







人工智能咨询培训老师叶梓 转载标明出处
尽管AI在算法和数据处理方面取得了巨大进步,但这些智能体大多在数字环境中被创建和训练,与人类所居住的物质世界之间存在着显著的“感官鸿沟”。它们缺乏对现实世界的丰富感知能力,无法像人类一样灵活地感知、思考和行动。
论文《V-IRL: Grounding Virtual Intelligence in Real Life》正是针对这一问题提出了创新性的解决方案。作者认为要开发能够在现实世界环境中有效操作的AI智能体,就必须弥合数字世界与物理世界之间的现实主义差距。V-IRL平台的引入,旨在创建一个虚拟但现实感十足的环境,让智能体能够以前所未有的方式与真实世界进行交互。
V-IRL平台通过利用真实的地理空间数据和街景图像,为智能体提供了一个丰富的感知基础,使其能够在城市环境中导航、执行复杂任务,并实时互动。这一平台不仅为研究人员提供了一个利用全球范围内的丰富数据来创建和测试多样化自主智能体的灵活工具,而且还为衡量智能体在感知、决策和与真实世界数据交互方面的能力提供了一个广阔的测试场。
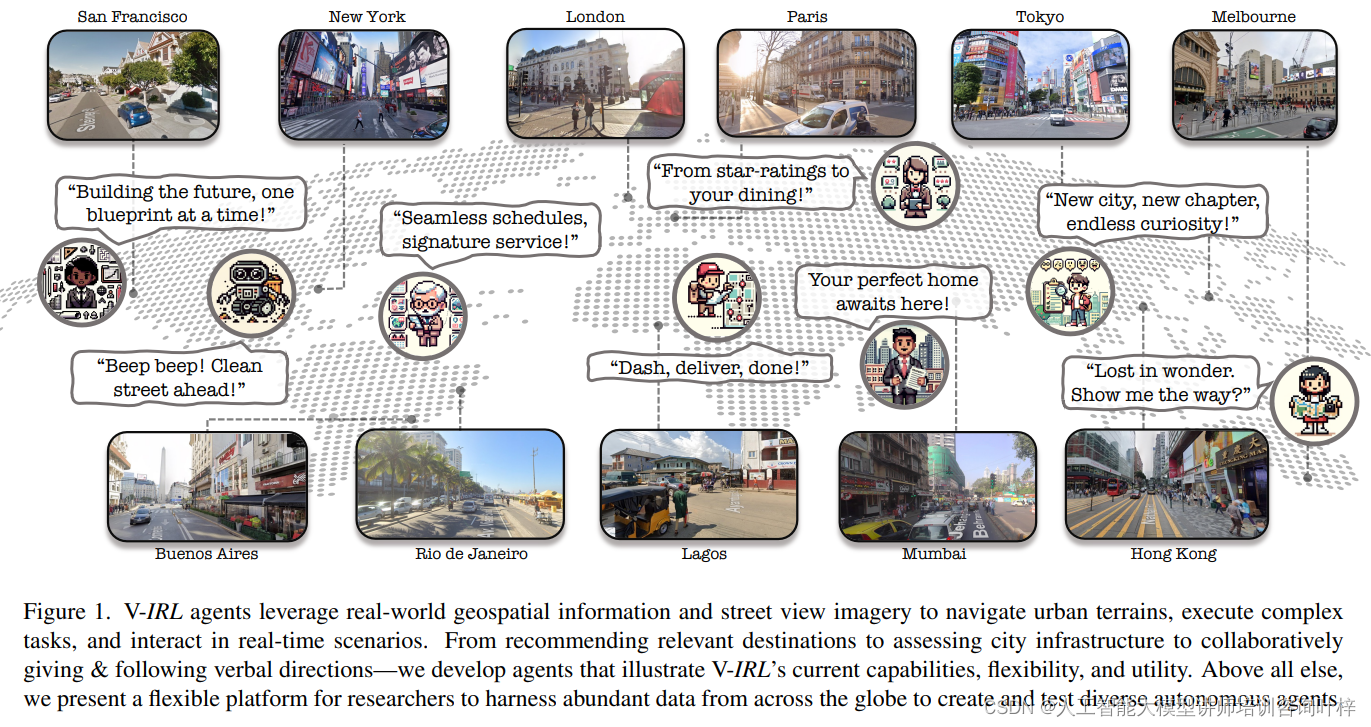
案例
V-IRL智能体在全球真实城市的虚拟表示中"居住"。这些城市表示的核心是地球上各点的地理坐标。利用这些坐标,V-IRL允许虚拟智能体使用地图、街景图像、附近目的地信息以及来自任意地理空间API的额外数据,将自己锚定在真实世界中。
案例:路径优化器(Route Optimizer)
- 角色:Peng,一名来自四川成都的学生,刚到纽约开始他的交换生生活。
- 任务:需要访问城市中的五个地点:大学卡中心、宿舍、研究中心、图书馆和学生中心。
- 目标:给定一个起始地址和一系列途经点,规划出访问所有途经点的最短路线,并在街景中跟随该路线。
- 结果:V-IRL通过真实地理空间信息实例化智能体,使其能够执行如路径优化等实用任务。
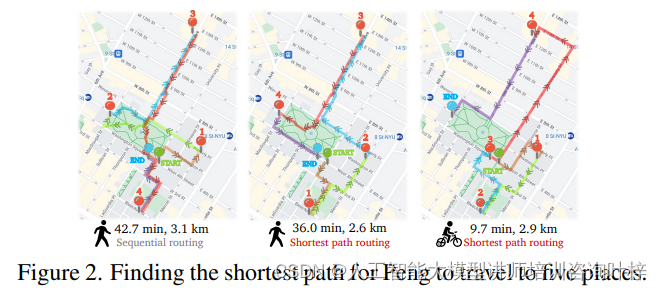
