









在看源码前最好看下
模式识别与机器学习 (Bishop) 暂无中文版
这本书的第9章,有详细的公式推导,斯坦福大学公开课NG的课件,可以两者结合看(Bishop的书和NG的课)
NG的课件翻译版本(EM课件) http://blog.csdn.net/yeyang911/article/details/28095153
源码解读:主要是E-step和M-step
EM算法的这种思想是值得借鉴的
EM算法的简单例子http://www.cnblogs.com/zhangchaoyang/articles/2623364.html
E-step 源码:
void EM::eStep()
{
// Compute probs_ik from means_k, covs_k and weights_k.
trainProbs.create(trainSamples.rows, nclusters, CV_64FC1);
//概率矩阵(样本个数,聚类个数,数据类型)
trainLabels.create(trainSamples.rows, 1, CV_32SC1);
//标签向量(样本个数,1,数据类型)
trainLogLikelihoods.create(trainSamples.rows, 1, CV_64FC1);
//log后的似然(样本个数,1,数据类型)
computeLogWeightDivDet(); //计算 LogWeightDivDet
CV_DbgAssert(trainSamples.type() == CV_64FC1); //数据类型检测
CV_DbgAssert(means.type() == CV_64FC1); //数据类型检测
for(int sampleIndex = 0; sampleIndex < trainSamples.rows; sampleIndex++)
{
Mat sampleProbs = trainProbs.row(sampleIndex);
Vec2d res = computeProbabilities(trainSamples.row(sampleIndex), &sampleProbs);
//计算概率
trainLogLikelihoods.at<double>(sampleIndex) = res[0];
trainLabels.at<int>(sampleIndex) = static_cast<int>(res[1]);
}
}
其中涉及了 computeLogWeightDivDet() computeProbabilities() 两个函数
computeLogWeightDivDet():
void EM::computeLogWeightDivDet()//计算log 的权值
{
CV_Assert(!covsEigenValues.empty());
Mat logWeights;
cv::max(weights, DBL_MIN, weights);//防止数据过小
log(weights, logWeights); //weights(聚类的数据占样本总数的的比例)转到log
logWeightDivDet.create(1, nclusters, CV_64FC1);
// note: logWeightDivDet = log(weight_k) - 0.5 * log(|det(cov_k)|)
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
double logDetCov = 0.;
const int evalCount = static_cast<int>(covsEigenValues[clusterIndex].total()); //有多少特征值
for(int di = 0; di < evalCount; di++)
logDetCov += std::log(covsEigenValues[clusterIndex].at<double>(covMatType != EM::COV_MAT_SPHERICAL ? di : 0));
// logDetCov为Cov的值的和的log
logWeightDivDet.at<double>(clusterIndex) = logWeights.at<double>(clusterIndex) - 0.5 * logDetCov;
// logWeightDivDet 意味着 logWeight div(-) det(Sum(logcov))
}
}computeProbabilities() :
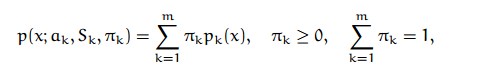
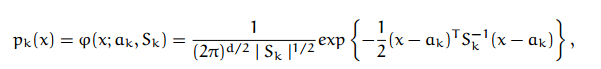
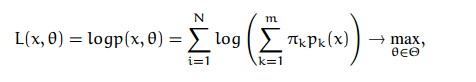
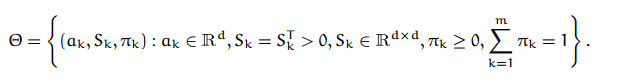
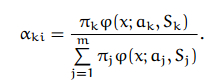
注意上面的公式,转换到log后,相乘除的变为相加减
Vec2d EM::computeProbabilities(const Mat& sample, Mat* probs) const
{
// L_ik = log(weight_k) - 0.5 * log(|det(cov_k)|) - 0.5 *(x_i - mean_k)' cov_k^(-1) (x_i - mean_k)]
// q = arg(max_k(L_ik))
// probs_ik = exp(L_ik - L_iq) / (1 + sum_j!=q (exp(L_ij - L_iq))
// see Alex Smola's blog http://blog.smola.org/page/2 for
// details on the log-sum-exp trick
CV_Assert(!means.empty());
CV_Assert(sample.type() == CV_64FC1);
CV_Assert(sample.rows == 1);
CV_Assert(sample.cols == means.cols);
int dim = sample.cols;
Mat L(1, nclusters, CV_64FC1); //L 1*nclusters
int label = 0;
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
const Mat centeredSample = sample - means.row(clusterIndex); //减去均值
Mat rotatedCenteredSample = covMatType != EM::COV_MAT_GENERIC ?
