







文章转自公众号老刘说NLP
先看一个有趣的话题。特定大模型的输出是有一个「信息量」的上限的,即使输出的token可以很长,但是其包含的信息量并没有本质差异,只不过是车轱辘话来回说罢了,或者就是一些无关痛痒的话来填充,信息密度实际上是下降的。
这是一个很有趣的额问题,我们可以从PPL、词汇丰富度、主题数来看,也有社区朋友说,可以适用信息熵来做,但这个其实是用来衡量不确定性的,所以大家如何看这个事情呢?
今天,我们来看看几个问题。一个是工业大模型行业落地的三个观点,讲的还不错。
另一个关于视频理解多模态进展综述,对于理解多模态视频这块的技术、实现范式和数据有帮助。
一、关于工业大模型行业落地的三个观点
最近看到一个很不错的工业大模型行业报告,2024年中国工业大模型行业发展研究报告:https://www.idigital.com.cn/report/4385?type=0,其中有个三个观点,总结的比较好,供大家一起参考。
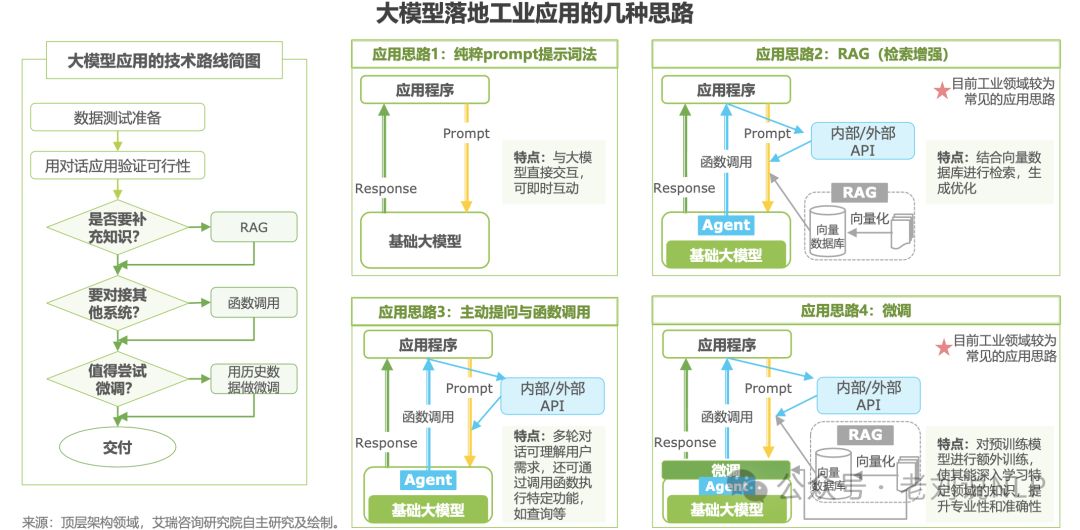
观点1:大模型落地工业应用的几种思路
纯粹prompt提示词法、RAG(检索增强)、主动提问与函数调用、微调四种思路,其中RAG和微调为目前工业领域较为常见的应用思路
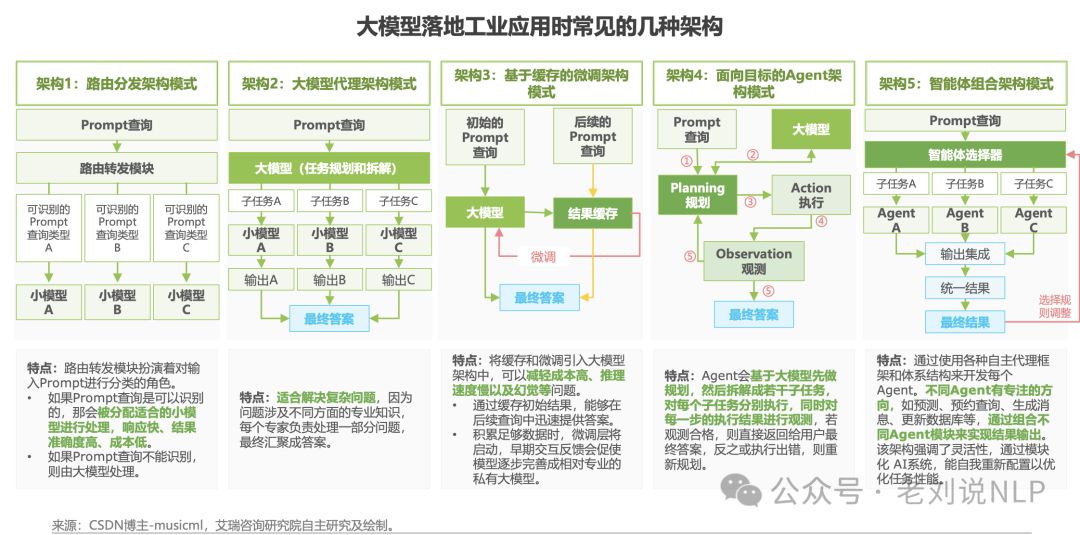
观点2:大模型落地工业应用时常见的几种架构
关于大模型落地工业应用时候,常见的可以分为以下几种架构:
路由分发架构模式、大模型代理架构模式、基于缓存的微调架构模式、面向目标的Agent架构模式、智能体组合架构模式架构,每个具体步骤和优缺点如下:
观点3:关于大模型和小模型的差别
在进行工业应用时,大小模型各有所长,其能力都不可忽视,当前也不存在谁替代谁的情况。
大模型落地工业应用时,主要依托于强大的生成能力和针对复杂信息的捕捉与构建能力,因此在知识问答、文本/图片生成等以创造见长的场景应用比较多。