为了解决更复杂的任务,作者遵循了语言驱动智能体的模式。大模型(LLMs)使智能体能够灵活地进行推理、规划和使用外部工具及API。
案例:地点推荐器(Place Recommender)
- 角色:Aria,一位26岁的研究生,喜欢尝试新的餐厅,并且在她的博客上分享她最喜欢的地点。
- 任务:根据特定地点、背景和意图,综合附近商家的评论,提供推荐。
- 目标:V-IRL暴露了丰富的现实世界信息给智能体,它们可以利用这些信息完成现实世界任务。
尽管语言驱动的智能体可以使用外部工具处理一些现实世界任务,但它们仅依赖基于文本的信息,限制了它们在需要视觉基础的任务中的适用性。
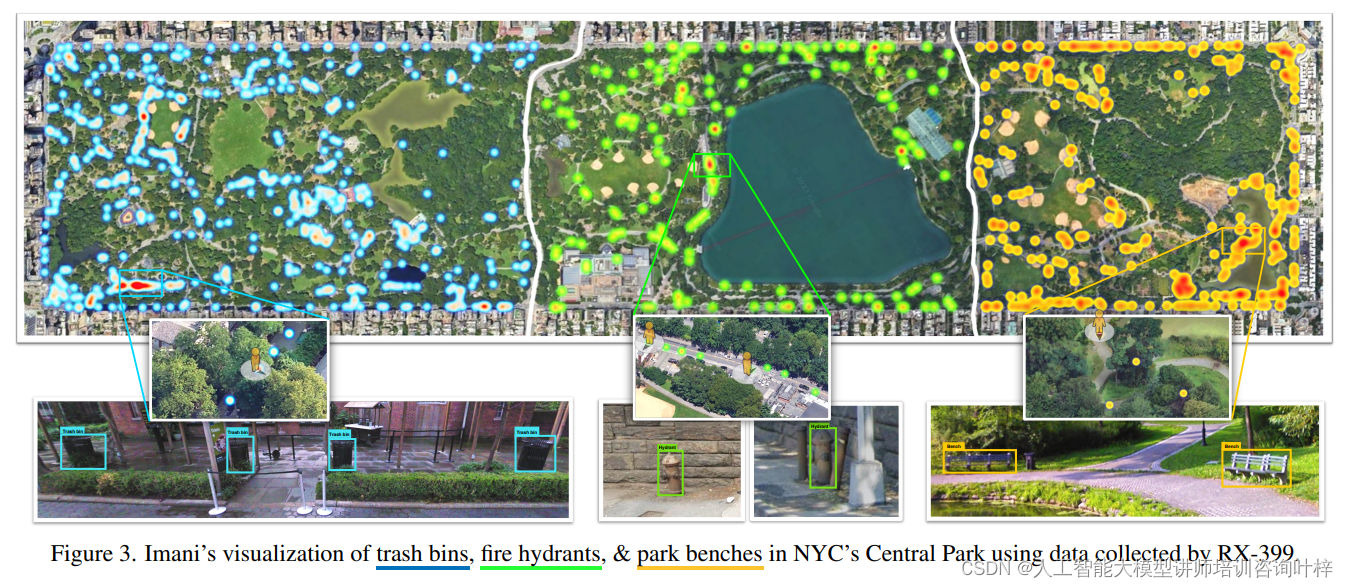
案例:城市助手机器人(Urban Assistance Robot)
- 角色:RX-399,一个先进的城市机器人,具备高级的对象检测、定位和导航遥测系统,能够在繁忙的城市街道上执行感知任务。
- 任务:沿着指定路线行进,检测特定对象(例如垃圾箱、消防栓、长椅等)的实例。
案例:城市规划师(Urban Planner)
- 角色:Imani,一位42岁的城市规划师,热衷于在自然和城市生态系统之间保持和谐平衡。
- 任务:使用RX-399收集第一人称数据,用于她的研究。
人类经常合作解决复杂的现实世界任务。这种合作通过将复杂任务分解为更简单的子任务,提高了效率和效果。
案例:旅游者(Tourist)
- 角色:Ling,一位来自台北的充满活力的旅行者,她总是渴望探索新的城市和文化,并且当她迷路时,总是不怕向当地人寻求帮助。
- 任务:向附近的"Local"智能体询问前往特定地点的路线。"Locals"会在地图和街景中预览路线,然后以自然语言提供步行方向,提及主要的交叉口和地标。
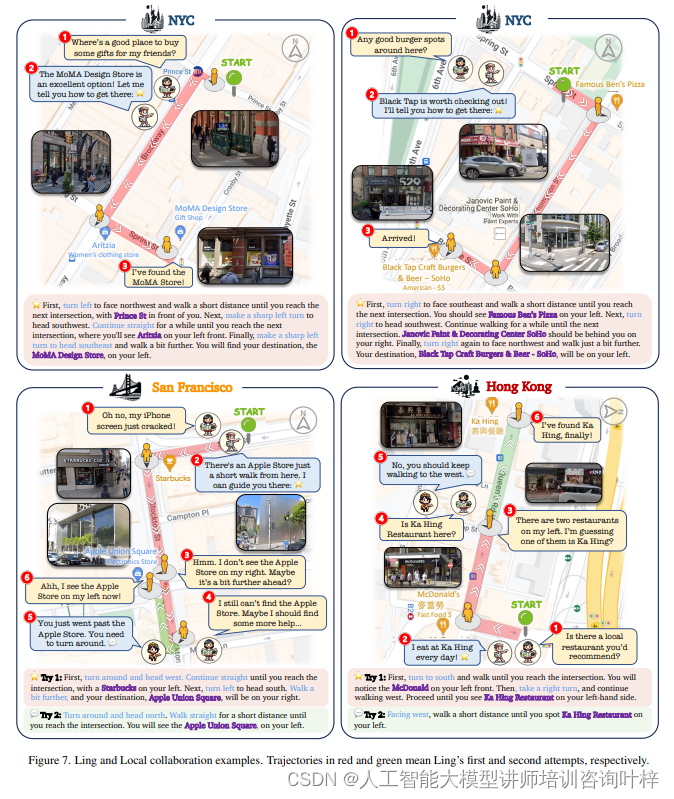

通过这些案例,论文展示了V-IRL平台如何使智能体在真实世界的虚拟环境中执行各种复杂任务,从而证明了其在推动AI技术发展和现实世界应用中的潜力。
V-IRL平台的核心架构和组件