centeredSample : centeredSample * covsRotateMats[clusterIndex];
double Lval = 0;
for(int di = 0; di < dim; di++)
{
double w = invCovsEigenValues[clusterIndex].at<double>(covMatType != EM::COV_MAT_SPHERICAL ? di : 0);
//对角线上的值或者每行第一个值
double val = rotatedCenteredSample.at<double>(di);
Lval += w * val * val;//方差乘以权值 协方差矩阵的倒数的平方
}
CV_DbgAssert(!logWeightDivDet.empty());
L.at<double>(clusterIndex) = logWeightDivDet.at<double>(clusterIndex) - 0.5 * Lval;
// note: logWeightDivDet = log(weight_k) - 0.5 * log(|det(cov_k)|)
// note: L.at<double>(clusterIndex) = log(weight_k) - 0.5 * log(|det(cov_k)|)-0.5 * Lval
if(L.at<double>(clusterIndex) > L.at<double>(label))
label = clusterIndex; //求似然最大的label值
}
double maxLVal = L.at<double>(label); //
Mat expL_Lmax = L; // exp(L_ij - L_iq) //L 1*nclusters
for(int i = 0; i < L.cols; i++)
expL_Lmax.at<double>(i) = std::exp(L.at<double>(i) - maxLVal);
double expDiffSum = sum(expL_Lmax)[0]; // sum_j(exp(L_ij - L_iq))
if(probs) //probs
{
probs->create(1, nclusters, CV_64FC1);
double factor = 1./expDiffSum;
expL_Lmax *= factor;
expL_Lmax.copyTo(*probs);
}
Vec2d res;
res[0] = std::log(expDiffSum) + maxLVal - 0.5 * dim * CV_LOG2PI; //dim样本维数 CV_LOG2PI (1.8378770664093454835606594728112)
//
res[1] = label;
return res;
}

M-step:
void EM::mStep()
{
// Update means_k, covs_k and weights_k from probs_ik
int dim = trainSamples.cols;
// Update weights
// not normalized first
reduce(trainProbs, weights, 0, CV_REDUCE_SUM); //计算每列的概率和
/*
cvReduce( const CvArr* src, CvArr* dst, int dim, int op=CV_REDUCE_SUM);
src
输入矩阵
dst
输出的通过处理输入矩阵的所有行/列而得到的单行/列向量
dim
矩阵被简化后的维数索引.0意味着矩阵被处理成一行,1意味着矩阵被处理成为一列,-1时维数将根据输出向量的大小自动选择.
op
简化操作的方式,可以有以下几种取值:
CV_REDUCE_SUM-输出是矩阵的所有行/列的和.
CV_REDUCE_AVG-输出是矩阵的所有行/列的平均向量.
CV_REDUCE_MAX-输出是矩阵的所有行/列的最大值.
CV_REDUCE_MIN-输出是矩阵的所有行/列的最小值.
*/
// Update means
means.create(nclusters, dim, CV_64FC1);
means = Scalar(0);
const double minPosWeight = trainSamples.rows * DBL_EPSILON; //小概率
double minWeight = DBL_MAX;
int minWeightClusterIndex = -1;
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
if(weights.at<double>(clusterIndex) <= minPosWeight)
//概率过小跳过
continue;
if(weights.at<double>(clusterIndex) < minWeight)//求最小概率值
{
minWeight = weights.at<double>(clusterIndex);
minWeightClusterIndex = clusterIndex;//得到聚类索引值
}
Mat clusterMean = means.row(clusterIndex);
for(int sampleIndex = 0; sampleIndex < trainSamples.rows; sampleIndex++)
clusterMean += trainProbs.at<double>(sampleIndex, clusterIndex) * trainSamples.row(sampleIndex);
clusterMean /= weights.at<double>(clusterIndex);
}
// Update covsEigenValues and invCovsEigenValues
covs.resize(nclusters);
covsEigenValues.resize(nclusters);
if(covMatType == EM::COV_MAT_GENERIC)
covsRotateMats.resize(nclusters);
invCovsEigenValues.resize(nclusters);
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
if(weights.at<double>(clusterIndex) <= minPosWeight)
//概率过小跳过
continue;
if(covMatType != EM::COV_MAT_SPHERICAL)
covsEigenValues[clusterIndex].create(1, dim, CV_64FC1);
else
covsEigenValues[clusterIndex].create(1, 1, CV_64FC1);
if(covMatType == EM::COV_MAT_GENERIC)
covs[clusterIndex].create(dim, dim, CV_64FC1);
Mat clusterCov = covMatType != EM::COV_MAT_GENERIC ?