而小模型则凭借高性价比、预测结果相对准确等优势,在工业质检、设备维护等场景高度成熟。
二、关于视频理解多模态进展综述
最近的工作《From Seconds to Hours: Reviewing MultiModal Large Language Models on Comprehensive Long Video Understanding》(https://arxiv.org/abs/2409.18938),这个工作综述长视频理解任务,重点分析其独特挑战并总结模型与训练技术进展,我们可以看看。
可以看看几个核心的点:
1、视频理解大模型的演化

2、图像-、短视频-和长视频-多模态大型语言模型(MM-LLMs)之间的比较

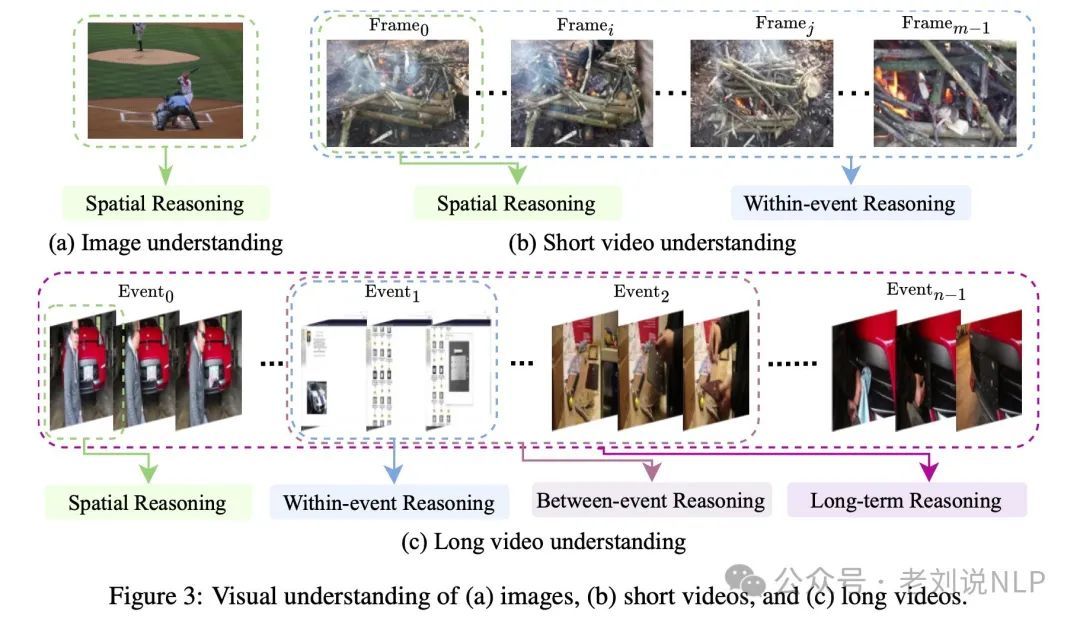
3、图像、短视频和长视频的视觉理解流程
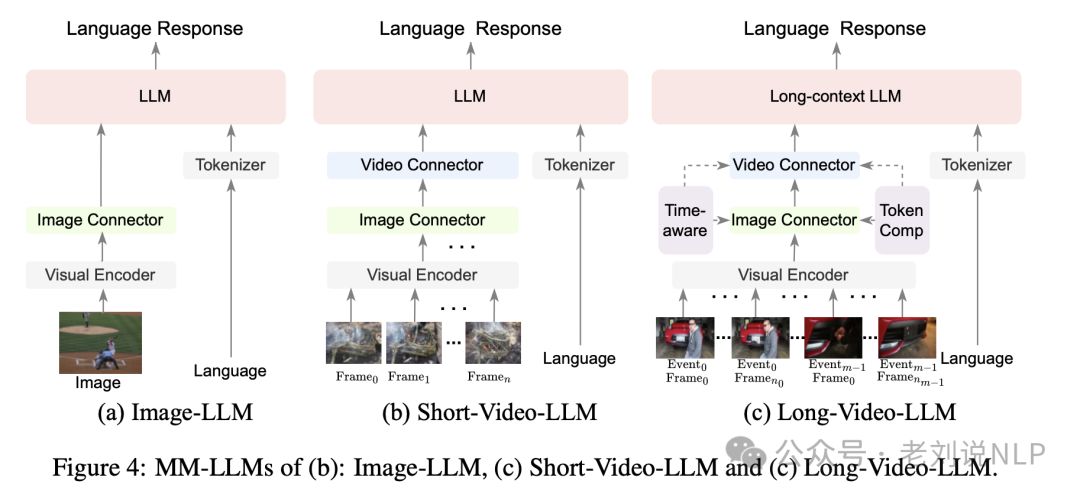
4、图像、短视频和长视频的视觉理解的多模态模型
5、主流训练范式和代表模型对比