在V-IRL系统中,智能体的行为由用户定义的元数据塑造,包括背景、目标意图和内感受状态。背景提供了将智能体实例化到真实世界的必要上下文,包括地理位置和生活经历。意图描述了智能体在环境中的目的,而内感受状态反映了智能体随时间变化的内部心理和物理状态,这对于与人类的协作至关重要。智能体通过编写特定任务的run()例程来开发,这些例程利用平台的各种组件和智能体的元数据来解决问题。
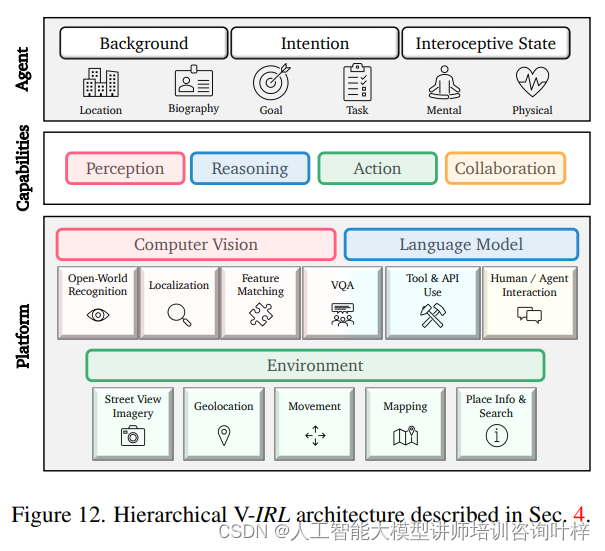
Figure 12 展示了 V-IRL 的分层架构,这是系统基础部分(Section 4)的一个关键组成部分。这个架构图详细描述了 V-IRL 平台是如何构建的,以及智能体是如何利用这个平台来执行任务的。分层架构的核心组成:
平台(Platform)
平台是V-IRL架构的基石,提供了智能体运行所需的基础设施。这些基础设施包括但不限于:
-
数据访问:提供对地理空间数据和街景图像的访问,这些数据构成了智能体与真实世界交互的基础。
-
API集成:允许智能体利用第三方API,如Google Maps Platform,来增强其功能。
-
任务执行:提供执行各种任务所需的工具和接口,例如路径规划和导航。
环境(Environment, ENV)
环境组件确保智能体能够在现实世界中有准确的定位和感知。它的功能包括:
-
地图表示:提供对城市地图的虚拟表示,使智能体能够在地图上进行导航和路径规划。
-
街景图像:允许智能体访问特定地理位置的360度全景图像,增强其对环境的视觉感知。
-
地理定位:使智能体能够确定自己在现实世界中的位置,并据此做出决策。
-
移动查询:提供智能体查询可行路径和导航点的能力。
视觉(Vision, CV)
视觉组件赋予智能体处理视觉信息的能力,使它们能够理解和解释视觉数据:
-
对象检测:识别和定位图像中的对象,如垃圾箱、消防栓等。
-
特征匹配:在不同视角下识别和匹配相同的对象,避免重复计数。
-
视觉问答(VQA):智能体能够回答关于视觉场景的问题,例如“这个地方可以做什么?”。
语言(Language, LM)
语言组件通过集成大型语言模型(LLMs),增强了智能体的交流和推理能力:
-
复杂推理:智能体能够进行复杂的逻辑推理和问题解决。
-
规划:智能体能够制定计划和策略来达成目标。
-
自然语言交流:智能体能够使用自然语言与人类或其他智能体交流。
行动(Action)
行动组件涉及智能体在虚拟环境中的实际移动和交互:
-
导航:智能体能够在环境中自主导航,到达指定位置。
-
路径规划:智能体能够规划从起点到终点的最优路径。
-
任务执行:智能体能够执行定义好的任务,如探索、搜索或数据收集。
协作(Collaboration, COL)
协作组件允许智能体与其他智能体或人类合作,共同完成任务:
-
多智能体协作:智能体能够与其他智能体共享信息和资源,协同工作。
-
人机交互:智能体能够理解人类用户的指令,并与之合作解决问题。
-
任务分解:在复杂任务中,智能体能够将任务分解为更小的子任务,并与其他智能体协作完成。
这些组件共同构成了V-IRL架构的核心,使得智能体能够在模拟真实世界的虚拟环境中执行复杂的任务,同时与人类用户和其他智能体进行有效互动。通过这种分层和模块化的设计,V-IRL平台不仅提供了灵活性和可扩展性,而且也促进了智能体技术的创新和发展。
V-IRL平台的组件可以灵活组合,展现出广泛的能力。作者通过创建展示日益复杂行为的智能体,每个智能体都需要更多平台组件的支持,从而展示了系统的多功能性和潜力。
作者还介绍了Diego这一高级智能体的设计和功能。Diego是一个交互式礼宾智能体。他在制定行程方面的熟练程度背后,是他的迭代规划流程。这个过程从Diego使用GPT-4创建第一个活动的初步计划开始,考虑到用户的传记、要求和工作记忆中的先前活动。这个草案经过精心的细化,包括层次协调模块检索真实的交通时间,请求推荐代理提供餐饮建议,以及内感受估计模块评估建议活动对用户心理/物理状态和预算的影响。关键的最后一步涉及监管模块,根据当前用户状态、剩余预算和潜在交互审查即将进行的活动。如果监管认为计划不合适,它将启动修订。修订后的计划然后返回到层次协调器和内感受估计器进行可靠性检查,然后再次由监管审查。这种层次协调器、内感受估计器和监管之间的迭代过程一直持续,直到监管批准活动并将其添加到其工作记忆中。