covsEigenValues[clusterIndex] : covs[clusterIndex];
clusterCov = Scalar(0);
Mat centeredSample;
for(int sampleIndex = 0; sampleIndex < trainSamples.rows; sampleIndex++)
{
centeredSample = trainSamples.row(sampleIndex) - means.row(clusterIndex);
//centeredSample = 样本值-平均值的差值 //向量
获取带概率的协方差矩阵--begin
if(covMatType == EM::COV_MAT_GENERIC)
clusterCov += trainProbs.at<double>(sampleIndex, clusterIndex) * centeredSample.t() * centeredSample;
else
{
double p = trainProbs.at<double>(sampleIndex, clusterIndex);
for(int di = 0; di < dim; di++ )
{
double val = centeredSample.at<double>(di);
clusterCov.at<double>(covMatType != EM::COV_MAT_SPHERICAL ? di : 0) += p*val*val;
}
}
/获取带概率的协方差矩阵--end///
}
if(covMatType == EM::COV_MAT_SPHERICAL)
clusterCov /= dim;
clusterCov /= weights.at<double>(clusterIndex);
// Update covsRotateMats for EM::COV_MAT_GENERIC only
if(covMatType == EM::COV_MAT_GENERIC)
{
SVD svd(covs[clusterIndex], SVD::MODIFY_A + SVD::FULL_UV);
covsEigenValues[clusterIndex] = svd.w; //特征值矩阵
covsRotateMats[clusterIndex] = svd.u; //旋转矩阵
}
max(covsEigenValues[clusterIndex], minEigenValue, covsEigenValues[clusterIndex]);
//minEigenValue 正数最小值 略大于0
// update invCovsEigenValues
invCovsEigenValues[clusterIndex] = 1./covsEigenValues[clusterIndex];
//取矩阵的倒数
}
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
if(weights.at<double>(clusterIndex) <= minPosWeight)
{
Mat clusterMean = means.row(clusterIndex);
means.row(minWeightClusterIndex).copyTo(clusterMean);//更新最小权值的均值赋与均值
covs[minWeightClusterIndex].copyTo(covs[clusterIndex]);//更新最小权值的Covs
covsEigenValues[minWeightClusterIndex].copyTo(covsEigenValues[clusterIndex]);//更新最小权值的CovsEigenValues
if(covMatType == EM::COV_MAT_GENERIC)//只有 COV_MAT_GENERIC 更新旋转矩阵
covsRotateMats[minWeightClusterIndex].copyTo(covsRotateMats[clusterIndex]);
invCovsEigenValues[minWeightClusterIndex].copyTo(invCovsEigenValues[clusterIndex]);//更新最小权值的invCovsEigenValues
}
}
// Normalize weights
weights /= trainSamples.rows;
}
下面是全部源码:
/*M///
//
// IMPORTANT: READ BEFORE DOWNLOADING, COPYING, INSTALLING OR USING.
//
// By downloading, copying, installing or using the software you agree to this license.
// If you do not agree to this license, do not download, install,
// copy or use the software.
//
//
// Intel License Agreement
// For Open Source Computer Vision Library
//
// Copyright( C) 2000, Intel Corporation, all rights reserved.
// Third party copyrights are property of their respective owners.
//
// Redistribution and use in source and binary forms, with or without modification,
// are permitted provided that the following conditions are met:
//
// * Redistribution's of source code must retain the above copyright notice,
// this list of conditions and the following disclaimer.
//
// * Redistribution's in binary form must reproduce the above copyright notice,
// this list of conditions and the following disclaimer in the documentation
// and/or other materials provided with the distribution.
//
// * The name of Intel Corporation may not be used to endorse or promote products
// derived from this software without specific prior written permission.
//
// This software is provided by the copyright holders and contributors "as is" and
// any express or implied warranties, including, but not limited to, the implied
// warranties of merchantability and fitness for a particular purpose are disclaimed.
// In no event shall the Intel Corporation or contributors be liable for any direct,
// indirect, incidental, special, exemplary, or consequential damages
//(including, but not limited to, procurement of substitute goods or services;
// loss of use, data, or profits; or business interruption) however caused
// and on any theory of liability, whether in contract, strict liability,
// or tort(including negligence or otherwise) arising in any way out of
// the use of this software, even ifadvised of the possibility of such damage.