"PT" 和 "IT" 分别代表模型训练过程中的预训练和指令调整两个阶段。字母 "Y"(是)和 "N"(否)表示在这些阶段是否使用了图像、短视频和长视频语言数据集。"E2E" 代表端到端的训练流程。
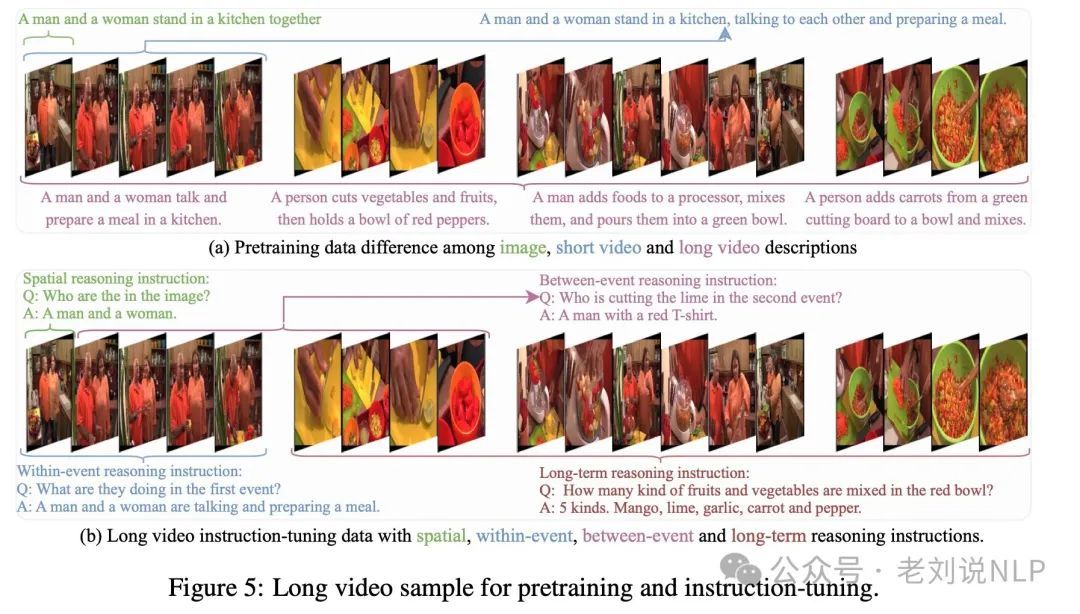
6、Long video长视频的预训练阶段和微调阶段的数据样本
参考文献
1、https://www.idigital.com.cn/report/4385?type=0
2、https://arxiv.org/abs/2409.18938

















 4526
4526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