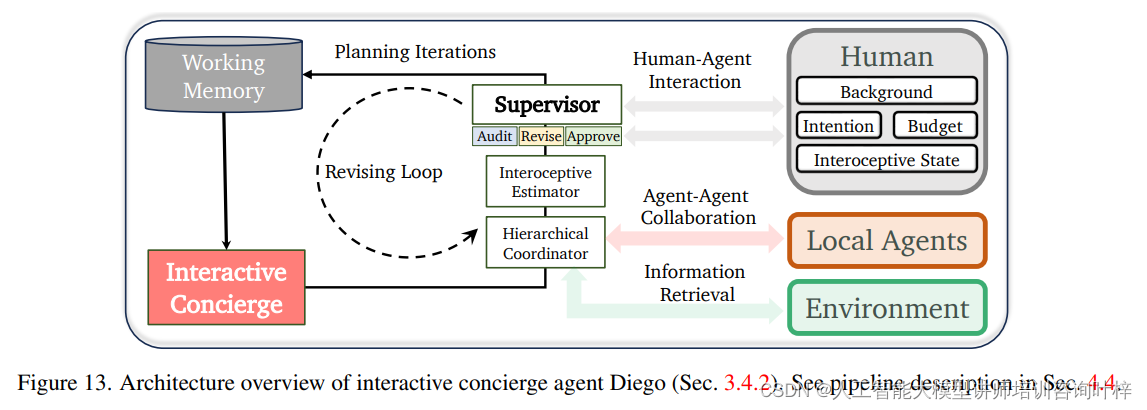
图13在论文中提供了对交互式礼宾智能体Diego的架构概览。这个架构图详细展示了Diego是如何通过不同的模块和组件来实现其功能的:
-
工作记忆(Working Memory):这是Diego用来存储用户信息、行程草稿和之前活动中的信息的地方。工作记忆对于Diego在规划过程中的信息整合和决策至关重要。
-
本地代理(Local Agents):这些代理为Diego提供本地化的服务和信息,比如交通时间、地点推荐等。它们帮助Diego更好地理解和适应用户所在的地理位置。
-
修订循环(Revising Loop):Diego的规划流程是迭代的。如果监管模块认为某个活动不适合用户,它会返回到层次协调模块和内感受估计模块进行重新评估和修订。这个循环确保了行程的持续优化。
-
层次协调器(Hierarchical Coordinator):这个模块负责协调Diego的高层规划任务,如获取交通时间、请求餐饮建议等。它在规划过程中起到了协调不同任务和活动的作用。
-
内感受估计器(Interoceptive Estimator):该模块评估提议的活动对用户心理和身体状态的影响,确保Diego的推荐符合用户的实时需求和能力。
-
监管模块(Supervisor):这是Diego架构中的决策中心,负责审查活动是否适合用户的状态、预算和潜在的交互。如果活动不合适,监管模块会启动修订循环。
-
规划迭代(Planning Iterations):Diego的规划流程是分阶段进行的,每个阶段都可能涉及对先前决策的重新评估和修订。
-
环境(Environment)、语言模型(Language Model, LM)、计算机视觉(Computer Vision, CV)、协作(Collaboration, COL):这些组件为Diego提供了感知、推理、视觉识别和协作的能力,使其能够与用户和环境进行有效的交互。
-