//
//M*/
#include "precomp.hpp"
namespace cv
{
const double minEigenValue = DBL_EPSILON;
///
EM::EM(int _nclusters, int _covMatType, const TermCriteria& _termCrit)
{
nclusters = _nclusters;
covMatType = _covMatType;
maxIters = (_termCrit.type & TermCriteria::MAX_ITER) ? _termCrit.maxCount : DEFAULT_MAX_ITERS;
epsilon = (_termCrit.type & TermCriteria::EPS) ? _termCrit.epsilon : 0;
}
EM::~EM()
{
//clear();
}
void EM::clear()
{
trainSamples.release();
trainProbs.release();
trainLogLikelihoods.release();
trainLabels.release();
weights.release();
means.release();
covs.clear();
covsEigenValues.clear();
invCovsEigenValues.clear();
covsRotateMats.clear();
logWeightDivDet.release();
}
bool EM::train(InputArray samples,
OutputArray logLikelihoods,
OutputArray labels,
OutputArray probs)
{
Mat samplesMat = samples.getMat();
setTrainData(START_AUTO_STEP, samplesMat, 0, 0, 0, 0); //1.设置训练数据
return doTrain(START_AUTO_STEP, logLikelihoods, labels, probs); //训练
}
bool EM::trainE(InputArray samples,
InputArray _means0,
InputArray _covs0,
InputArray _weights0,
OutputArray logLikelihoods,
OutputArray labels,
OutputArray probs)
{
Mat samplesMat = samples.getMat();
std::vector<Mat> covs0;
_covs0.getMatVector(covs0);
Mat means0 = _means0.getMat(), weights0 = _weights0.getMat();
setTrainData(START_E_STEP, samplesMat, 0, !_means0.empty() ? &means0 : 0,
!_covs0.empty() ? &covs0 : 0, !_weights0.empty() ? &weights0 : 0);
return doTrain(START_E_STEP, logLikelihoods, labels, probs);
}
bool EM::trainM(InputArray samples,
InputArray _probs0,
OutputArray logLikelihoods,
OutputArray labels,
OutputArray probs)
{
Mat samplesMat = samples.getMat();
Mat probs0 = _probs0.getMat();
setTrainData(START_M_STEP, samplesMat, !_probs0.empty() ? &probs0 : 0, 0, 0, 0);
return doTrain(START_M_STEP, logLikelihoods, labels, probs);
}
Vec2d EM::predict(InputArray _sample, OutputArray _probs) const
{
Mat sample = _sample.getMat();
CV_Assert(isTrained());
CV_Assert(!sample.empty());
if(sample.type() != CV_64FC1)
{
Mat tmp;
sample.convertTo(tmp, CV_64FC1);
sample = tmp;
}
sample.reshape(1, 1);
Mat probs;
if( _probs.needed() )
{
_probs.create(1, nclusters, CV_64FC1);
probs = _probs.getMat();
}
return computeProbabilities(sample, !probs.empty() ? &probs : 0);
}
bool EM::isTrained() const
{
return !means.empty();
}
static
void checkTrainData(int startStep, const Mat& samples,
int nclusters, int covMatType, const Mat* probs, const Mat* means,
const std::vector<Mat>* covs, const Mat* weights)
{
// Check samples.
CV_Assert(!samples.empty()); //训练样本不为空
CV_Assert(samples.channels() == 1); //训练样本是否为单通道数据
int nsamples = samples.rows;//按照行排列数据 ,一行一个数据
int dim = samples.cols;
// Check training params.
CV_Assert(nclusters > 0);
CV_Assert(nclusters <= nsamples);
CV_Assert(startStep == EM::START_AUTO_STEP ||
startStep == EM::START_E_STEP ||
startStep == EM::START_M_STEP);
CV_Assert(covMatType == EM::COV_MAT_GENERIC ||
covMatType == EM::COV_MAT_DIAGONAL ||
covMatType == EM::COV_MAT_SPHERICAL);
CV_Assert(!probs ||
(!probs->empty() &&
probs->rows == nsamples && probs->cols == nclusters &&
(probs->type() == CV_32FC1 || probs->type() == CV_64FC1)));
CV_Assert(!weights ||
(!weights->empty() &&
(weights->cols == 1 || weights->rows == 1) && static_cast<int>(weights->total()) == nclusters &&
(weights->type() == CV_32FC1 || weights->type() == CV_64FC1)));
CV_Assert(!means ||
(!means->empty() &&
means->rows == nclusters && means->cols == dim &&
means->channels() == 1));
CV_Assert(!covs ||
(!covs->empty() &&
static_cast<int>(covs->size()) == nclusters));
if(covs)
{
const Size covSize(dim, dim);
for(size_t i = 0; i < covs->size(); i++)
{
const Mat& m = (*covs)[i];
CV_Assert(!m.empty() && m.size() == covSize && (m.channels() == 1));
}
}
if(startStep == EM::START_E_STEP)
{
CV_Assert(means);
}
else if(startStep == EM::START_M_STEP)
{
CV_Assert(probs);
}
}
static
void preprocessSampleData(const Mat& src, Mat& dst, int dstType, bool isAlwaysClone) //转变类型
{
if(src.type() == dstType && !isAlwaysClone)
dst = src;
else
src.convertTo(dst, dstType);
}
static
void preprocessProbability(Mat& probs) //得到各个样本的概率
{
max(probs, 0., probs); //保证probs大于等于0
const double uniformProbability = (double)(1./probs.cols);
for(int y = 0; y < probs.rows; y++)
{
Mat sampleProbs = probs.row(y);
double maxVal = 0;
minMaxLoc(sampleProbs, 0, &maxVal); //获取每行的最大值
if(maxVal < FLT_EPSILON)
sampleProbs.setTo(uniformProbability); //小于FLOAT 最小值 就置为 uniformProbability 的值
else
normalize(sampleProbs, sampleProbs, 1, 0, NORM_L1); //NORM_L1 各个样本在总样本的概率
}
}
void EM::setTrainData(int startStep, const Mat& samples,
const Mat* probs0,
const Mat* means0,
const std::vector<Mat>* covs0,
const Mat* weights0)
{
clear();
checkTrainData(startStep, samples, nclusters, covMatType, probs0, means0, covs0, weights0); //1(1)检查训练数据
bool isKMeansInit = (startStep == EM::START_AUTO_STEP) || (startStep == EM::START_E_STEP && (covs0 == 0 || weights0 == 0));
//是否为Kmeans初始化的数据
// Set checked data
preprocessSampleData(samples, trainSamples, isKMeansInit ? CV_32FC1 : CV_64FC1, false);
//根据isKMeansInit 选择输出的数据类型
// set probs
if(probs0 && startStep == EM::START_M_STEP)
{
preprocessSampleData(*probs0, trainProbs, CV_64FC1, true); //数据类型转换
preprocessProbability(trainProbs);//获取样本的概率
}
// set weights
if(weights0 && (startStep == EM::START_E_STEP && covs0))
{
weights0->convertTo(weights, CV_64FC1);
weights.reshape(1,1);
preprocessProbability(weights);//获取样本权值
}
// set means EM::START_E_STEP
//You need to provide means a_k of mixture components to use this option.
