






RITnet眼睛注视跟踪的实时语义分割
本文的主要贡献如下
1 提出了RITnet,一种语义分割结构,模型大小只有0.98MB,在2019年OpenEDS语义分割挑战赛上获得最先进的结果。该模型在NVIDIA 1080 ti GPU上以300 Hz的频率对640x400幅图像进行分割。
2 提出了特定领域的增强方案,它有助于在各种挑战条件下的泛化。
3 提出了边界感知损失函数和损失调度策略来训练深度语义分割模型。这有助于产生具有清晰区域边界的连贯区域。
提出的模型:RITnet
最近,基于完全卷积网络(FCN)的分割模型在许多数据集中表现良好。然而,这种成功往往是以计算复杂度为代价的,这限制了它们在实时应用中的可行性,快速计算和对光照条件的鲁棒性对实时应用是至关重要的。相比之下,RITnet有248,900个可训练参数,使用32位精度的存储空间少于1MB。
RITnet有五个down - block和四个up - block,分别对输入进行下采样和上采样。最后一个Down-Block也被称为瓶颈层,其将整体信息降低到大小为输入分辨率1 / 16的小张量(tensor)。每个Down-Block由5个具有LeakyReLU激活函数的卷积层组成。所有的卷积层共享以前的层的连接(all convolution layers share connections from previous layers),灵感来自DenseNet。我们保持恒定的通道(channel)大小, 比如K=32通道的DenseUNet-K[3]可以减少参数的数量。所有Down-Blocks后面都是大小为2*2的平均池化层。Up-Block使用最近邻方法将输入上采样两倍。每个Up-Block由4个具有LeakyReLU激活函数的卷积层组成。所有的Up-Block通过跳跃连接从它们相应的Down-Block接收额外的信息,这是一种有效的策略,为模型提供了不同空间粒度的表示。

图2. ritnet的架构细节。DB表示Down-Block, UB为Up-Block, BN为批归一化(batch normalization)。类似地,M是指输入通道的数量(用于灰度图像的M = 1),C是指输出标签的数量,P是指模型参数的数量。虚线表示来自相应Down-Blocks的跳过连接。所有块输出信道大小M = 32的张量(All of the Blocks output tensors of channel size m=32)。
损失函数
每个像素被分类为四个语义类别中的一个:背景,虹膜,巩膜、瞳孔。标准交叉熵损失(Standard cross-entropy loss:CEL)是具有均衡类分布应用的默认选择。然而,存在着以最少像素代表瞳孔区域的类的不平衡分布。虽然CEL旨在最大化像素位置的输出概率,但它对眼睛图像固有的结构无关。为了缓解这些问题,我们实施了以下损失函数:
Generalized Dice Loss (GDL):骰子评分系数(dice score coefficient)测量地面真实像素和预测值之间的重叠。在类别不平衡[11]的情况下,通过类频率的平方逆加权骰子评分[15]在与CEL结合时表现出提高的性能(In cases of class imbalance [11],weighting the dice score by the squared inverse of class frequency [15] showed increased performance when combined with CEL.)。
Boundary Aware Loss (BAL):基于类标签的语义边界单独区域(separate regions),根据每个像素到最近的两个区段的距离来加权每个像素的损失,引入边缘感知[14]。我们使用Canny边缘检测器产生边界像素,该Canny边缘检测器进一步扩张(dilated)两个像素以减少边界处的混淆。用这些边来掩盖CEL。
Surface Loss (SL): SL是基于图像轮廓(contours)空间中的距离度量,该度量保留了小的、不常见的具有高语义值的结构[8]。BAL试图最大化边界附近的正确像素概率,而GDL为不平衡条件提供稳定的梯度。与两者相反,SL根据每个类离ground truth边界的距离对每个像素处的损失进行缩放。它能有效地恢复被基于区域的损失[8]忽略的小区域。总损失L由这些损失的加权组合得到:
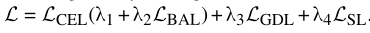
.数据集和评估
我们在OpenEDS语义分割数据集(OpenEDS Semantic Segmentation dataset)[4]上训练和评估我们的模型,OpenEDS语义分割数据集包含12,759张图像,分为训练(8,916)、验证(2,403)和测试(1440)的子集。每张图片都被手工标注了四个语义标签;背景、巩膜、瞳孔和虹膜。
根据OpenEDS挑战准则,总成绩指标使用所有类的均交并比(mIOU)的平均值,和根据可训练参数数量(以兆字节(MB)为单位)的函数计算的模型大小(S)。总分为:
数据预处理
为了适应个体反射性能的变化(例如,虹膜色素沉着,眼睛化妆,皮肤色调或眼睑/睫毛)[4]和HMD特定照明(红外LED相对于眼睛的位置),我们进行了两个预处理步骤。预处理减少了这些差异,也增加了某些眼睛特征的可分离性。首先,对所有输入图像应用指数为0.8的固定gamma校正。其次,我们应用了局部对比度极限自适应直方图均衡化(CLAHE),网格大小为8 × 8,限幅值为1.5[19](with a grid size of 8×8 and clip limit value of 1.5)。图3显示了预处理之前和之后的图像

图3.从左到右:原始图像,gamma校正后的图像,CLAHE应用后的图像。请注意,在最右边的图像中,虹膜和瞳孔比较容易区分。
为了增强模型对图像属性变化的鲁棒性,对训练数据进行了以下修改
•关于垂直轴的反射
•高斯模糊,固定内核大小为7x7和标准偏差2≤σ≤7。
•两个轴上的0-20像素的图像平移。
•使用围绕随机中心绘制的2-9条细线进行图像损坏(120 <x <280,192 <y <448)
•具有结构化的starburst(光芒四射的亮光)模式(图4)的图像损坏可减少由红外照明器(the IR illuminators)在眼镜上反射引起的分割误差。
每个图像在每个迭代接收到上述增强中的至少一个,概率为0.2。图像水平翻转的概率为0.5。

图4.从训练图像000000240768生成Starburst模式。左到右:原始图像,选择反射,连接其180◦旋转,最终模式掩模(最好的颜色查看)。
结果
我们将我们的结果与另一种完全卷积编码器-解码器架构SegNet[4]进行了比较。mSegNet指具有四层编码器和解码器的修改后的SegNet。mSegNet w/BR值具有边界改进作为残差结构的mSegNet,mSegNet w/SC是具有深度可分离卷积的轻量级mSegNet。

表1.OpenEDS数据集测试分割的性能比较
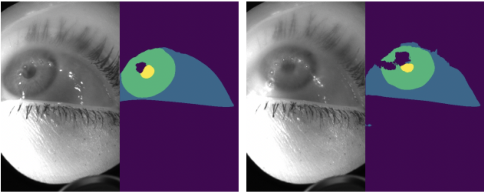
图5。当眼睛严重模糊或散焦时,我们的模型很难做到准确的分割。

图1.OpenEDS测试集中复杂样本的模型性能比较。上排从左至右显示因眼镜、浓睫毛膏、光线暗淡和部分眼睑闭锁而造成的眼部阻塞。从上到下的行分别显示输入的测试图像、地面真实标签、来自mSegNet w/BR[4]的预测和来自RITnet的预测。
然而,我们的模型的分割质量受到较高的运动模糊和图像散焦值的影响(图5),图1表明我们的模型推广到一些具有挑战性的情况,其中其他模型未能产生连贯的结果。















 1187
1187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