用户干预(Human Intervention):用户可以直接干预Diego的规划过程,通过调整自己的状态或提供反馈来影响最终的行程安排。
评估测试
为了使V-IRL基准测试能够在全球范围内扩展,作者开发了一个自动化的数据和注释构建流程,而不是依赖于有限数据的手动爬行和注释。这一流程允许模型在全球范围内方便地进行测试,只要它们能够访问Google街景数据。
-
区域选择:尽管基准测试在Google地图平台覆盖的所有区域都是可行的,但作者选择了跨越6个大洲、12个城市的14个区域,以确保数据分布的多样性,同时保持推理成本的可承受性。
-
地点类型:在每个区域,作者收集了Google地图平台注释的所有96个地点类型的地点信息。这些地点类型构成了V-IRL地点定位、识别和视觉问题回答(VQA)基准测试的基础。
-
视觉和地点数据收集:在每个区域内,作者收集了具有可用街景图像、地点信息和以地点为中心的图像的地理位置。
-
数据清洗:尽管自动化数据收集具有可扩展性,但由于缺乏人工监督,可能会引入噪声。为此,作者设计了三种自动数据清洗策略:基于距离的过滤、人工审查过滤和基于CLIP的过滤,以确保数据的质量和相关性。

这一基准测试评估视觉模型在日常人类活动中使用街景图像和相关地点数据进行地点定位的表现。作者修改了RX-399智能体,让它在穿越多边形区域的同时定位和识别20种类型的地点。
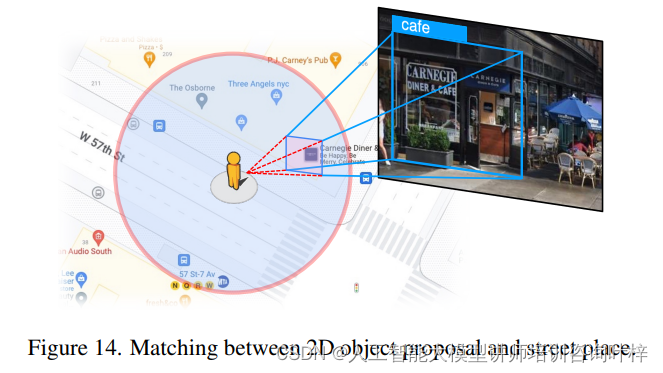
-
设置:作者从14个区域中抽取了28个多边形区域进行测试。
-
基准模型:评估了三种主要的开放世界检测模型:GroundingDINO、GLIP和Owl-ViT,以及一个简单的基线模型,即CLIP(使用GLIP提议)。
-
评估:基于定位召回率对模型进行评估,召回率定义为正确定位地点和错过地点的数量之比。

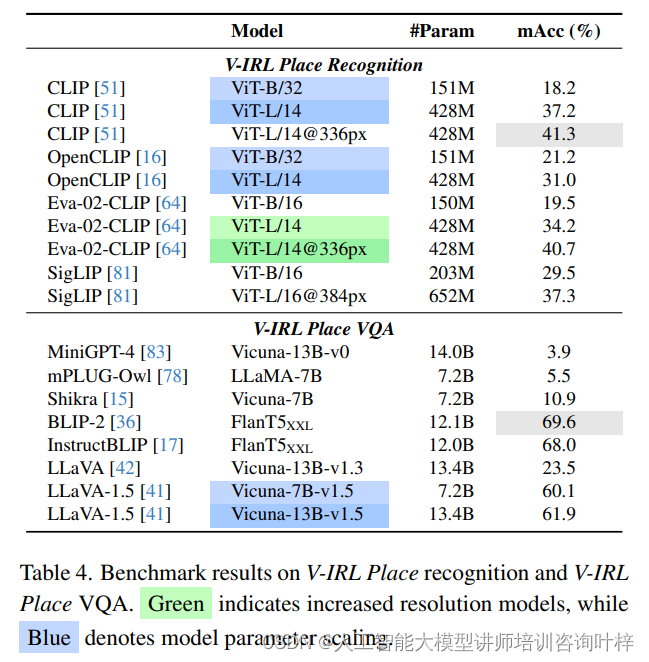
与仅使用街景图像的具有挑战性的V-IRL地点定位任务不同,在现实生活中,人们可以通过更近距离、以地点为中心的观察来识别商家。作者基于以地点为中心的图像评估现有视觉模型在两项感知任务上的表现:识别特定地点类型和通过视觉问题回答识别人类意图。