//Optionally you can pass weights pi_k and covariance matrices S_k of mixture components
if(means0 && (startStep == EM::START_E_STEP/* || startStep == EM::START_AUTO_STEP*/))
means0->convertTo(means, isKMeansInit ? CV_32FC1 : CV_64FC1); //设置数据格式
// set covs
if(covs0 && (startStep == EM::START_E_STEP && weights0))
{
covs.resize(nclusters);
for(size_t i = 0; i < covs0->size(); i++)
(*covs0)[i].convertTo(covs[i], CV_64FC1); //设置数据格式
}
}
void EM::decomposeCovs() //分解
{
CV_Assert(!covs.empty());
covsEigenValues.resize(nclusters); //特征值
if(covMatType == EM::COV_MAT_GENERIC)
covsRotateMats.resize(nclusters); //旋转矩阵
invCovsEigenValues.resize(nclusters);
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
CV_Assert(!covs[clusterIndex].empty());
SVD svd(covs[clusterIndex], SVD::MODIFY_A + SVD::FULL_UV); //对covs[clusterIndex]SVD分解
//SVD::MODIFY_A use the algorithm to modify the decomposed matrix; it can save space
//and speed up processing.
//SVD::NO_UV indicates that only a vector of singular values w is to be processed, while
//u and vt will be set to empty matrices.
//SVD::FULL_UV when the matrix is not square, by default the algorithm produces u
//and vt matrices of sufficiently large size for the further A reconstruction; if, however,
//FULL_UV flag is specified, u and vt will be full-size square orthogonal matrices.
if(covMatType == EM::COV_MAT_SPHERICAL)
{
double maxSingularVal = svd.w.at<double>(0);
covsEigenValues[clusterIndex] = Mat(1, 1, CV_64FC1, Scalar(maxSingularVal));
}
else if(covMatType == EM::COV_MAT_DIAGONAL)
{
covsEigenValues[clusterIndex] = svd.w; //U W V_t V为转置的
}
else //EM::COV_MAT_GENERIC
{
covsEigenValues[clusterIndex] = svd.w; //得到W= 特征值矩阵
covsRotateMats[clusterIndex] = svd.u; //得到U= 旋转矩阵
}
max(covsEigenValues[clusterIndex], minEigenValue, covsEigenValues[clusterIndex]);
//minEigenValue为double 正数最小值 略大于0
invCovsEigenValues[clusterIndex] = 1./covsEigenValues[clusterIndex];
//取倒数
}
}
void EM::clusterTrainSamples()//用Kmeans进行聚类
{
int nsamples = trainSamples.rows;
// Cluster samples, compute/update means
// Convert samples and means to 32F, because kmeans requires this type.
Mat trainSamplesFlt, meansFlt;
if(trainSamples.type() != CV_32FC1)
trainSamples.convertTo(trainSamplesFlt, CV_32FC1);
else
trainSamplesFlt = trainSamples;
if(!means.empty())
{
if(means.type() != CV_32FC1)
means.convertTo(meansFlt, CV_32FC1);
else
meansFlt = means;
}
Mat labels;
//Kmeans 只接受32FC1数据类型
kmeans(trainSamplesFlt, nclusters, labels, TermCriteria(TermCriteria::COUNT, means.empty() ? 10 : 1, 0.5), 10, KMEANS_PP_CENTERS, meansFlt);
// Convert samples and means back to 64F.
