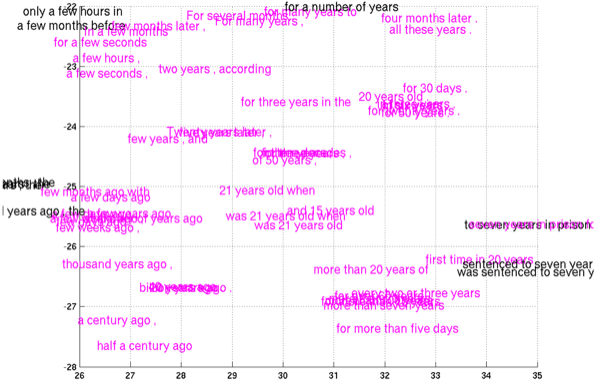
Cho et al. (2014)
结论
深度学习的表达角度是一个非常强大的观点,这也似乎解释了为何深度神经网络效果如此有效。此外,我认为非常美妙之处在于:为何神经网络是有效的?因为通过优化层叠模型可以产生更好的数据表达。
深度学习是一个年轻的领域,理论建立并不完备,观点也会快速变化。也即是说,神经网络的表达角度很流行只是我的个人印象。















 1559
1559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









