







Action recognition using ensemble of deep convolutional neural networks
Deep convolutional neural networks (DCNN) 用在video上,
通过视频帧间的时间信息(如光流、光流的梯度信息和图像的梯度信息),来区分不同的动作。
光流的maps作为DCNN的输入。
Large-scale video classification with convolutional neural networks
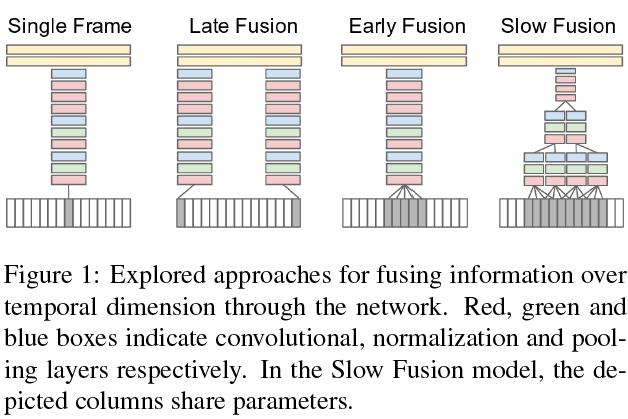
Extend the connectivity of CNN in time domain to take advantage of local spatio-temporal information.
What temporal connectivity pattern in a CNN architecture is best at using local motion information of the video?
为了加速,把CNN架构氛围两个过程来处理:
(1)a context stream that learns features on low-resolution frames
(2)a high-resolution fovea stream that only operates on the middle portion of the frame.
每一个视频看做a bag of short, fixed-sized clips....
Extend the connectivity of the network in time dimension to learn spatio-temporal features
可以总结为一下三种情况:
3D CNN (3D convolutional neural networks for human action recognition)
















 2158
2158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