CV_Assert(meansFlt.type() == CV_32FC1);
if(trainSamples.type() != CV_64FC1)
{
Mat trainSamplesBuffer;
trainSamplesFlt.convertTo(trainSamplesBuffer, CV_64FC1);
trainSamples = trainSamplesBuffer;
}
meansFlt.convertTo(means, CV_64FC1); //变回64FC1
// Compute weights and covs
weights = Mat(1, nclusters, CV_64FC1, Scalar(0));
covs.resize(nclusters);
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
Mat clusterSamples;
for(int sampleIndex = 0; sampleIndex < nsamples; sampleIndex++) //按照标签顺序加入数据
{
if(labels.at<int>(sampleIndex) == clusterIndex)
{
const Mat sample = trainSamples.row(sampleIndex);
clusterSamples.push_back(sample); // 按照标签顺序加入数据
}
}
CV_Assert(!clusterSamples.empty());
//计算相关矩阵
calcCovarMatrix(clusterSamples, covs[clusterIndex], means.row(clusterIndex), //计算相关矩阵
CV_COVAR_NORMAL + CV_COVAR_ROWS + CV_COVAR_USE_AVG + CV_COVAR_SCALE, CV_64FC1);
weights.at<double>(clusterIndex) = static_cast<double>(clusterSamples.rows)/static_cast<double>(nsamples);
//计算权值 -- 占样本总数的的比例
}
decomposeCovs();
}
void EM::computeLogWeightDivDet()//计算log 的权值
{
CV_Assert(!covsEigenValues.empty());
Mat logWeights;
cv::max(weights, DBL_MIN, weights);//防止数据过小
log(weights, logWeights); //weights(聚类的数据占样本总数的的比例)转到log
logWeightDivDet.create(1, nclusters, CV_64FC1);
// note: logWeightDivDet = log(weight_k) - 0.5 * log(|det(cov_k)|)
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
double logDetCov = 0.;
const int evalCount = static_cast<int>(covsEigenValues[clusterIndex].total()); //有多少特征值
for(int di = 0; di < evalCount; di++)
logDetCov += std::log(covsEigenValues[clusterIndex].at<double>(covMatType != EM::COV_MAT_SPHERICAL ? di : 0));
// logDetCov为Cov的值的和的log
logWeightDivDet.at<double>(clusterIndex) = logWeights.at<double>(clusterIndex) - 0.5 * logDetCov;
// logWeightDivDet 意味着 logWeight div(-) det(Sum(logcov))
}
}
bool EM::doTrain(int startStep, OutputArray logLikelihoods, OutputArray labels, OutputArray probs)
{
int dim = trainSamples.cols; //dim 样本的特征维数
// Precompute the empty initial train data in the cases of EM::START_E_STEP and START_AUTO_STEP
if(startStep != EM::START_M_STEP)
{
if(covs.empty())
{
CV_Assert(weights.empty());
clusterTrainSamples(); //用Kmeans聚类
}
}
if(!covs.empty() && covsEigenValues.empty() )
{
CV_Assert(invCovsEigenValues.empty());
decomposeCovs(); //得到特征值矩阵
}
if(startStep == EM::START_M_STEP) //You need to provide initial probabilities p_i;k to use this option.
mStep(); //M-Step
double trainLogLikelihood, prevTrainLogLikelihood = 0.;
for(int iter = 0; ; iter++)
{
eStep(); //E-Step
trainLogLikelihood = sum(trainLogLikelihoods)[0];
if(iter >= maxIters - 1)
break; // 大于迭代次数
double trainLogLikelihoodDelta = trainLogLikelihood - prevTrainLogLikelihood;
if( iter != 0 &&
(trainLogLikelihoodDelta < -DBL_EPSILON ||
trainLogLikelihoodDelta < epsilon * std::fabs(trainLogLikelihood))) //终止条件
break;
mStep(); //M-Step
prevTrainLogLikelihood = trainLogLikelihood;
}
if( trainLogLikelihood <= -DBL_MAX/10000. )
{
clear();
return false;
}
// postprocess covs
covs.resize(nclusters);
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
if(covMatType == EM::COV_MAT_SPHERICAL)
{
covs[clusterIndex].create(dim, dim, CV_64FC1);
setIdentity(covs[clusterIndex], Scalar(covsEigenValues[clusterIndex].at<double>(0)));
}
else if(covMatType == EM::COV_MAT_DIAGONAL)
{
covs[clusterIndex] = Mat::diag(covsEigenValues[clusterIndex]);
}
}
if(labels.needed())
trainLabels.copyTo(labels);
if(probs.needed())
trainProbs.copyTo(probs);
if(logLikelihoods.needed())
trainLogLikelihoods.copyTo(logLikelihoods);
trainSamples.release();
trainProbs.release();
trainLabels.release();
trainLogLikelihoods.release();
return true;
}
Vec2d EM::computeProbabilities(const Mat& sample, Mat* probs) const
{
// L_ik = log(weight_k) - 0.5 * log(|det(cov_k)|) - 0.5 *(x_i - mean_k)' cov_k^(-1) (x_i - mean_k)]
// q = arg(max_k(L_ik))
// probs_ik = exp(L_ik - L_iq) / (1 + sum_j!=q (exp(L_ij - L_iq))
// see Alex Smola's blog http://blog.smola.org/page/2 for
// details on the log-sum-exp trick
CV_Assert(!means.empty());
CV_Assert(sample.type() == CV_64FC1);
CV_Assert(sample.rows == 1);
CV_Assert(sample.cols == means.cols);
int dim = sample.cols;
Mat L(1, nclusters, CV_64FC1); //L 1*nclusters
int label = 0;
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
const Mat centeredSample = sample - means.row(clusterIndex); //减去均值
Mat rotatedCenteredSample = covMatType != EM::COV_MAT_GENERIC ?