-
设置:对于识别任务,作者评估了10种开放世界识别模型,使用以地点为中心的图像来识别地点类型。对于意图VQA,作者评估了8种多模态大型语言模型(MMLLM),以确定可行的人类意图。
-
评估:采用平均准确率(mAcc)来评估地点识别和VQA任务的表现。
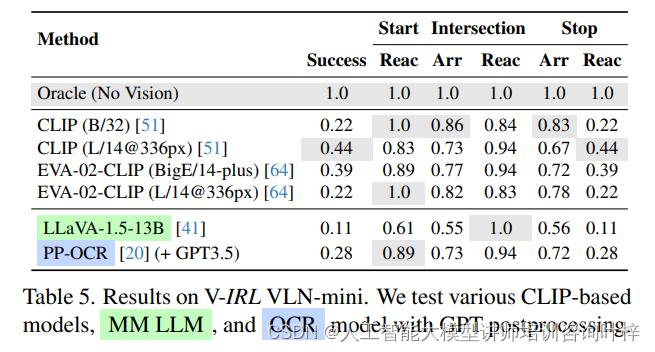
这一基准测试开发了一个集成任务,联合测试视觉和语言模型:视觉-语言导航(VLN)。在VLN中,智能体需要通过遵循文本指令使用原始街景图像导航到目的地。
-
设置:采用了上面案例中的旅游者实现,并将其识别组件替换为各种基准测试模型,这些模型用于在导航过程中识别视觉地标。
-
评估方法:评估了四种方法在导航过程中识别地标的表现,包括使用Google地图平台(GMP)的Oracle方法、零样本识别器CLIP和EVA-CLIP、多模态大型语言模型LLaVA-1.5,以及PP-OCR模型结合GPT后处理。
-
评估:主要衡量导航成功率,定义为导航者在目的地25米内停止即为成功。此外,还评估了关键位置(起点、交叉口和停止点)的到达比率(Arr)和反应准确性(Reac)。
跨越全球12个城市的V-IRL基准测试分析了不同地区固有的模型偏差。显示在拉各斯、东京、香港和布宜诺斯艾利斯等城市,视觉模型在所有三个基准任务中的表现都不佳。这表明现有的视觉模型可能在非英语主导的国家部署时面临挑战。尽管如此,V-IRL平台的提出,为AI智能体的研究和开发提供了新的视角和工具。随着空间计算和机器人技术的不断进步,对能够理解真实世界的AI智能体的需求将日益增长。
论文地址:https://arxiv.org/abs/2402.03310
项目地址:https://github.com/VIRL-Platform/VIRL















 2601
2601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