centeredSample : centeredSample * covsRotateMats[clusterIndex];
double Lval = 0;
for(int di = 0; di < dim; di++)
{
double w = invCovsEigenValues[clusterIndex].at<double>(covMatType != EM::COV_MAT_SPHERICAL ? di : 0);
//对角线上的值或者每行第一个值
double val = rotatedCenteredSample.at<double>(di);
Lval += w * val * val;//方差乘以权值 协方差矩阵的倒数的平方
}
CV_DbgAssert(!logWeightDivDet.empty());
L.at<double>(clusterIndex) = logWeightDivDet.at<double>(clusterIndex) - 0.5 * Lval;
// note: logWeightDivDet = log(weight_k) - 0.5 * log(|det(cov_k)|)
// note: L.at<double>(clusterIndex) = log(weight_k) - 0.5 * log(|det(cov_k)|)-0.5 * Lval
if(L.at<double>(clusterIndex) > L.at<double>(label))
label = clusterIndex; //求最大label值
}
double maxLVal = L.at<double>(label); //
Mat expL_Lmax = L; // exp(L_ij - L_iq) //L 1*nclusters
for(int i = 0; i < L.cols; i++)
expL_Lmax.at<double>(i) = std::exp(L.at<double>(i) - maxLVal);
double expDiffSum = sum(expL_Lmax)[0]; // sum_j(exp(L_ij - L_iq))
if(probs) //probs
{
probs->create(1, nclusters, CV_64FC1);
double factor = 1./expDiffSum;
expL_Lmax *= factor;
expL_Lmax.copyTo(*probs);
}
Vec2d res;
res[0] = std::log(expDiffSum) + maxLVal - 0.5 * dim * CV_LOG2PI; //dim样本维数 CV_LOG2PI (1.8378770664093454835606594728112)
//
res[1] = label;
return res;
}
void EM::eStep()
{
// Compute probs_ik from means_k, covs_k and weights_k.
trainProbs.create(trainSamples.rows, nclusters, CV_64FC1);
//概率矩阵(样本个数,聚类个数,数据类型)
trainLabels.create(trainSamples.rows, 1, CV_32SC1);
//标签向量(样本个数,1,数据类型)
trainLogLikelihoods.create(trainSamples.rows, 1, CV_64FC1);
//log后的似然(样本个数,1,数据类型)
computeLogWeightDivDet(); //计算 LogWeightDivDet
CV_DbgAssert(trainSamples.type() == CV_64FC1); //数据类型检测
CV_DbgAssert(means.type() == CV_64FC1); //数据类型检测
for(int sampleIndex = 0; sampleIndex < trainSamples.rows; sampleIndex++)
{
Mat sampleProbs = trainProbs.row(sampleIndex);
Vec2d res = computeProbabilities(trainSamples.row(sampleIndex), &sampleProbs);
//计算概率
trainLogLikelihoods.at<double>(sampleIndex) = res[0];
trainLabels.at<int>(sampleIndex) = static_cast<int>(res[1]);
}
}
void EM::mStep()
{
// Update means_k, covs_k and weights_k from probs_ik
int dim = trainSamples.cols;
// Update weights
// not normalized first
reduce(trainProbs, weights, 0, CV_REDUCE_SUM); //计算每列的概率和
/*
cvReduce( const CvArr* src, CvArr* dst, int dim, int op=CV_REDUCE_SUM);
src
输入矩阵
dst
输出的通过处理输入矩阵的所有行/列而得到的单行/列向量
dim
矩阵被简化后的维数索引.0意味着矩阵被处理成一行,1意味着矩阵被处理成为一列,-1时维数将根据输出向量的大小自动选择.
op
简化操作的方式,可以有以下几种取值:
CV_REDUCE_SUM-输出是矩阵的所有行/列的和.
CV_REDUCE_AVG-输出是矩阵的所有行/列的平均向量.
CV_REDUCE_MAX-输出是矩阵的所有行/列的最大值.
CV_REDUCE_MIN-输出是矩阵的所有行/列的最小值.
*/
// Update means
means.create(nclusters, dim, CV_64FC1);
means = Scalar(0);
const double minPosWeight = trainSamples.rows * DBL_EPSILON; //小概率
double minWeight = DBL_MAX;
int minWeightClusterIndex = -1;
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
if(weights.at<double>(clusterIndex) <= minPosWeight)
//概率过小跳过
continue;
if(weights.at<double>(clusterIndex) < minWeight)//求最小概率值
{
minWeight = weights.at<double>(clusterIndex);
minWeightClusterIndex = clusterIndex;//得到聚类索引值
}
Mat clusterMean = means.row(clusterIndex);
for(int sampleIndex = 0; sampleIndex < trainSamples.rows; sampleIndex++)
clusterMean += trainProbs.at<double>(sampleIndex, clusterIndex) * trainSamples.row(sampleIndex);
clusterMean /= weights.at<double>(clusterIndex);
}
// Update covsEigenValues and invCovsEigenValues
covs.resize(nclusters);
covsEigenValues.resize(nclusters);
if(covMatType == EM::COV_MAT_GENERIC)
covsRotateMats.resize(nclusters);
invCovsEigenValues.resize(nclusters);
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
if(weights.at<double>(clusterIndex) <= minPosWeight)
//概率过小跳过
continue;
if(covMatType != EM::COV_MAT_SPHERICAL)
covsEigenValues[clusterIndex].create(1, dim, CV_64FC1);
else
covsEigenValues[clusterIndex].create(1, 1, CV_64FC1);
if(covMatType == EM::COV_MAT_GENERIC)
covs[clusterIndex].create(dim, dim, CV_64FC1);
Mat clusterCov = covMatType != EM::COV_MAT_GENERIC ?
covsEigenValues[clusterIndex] : covs[clusterIndex];
clusterCov = Scalar(0);
Mat centeredSample;
for(int sampleIndex = 0; sampleIndex < trainSamples.rows; sampleIndex++)
{
centeredSample = trainSamples.row(sampleIndex) - means.row(clusterIndex);
//centeredSample = 样本值-平均值的差值 //向量
获取带概率的协方差矩阵--begin
if(covMatType == EM::COV_MAT_GENERIC)
clusterCov += trainProbs.at<double>(sampleIndex, clusterIndex) * centeredSample.t() * centeredSample;
else
{
double p = trainProbs.at<double>(sampleIndex, clusterIndex);
for(int di = 0; di < dim; di++ )
{
double val = centeredSample.at<double>(di);
clusterCov.at<double>(covMatType != EM::COV_MAT_SPHERICAL ? di : 0) += p*val*val;
}
}
/获取带概率的协方差矩阵--end///
}
if(covMatType == EM::COV_MAT_SPHERICAL)
clusterCov /= dim;
clusterCov /= weights.at<double>(clusterIndex);
// Update covsRotateMats for EM::COV_MAT_GENERIC only
if(covMatType == EM::COV_MAT_GENERIC)
{
SVD svd(covs[clusterIndex], SVD::MODIFY_A + SVD::FULL_UV);
covsEigenValues[clusterIndex] = svd.w; //特征值矩阵
covsRotateMats[clusterIndex] = svd.u; //旋转矩阵
}
max(covsEigenValues[clusterIndex], minEigenValue, covsEigenValues[clusterIndex]);
//minEigenValue 正数最小值 略大于0
// update invCovsEigenValues
invCovsEigenValues[clusterIndex] = 1./covsEigenValues[clusterIndex];
//取矩阵的倒数
}
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
if(weights.at<double>(clusterIndex) <= minPosWeight)
{
Mat clusterMean = means.row(clusterIndex);
means.row(minWeightClusterIndex).copyTo(clusterMean);//更新最小权值的均值赋与均值
covs[minWeightClusterIndex].copyTo(covs[clusterIndex]);//更新最小权值的Covs
covsEigenValues[minWeightClusterIndex].copyTo(covsEigenValues[clusterIndex]);//更新最小权值的CovsEigenValues
if(covMatType == EM::COV_MAT_GENERIC)//只有 COV_MAT_GENERIC 更新旋转矩阵
covsRotateMats[minWeightClusterIndex].copyTo(covsRotateMats[clusterIndex]);
invCovsEigenValues[minWeightClusterIndex].copyTo(invCovsEigenValues[clusterIndex]);//更新最小权值的invCovsEigenValues
}
}
// Normalize weights
weights /= trainSamples.rows;
}
void EM::read(const FileNode& fn)
{
Algorithm::read(fn);
decomposeCovs();
computeLogWeightDivDet();
}
} // namespace cv
/* End of file. */















 1392
1392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









